书生·浦语 LMDeploy 大模型量化部署原理
发布时间:2024年01月19日
大模型部署背景
模型部署
- 将训练好的模型在特定软硬件环境中启动的过程,使模型能够接收输入并返回预测结果
- 为了满足性能和效率的需求,常常需要对模型进行优化,如模型压缩和硬件加速
- 云端、边缘计算端、移动端部署
- 计算设备为CPU、GPU、NPU、TPU等
大模型的特点
- 内存开销巨大
- 参数量巨大
- 回归生成token,需要缓存Attention的k/v,带来巨大的内存消耗
- 动态shape,输入输出都是动态的
- 相对视觉模型,LLM结构简单
大模型部署的挑战
- 设备
- 如何应对巨大的存储问题?低存储设备如何部署?
- 推理
- 如何加速token的生成速度
- 如何解决动态shape,让推理可以不间断
- 如何有效管理和利用内存
- 服务
- 如何提升系统整体的吞吐量
- 对于个体用户,如何降低响应时间
大模型部署方案
- 技术点
- 模型并行
- 低比特量化
- Page Attention
- transformer 计算和访存优化
- Continuous Batch
- …
- 方案
- huggingface transformers
- 专门推理加速框架
- 云端
- imdeploy
- vllm
- tensorrt-llm
- deepspeed
- 移动端
- llama.cpp
- mlc-llm
- 云端
LMDeploy简介
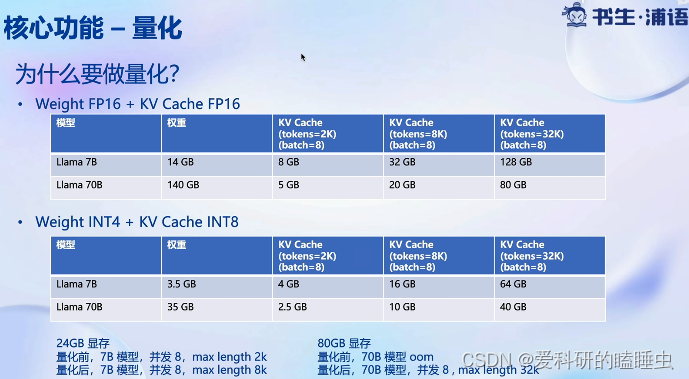
- 高效推理引擎,持续批量处理技巧,深度优化的低比特计算kernel,模型并行,高效的k/v缓存机制
- 完备易用的工具链,量化、推理、服务全流程,无缝对接OpenCompass评测推理精度,与OpenAI接口高度兼容



文章来源:https://blog.csdn.net/m0_49289284/article/details/135692284
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 使用Docker-Compose部署MySQL一主二从同步高可用MHA集群
- 【Bootstrap学习 day6】
- 【pytorch】使用pytorch构建线性回归模型-了解计算图和自动梯度
- CAD objectArx 在操作mfc时出现“不支持尝试执行的操作“
- Linux中CPU亲和性
- 介绍一下 MVC MVVM
- 推荐系统|2.4 矩阵分解的目的和效果
- 力扣(leetcode)第657题机器人能否返回顶点(Python)
- 【mars3d】TilesetLayer支持position位置偏移的前置说明
- 二重积分自变量的范围确定(两种方法)