激发大规模ClickHouse数据加载(2/3)大规模数据加载的加速调优

本文字数:4552;估计阅读时间:12?分钟
作者:Maksim Kita
审校:庄晓东(魏庄)
本文在公众号【ClickHouseInc】首发

Meetup活动:
ClickHouse Shenzhen User Group第1届 Meetup 火热报名中,详见文末!
进入赛道
在我们关于“激发大规模数据加载”三篇连载系列博客文章的第二篇中,我们将演示如何使用相同的硬件,在相同时间内运行“十亿行插入”大规模数加载场景,实现比默认设置快3倍的实验,将第一篇文章中的理论付诸实践(设置链接到第一篇)。我们将介绍一个公式,您可以使用该公式确定最适合您写入的业务场景:最佳块大小/并行度比。最后,我们将通过利用ClickHouse新的SharedMergeTree表引擎,以及简单的水平集群扩展,来突破数据加载速度极限。
请注意,我们仅在此演示了一种场景的调试,其中数据由ClickHouse服务器自己拉取。您可以在此处阅读有关客户端将数据推送到ClickHouse的设置的信息。(ClickHouse中的异步数据插入)
挑战
使用ClickHouse进行大规模数据加载就像驾驶一辆高性能的一级方程式赛车🏎?。我们可以获得巨大的原始马力,并且可以为大规模数据加载提供最高速度。但是,为了实现最大写入性能,您必须选择(1)足够高的档位【插入块大小】和(2)适当加速度【并行插入】,以及(3)可用到的马力(CPU核心和RAM)。
理想情况下,我们希望以最高档位和加速度驾驶我们的赛车:
-
最高档位:将插入块大小配置的越大,ClickHouse需要创建的部分(part)就越少,需要磁盘文件的I/O和后台的合并就越少。
-
最高加速度:将并行插入线程数量配置的越高,处理数据的速度就会越快。
然而,这两个性能因素之间存在着冲突和权衡(以及与后台part合并的权衡)。ClickHouse服务器的可用主存有限。较大的块使用更多的主内存,这限制了我们可以利用的并行插入线程的数量。相反,更高数量的并行插入线程需要更多的主存,因为插入线程的数量确定了内存中同时创建的插入块的数量。这限制了插入的块大小。此外,插入线程和后台合并线程之间可能存在资源争用。配置的插入线程数量较高(1)会创建需要合并的part较多,(2)会从后台合并线程中占用CPU核心和内存。
我们的挑战是:既要找到一个足够大的块大小,又要有足够多的并行插入线程的平衡点,以达到最佳的插入速度。
实验
在以下各节中,我们将对这些块大小/并行性设置进行测试,并评估它们对写入速度的影响。
测试数据
我们进行实验的数据来自PyPi数据集(存储在S3存储桶中)。它包含653亿行,未经压缩的原始大小约为14 TiB。将数据存储在ClickHouse表中时,磁盘上的压缩数据大小为约1.2 TiB。
测试表和插入查询
在这些测试中,我们将尽可能快地将此数据写入到ClickHouse服务的一个表中,该服务由3个ClickHouse服务器组成,每个服务器有59个CPU核心和236 GiB的RAM。我们将使用INSERT INTO SELECT查询,结合使用与S3Cluster集成表函数。
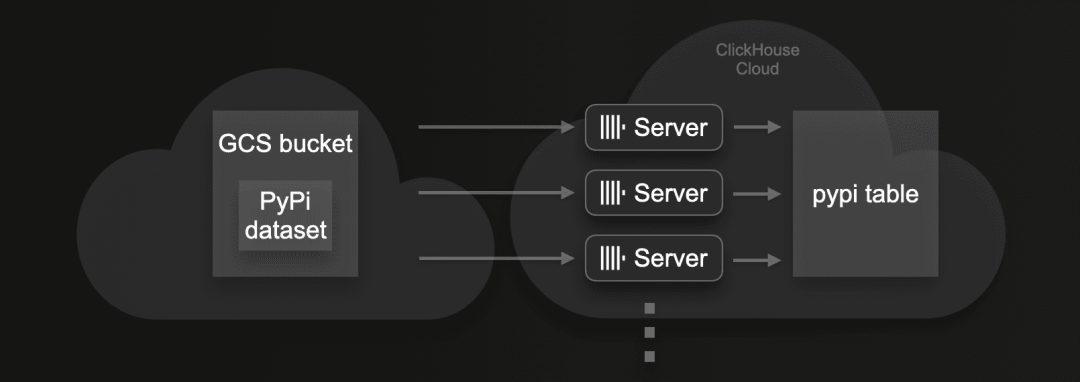
我们将从使用默认设置启动大规模数据加载,包括插入块大小和插入线程,然后将使用不同的数值组合重复相同数据的加载,以评估对加载时间的影响。
用于审视性能指标的查询
我们在系统表上使用以下SQL查询来审视和可视化--测试结果中的插入性能指标:
-
插入完成时的活动Part数量
-
达到少于3k活动Part的时间
-
写入存储的初始Part数
-
写入每个集群节点的初始Part数
换挡

为了说明插入块的大小如何影响到创建Part的数量(以及需要合并的Part数量),我们在下面的可视化中展示了各种插入块大小(以行为单位)与单个数据块的(未压缩)平均内存大小,以及单个数据Part的(压缩)平均磁盘上大小的关系。这与写入存储的平均总Part数量叠加在一起。请注意,我们给出平均值,因为如在第一篇文章中所述,由于ClickHouse按行块处理数据,创建的块和Part很少精确包含配置的行数或字节数。因此,这些设置指定最小阈值。
此外,请注意,我们从下一节,在不同的写入测试运行中获取这些数字。
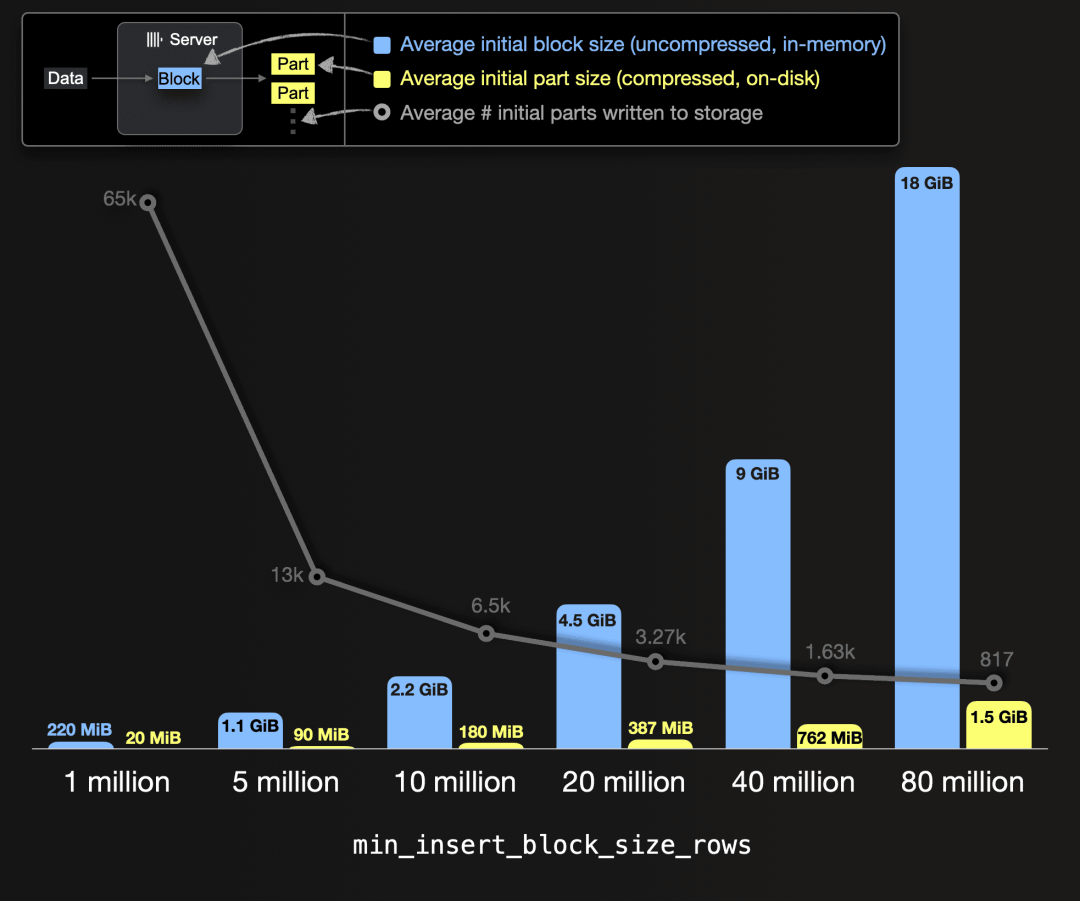
您可以看到,插入块大小配置的越大,存储测试数据(约1.2 TiB的压缩表数据)所需创建(和合并)的Part就越少。例如,使用100万行的插入块大小,将在磁盘上创建6.5万个初始Part(平均压缩大小为20 MiB)。而使用8000万行的插入块大小,只会创建817个初始Part(平均压缩大小为1.5 GiB)。
标准速度
以下图表可视化了使用默认插入块大小(约100万行),但不同的插入线程数量运行的写入测试结果。我们显示了峰值内存使用量,以及达到3000个Part(用于高效查询的建议数量)所需的时间:
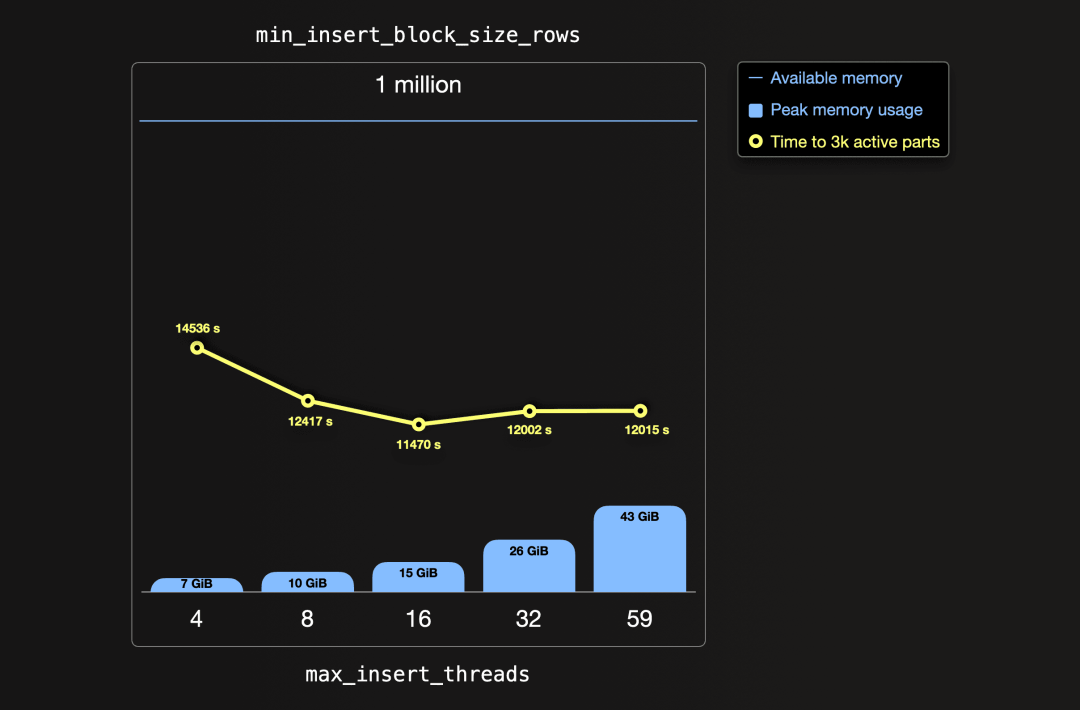
使用ClickHouse 默认设置的4个写入线程(OSS中默认没有开启并行协程线程),每个服务器消耗的主内存的峰值量为7 GiB。从写入开始到最初创建的6.5万个Part被合并为少于3千个Part,需要超过4个小时。通过其默认设置,ClickHouse试图提供资源使用的良好平衡,以支持来自并发用户的并发任务。然而,并非一刀切。我们在这里的目标是调整一个只被我们用于单一目的的专用服务:实现插入数据集的最高速度。
如果我们将利用的并行插入线程数量与可用的59个CPU核心的数量相匹配,与较低的线程设置相比,达到3k活动Part的时间会增加。
使用16个插入线程达到最短的时间,为后台合并线程留下了大量可用的59个CPU核心,这些线程与数据插入同时运行。
请注意上图中顶部的蓝色水平横线表示每个服务器的可用内存(236 GiB RAM)。我们可以看到增加插入块大小和内存使用(上图中的蓝色垂直条)的空间很大。
目前,我们正在全力以赴地踩油门(最多59个插入线程)以极低的档位(每个初始part仅有100万行),导致整体写入速度较慢。我们将在下一节中找到更好的档位和加速度组合。
最高速度

我们试图通过运行不同排列组合:分析这些写入测试插入速度的因素,来确定插入块大小和插入线程数的完美组合。以下图表可视化了这些写入测试运行的结果,我们多次将插入块大小翻倍(从100万到500万,再到1000万,再到2000万,最后到4000万,直至8000万):
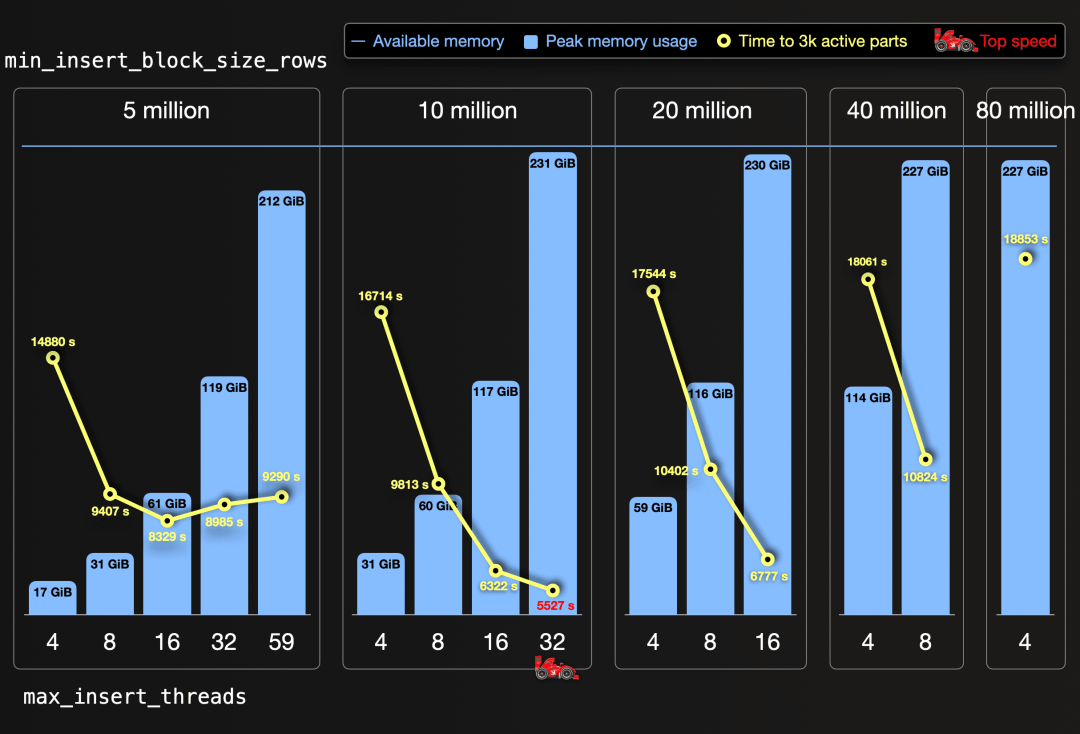
对于每个块大小,我们将插入线程数翻倍(从4开始),直到峰值内存使用量(蓝色垂直条)几乎达到每个服务器的可用内存(蓝色水平线)。黄色圆圈表示从开始写入到最初创建的所有 Part合并到少于3000个Part所需的时间。
当我们使用插入块大小为1000万行和32个并行插入线程时,我们达到了最高速度,成功写入了测试数据集的653亿行数据。这是我们服务器的甜蜜点(极点),测试服务器具有59个CPU核心和236 GiB RAM。这导致了一个适度数量的6.5千个初始Part,可以通过空闲的27个CPU核心(32个核心用于并行读取和写入数据)在后台快速合并到少于3000个Part。使用16个插入线程或更少的插入并行性将会太低。使用59个插入线程,1000万行块大小无法适配RAM。
500万行块大小可以使用59个插入线程。然而,它创建了13,000个初始Part,没有为高效的后台合并留下专用的CPU核心,导致资源争用和达到3,000个活动Part的时间较长。使用32和16个插入线程,数据处理速度较慢,但合并更快,因为有更多专用的CPU核心用于后台合并。4和8个插入线程不能使500万行块大小产生足够的插入并行性。
2000万行及以上的插入块大小会导致初始Part数量较低,但高内存开销限制了插入到创建不足的插入并行性的插入线程数量。
通过我们测定的甜蜜点设置,我们将写入速度提高了近3倍。我们使用完全相同的基础硬件,但我们更有效地利用了它进行数据写入,而不是通过一半的油门(32个插入线程)以最高可能档位(1000万行块大小)创建过多的初始Part。
一级方程式赛车
我们知道通过多次的测试运行,来测定大规模数十亿行级别的插入的完美设置是不切实际的。因此,我们为您提供了计算大数据负载最高速度的近似设置的方便公式:
??max_insert_threads:选择可用CPU核心的大约一半用于插入线程(以留出足够的专用核心用于后台合并)
??peak_memory_usage_in_bytes:选择预期的峰值内存使用量;可以是所有可用的RAM(如果它是隔离的写入),也可以是一半或更少(以留有其他并发任务的空间)
然后公式为:
min_insert_block_size_bytes?=?peak_memory_usage_in_bytes?/(?3 *?max_insert_threads)
通过这个公式,您可以将min_insert_block_size_rows设置为0(以禁用基于行的阈值),同时将max_insert_threads设置为选择的值,将min_insert_block_size_bytes设置为上述公式的计算结果。
在ClickHouse中突破速度限制

使写入速度更快的下一个措施是:为我们的引擎注入更多的动力,并通过添加额外的服务器分别增加可用的CPU核心数量。
与SharedMergeTree表引擎一起,ClickHouse允许您自由地(并快速!)改变:现有服务器的大小(CPU和RAM)或添加额外的服务器。我们在我们的服务中选择了后者,并使用不同数量的ClickHouse服务器(每个服务器有59个CPU核心和236 GB RAM)写入了我们的数据集。此图显示了结果:

对于每个写入测试运行,我们使用了上文中测定的最佳调整设置(32个并行插入线程,插入块大小为1000万行)。
我们可以看到,写入吞吐量与CPU核心和ClickHouse服务器的数量完美线性地扩展。这使我们能够以所需的速度运行大规模数据插入。
它可以像您想要的那样快
ClickHouse 允许您通过额外的CPU核心和服务器将写入持续时间线性扩展。因此,您可以按所需的速度运行大规模数据写入。以下图表可视化了这一点:
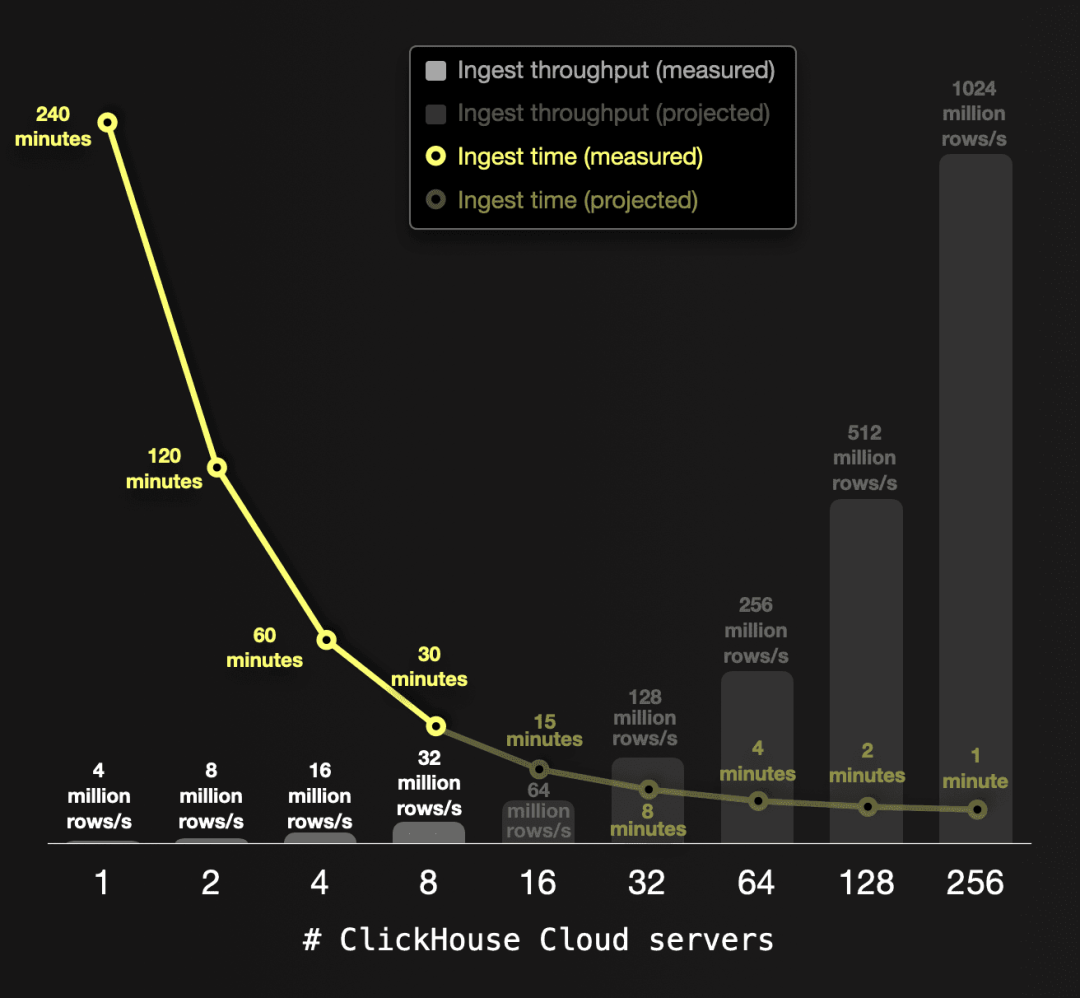
单个ClickHouse服务器(具有59个CPU核心和236 GB RAM)在约240分钟内以每秒约4百万行的速度写入了我们的650亿行数据集。基于我们上面的写入测试运行证明了可线性扩展性,我们展示了如何通过添加额外的服务器来改善吞吐量和写入时间。
总结
在我们的三部曲博客系列的第二部分中,我们提供了指导,并演示了如何调整插入性能的重要因素,从而大幅加快大规模数十亿行数据插入的速度。在相同的硬件上,最高的写入速度比默认设置快了近3倍。此外,我们利用了ClickHouse的无缝集群扩展,使写入速度更快,并说明了如何通过扩展节点来以所需的速度运行大规模数据插入。
我们希望您学到了一些新的方法来加速大规模ClickHouse数据的加载。
在这个系列的下一篇也是最后一篇文章中,我们将演示如何在较长时间内逐渐而可靠地加载大型数据集。
Meetup 活动报名通知
好消息:ClickHouse Shenzhen?User Group第1届 Meetup 已经开放报名了,将于2024年1月6日在深圳南山区海天二路33号腾讯滨海大厦举行,扫码免费报名


??联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!