数据操作——Column 对象
Column 对象
1. 什么是Column对象
- Column 表示了 Dataset 中的一个列, 并且可以持有一个表达式, 这个表达式作用于每一条数据, 对每条数据都生成一个值
2.Column对象如何创建
-
’
单引号 ’ 在 Scala 中是一个特殊的符号, 通过 ’ 会生成一个 Symbol 对象, Symbol 对象可以理解为是一个字符串的变种, 但是比字符串的效率高很多, 在 Spark 中, 对 Scala 中的 Symbol 对象做了隐式转换, 转换为一个 ColumnName 对象, ColumnName 是 Column 的子类, 所以在 Spark 中可以如下去选中一个列
val ds= Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS() // ' 必须导入spark的隐式转换才能使用 str.intern() val c1: Symbol = 'name -
$
同理, $ 符号也是一个隐式转换, 同样通过 spark.implicits 导入, 通过 $ 可以生成一个 Column 对象
val ds= Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS() // $ 必须导入spark的隐式转换才能使用 val column1: ColumnName = $"name" -
col
SparkSQL 提供了一系列的函数, 可以通过函数实现很多功能, 在后面课程中会进行详细介绍, 这些函数中有两个可以帮助我们创建 Column 对象, 一个是 col, 另外一个是 column
val ds= Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS()** **import org.apache.spark.sql.functions._ // col 必须导入 functions val column2: sql.Column = col("name") -
column
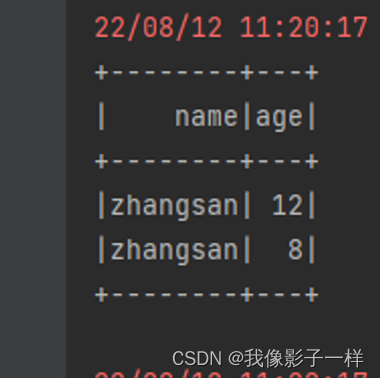
val ds= Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS() // column 必须导入 functions val column3: sql.Column = column("name") // 上面这四种创建方式,有关联的 Dataset 部分 ds.select(column).show() // Dataset 可以,DataFrame 可以使用 Column 对象选中行吗? df.select(column).show() // select 方法可以使用 column 对象来选中某个列,那么其他的算子行吗? df.where(column === "zhangsan").show() // coLumn有几个创建方式,四种 // column对象可以用作于 Dataset 和 DataFrame 中 // column可以和命令式的弱类型的 API 配合使用 select where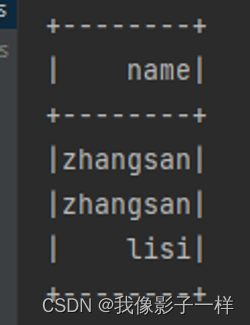
-
Dataset.col
前面的 Column 对象创建方式所创建的 Column 对象都是 Free 的, 也就是没有绑定任何 Dataset, 所以可以作用于任何 Dataset, 同时, 也可以通过 Dataset 的 col 方法选择一个列, 但是这个 Column 是绑定了这个 Dataset 的, 所以只能用于创建其的 Dataset 上
val ds: Dataset[Person] = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS() val ds1: Dataset[Person] = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS() // dataset.col //使用 dataset 来获取column 对象,会和某个 Dataset 进行绑定,在逻辑计划中,就会有不同的表现 val column4 = ds.col("name") val column5 = ds1.col("name") // ds.select(column5).show() 报错 // 为什么要和 dataset 来绑定呢 ds.join(ds1, ds.col("name") === ds1.col("name")) .select(column5).show() // 成功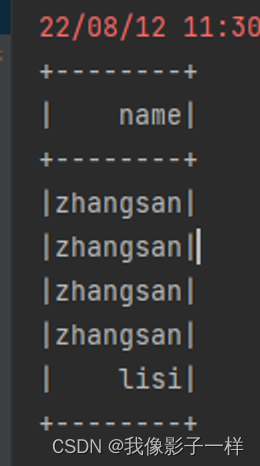
-
Dataset.apply
可以通过 Dataset 对象的 apply 方法来获取一个关联此 Dataset 的 Column 对象
ds(“name”)
ds.apply(“name”) 上下两个是一样的,ds(“name”)其实是ds.apply(“name”)简写版
val ds: Dataset[Person] = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS() val column6 = ds.apply("name") val column7 = ds(“name”)
3.别名和转换
-
as[type]
as 方法有两个用法, 通过 as[Type] 的形式可以将一个列中数据的类型转为 Type 类型
val ds: Dataset[Person] = Seq(Person("zhangsan", 12), Person("lisi", 15)).toDS() ds.select('age.as[Long]) -
as(name)
通过 as(name) 的形式使用 as 方法可以为列创建别名
@Test def as(): Unit = { val ds: Dataset[Person] = Seq(Person("zhangsan", 12), Person("lisi", 15)).toDS() // select name, count(age) as age from table group by name ds.select('name as 'new_name).show() }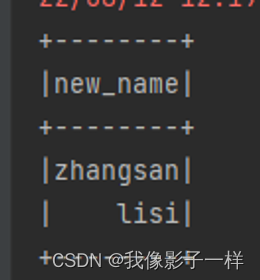
4.添加列
-
withColumn
通过 Column 在添加一个新的列时候修改 Column 所代表的列的数据
@Test def api(): Unit = { val ds:Dataset[Person]=Seq(Person("zhangsan",15),Person("lisi",10)).toDS() // 需求一,ds增加列,双倍年龄 // 'age*2 其实本质上就是将一个表达式(逻辑计划表达式)附着到column对象上 // 表达式在执行的时候对应每一条数据进行操作 ds.withColumn("doubled",'age * 2).show() }
5.操作
-
like
通过 Column 的 API, 可以轻松实现 SQL 语句中 LIKE 的模糊查询功能
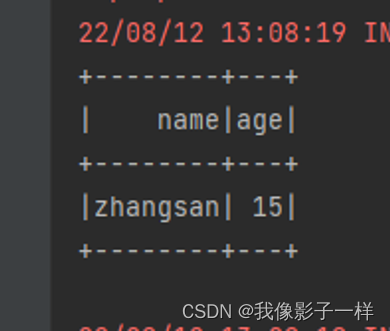
@Test def api(): Unit = { val ds:Dataset[Person]=Seq(Person("zhangsan",15),Person("lisi",10)).toDS() //需求二,便糊查湖 ds.where('name like "zhang%").show() }
-
isin
通过 Column 的 API, 可以轻松实现 SQL 语句中 ISIN 的枚举判断功能
@Test def api(): Unit = { val ds:Dataset[Person]=Seq(Person("zhangsan",15),Person("lisi",10)).toDS() // 需求三,枚举判断 ds.where('name isin ("zhangsan", "wangwu", "zhaoliu")).show( ) }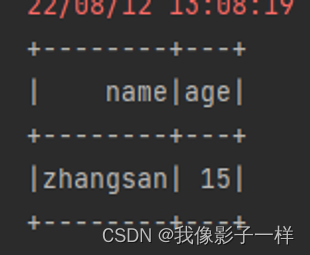
-
sort
在排序的时候, 可以通过 Column 的 API 实现正反序
@Test def api(): Unit = { val ds:Dataset[Person]=Seq(Person("zhangsan",15),Person("lisi",10)).toDS() // 需求四,排序正反序 ds.sort('age asc).show() }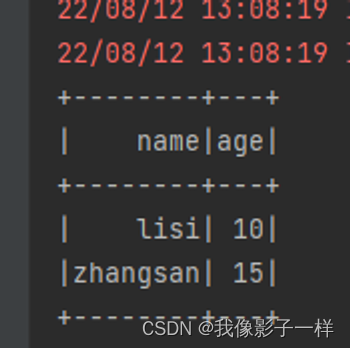
-
以上代码的前置条件
val spark = SparkSession.builder().appName("column").master("local[6]").getOrCreate() import spark.implicits._ case class Person(name: String, age: Int)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!