图像生成算法评估指标
IS

P(y|x)分布越尖越好,说明他质量好,能够被模型很好的识别;P(y)表示生成n张图片的概率的均值,越平说明每个类别生成越平均,说明多样性好;IS越大说明这两个分布差别越大,则效果越好。
缺点:
1. 该模型是在Imagenet进行训练的,输出是1000类,对于其他数据集的区别,预测的分类准确率不一定靠谱(有些类别甚至都不在imagenet中);在使用的时候,最好在同个数据集训练分类模型,然后再使用这个分类模型;
2. 无法体现过拟合;
3. 模型更关注纹理,不关注形状;
FID
使用Inception模型的分别提取原始图片和生成图片的2048维特征的分布计算这两个分别的距离;FID越小,说明生成图片跟原始图片的特征差别越小,效果越好;
优点:使用的是特征提取器而不是分类器,特征更加鲁棒;
缺点:
1. 无法体现过拟合;
2. 模型更关注纹理,不关注形状;
CLIP Score
计算图片的特征跟文本特征的相关性;
优点:
1. 可以计算文本与图片的相关性;
2. 可以根据同一个prompt生成多个image,计算这些image之间的相似度来评估模型生成能力的多样性;
3. 可以计算生成图片的image embedding和原始图片的embedding的相关性来判断模型的保真度;
PIck Score
50个样本和5k个prompt,每一次生成两个图片,让用户选择哪一个更好;使用上述收集的数据训练clip的image encoder和text encoder,从而使得他们最终预测的结果跟用户打标的结果尽可能接近【KL散度】;
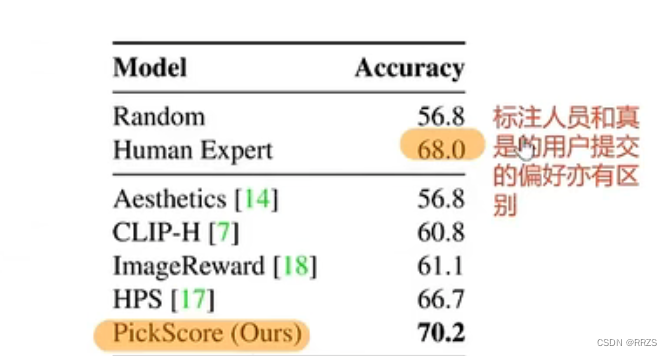
优点:能够真正反映人类的偏好;
缺点:需要人工打标;
HPS
一个文本对应4个图,用户pick1张,剩下的认为是不喜欢;
训练的方法参考对比学习,要求如果用户认为好的,那么文本和图片embedding的相似度高,否则相似度低;
作者还提出一种基于HPS去微调stable diffusion模型使得他更加符合人类的偏好;
1. 从diffusion DB(一个生成的数据集,作者会使用他前面训练好的HPS模型对其进行打分,并且选择分数高和分数低的数据分别作为用户喜欢和用户不喜欢的图片)和laion 5B(用于正则项);
2. 在用户不喜欢的图片对应的prompt前面加一个负向的标记符,其他的保持不变,然后训练一个lora模型,然后推理的时候将这个负向的标记符放到negative prompt中让模型避免生成该种类型的样本;
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- cesium粒子爆炸效果
- Linux网络带宽状态分析工具详解
- redis的那些事(二)——布隆过滤器
- Linux 服务器安全策略技巧:使用数字证书进行认证
- springcloud之Feign超时提示Read timed out executing POST
- 如何提高微信客户管理效率并增加转化率?
- 目标检测-One Stage-YOLOx
- 李宏毅LLM——ChatGPT原理剖析
- 在做题中学习(37):复写零
- 小样本学习系列工作(持续更新)