体系结构汇总复习(练习题)
1.MSI cache一致性协议问题
题解引用自:MSI cache一致性协议_假设在一个双cpu多处理器系统中,两个cpu用单总线连接,并且采用监听一致性协议(msi-CSDN博客


答:
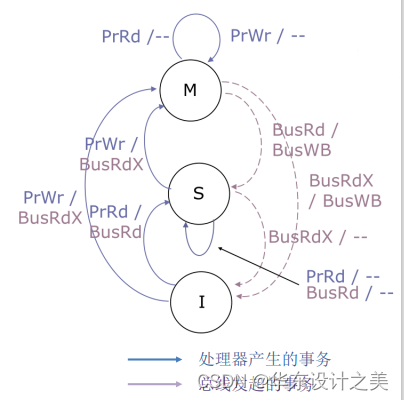
| 事件 | A状态 | B状态 |
|---|---|---|
| 初始状态 | I | I |
| CPU A读 | S | I |
| CPU A写 | M | I |
| CPU B写 | I | M |
| CPU A读 | S | S |
接下来分析CPU A/B中各自cache的状态变化:
- 初始状态时,cache均为无效,即为I;
- CPU A读:
- 当CPU A的cache处于无效状态时,有处理器读PrRd事件发生,就会发生cache miss这样就会装入新数据,但此时其他的cache可能有也可能没有,所以进入S状态,当然需要总线读事件的支持,所以触发总线读事件BusRd。此时CPU A的cache状态为S状态。
- 此时CPU B的cache依旧处于无效状态。
- CPU A写:
- 当CPU A的cache处于共享状态(S)时,有处理器写PrWr事件发生,调用总线互斥读BusRdX事件(目的是告诉其他cache我要修改这个cache,你们先都无效掉),当更新数据后,需要进入M状态,告知这是最新的数据,主存中的数据也是过时的。此时CPU A的cache状态为M状态。
- 此时CPU B的cache依旧处于无效状态。
- CPU B写:
- 当CPU B的cache处于无效状态(I)时,有处理器写PrWr事件发生,会导致cache miss,调用总线互斥读BusRdX事件(目的是告诉其他cache我要修改这个cache,你们先都无效掉),把要写入的数据装入cache(这是由于采用写直达且不分配策略),然后再修改,这时就会进入M状态。
- 此时处于M状态的CPU A cache,通过总线侦听到有总线互斥读BusRdX事件发生,则把自己的cache状态给无效掉了,此时,CPU A的cache状态为I状态。
- CPU A读:
- 当CPU A的cache处于无效状态时,有处理器读PrRd事件发生,就会发生cache miss这样就会装入新数据,但此时其他的cache可能有也可能没有,所以进入S状态,当然需要总线读事件的支持,所以触发总线读事件BusRd。此时CPU A的cache状态为S状态。
- 此时处于M状态的CPU B cache,通过总线侦听到有读BusRd的事件时,因为现在我在M状态,我的数据是最新的,所以当然由我提供数据,所以产生FLUSH事件,最后进入S状态。
2.一致性问题


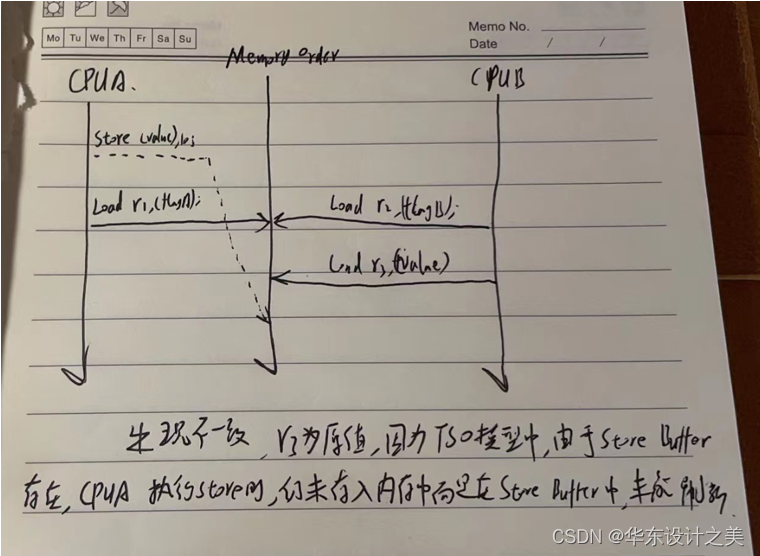
答:?
在TSO模型中,Load 操作可以越过之后的Store 操作,但不能越过之前的 Store 操作;如果处理器 B 在处理器A的 Store 操作完成之前完成了这两个 Load 操作;由于处理器A的 Store 操作的延迟,可能导致处理器 B 读取到 value 的旧值,从而导致r3不一致。
3.MSI目录协议

答:

4.GPU体系结构

补充:?Flops=[CPU核数]*[单核主频]*[CPU单个周期浮点计算能力]
以intel xeon 6348 cpu为例,28核,主频2.6GHz,支持AVX512指令集,且FMA系数=2
CPU单周期单精度浮点计算能力=2 (FMA数量)*2(同时加法和乘法)*512/32=64
CPU单周期双精度浮点计算能力=2 (FMA数量)*2(同时加法和乘法)*512/64=32
6348的单精度算力=28x2.6x64=4659Gflops=4.6Tflops
6348的双精度算力=28x2.6x32=2329Gflops=2.3Tflops
答:
a.? ? ? ??
b.1????????
b.2????????
b.3????????
5.超长指令字VLIW

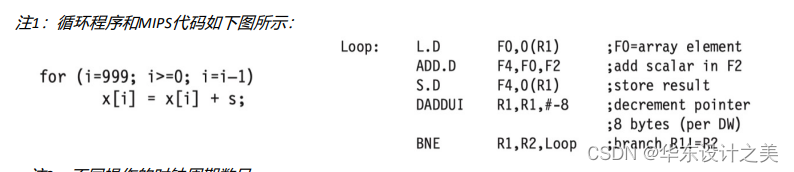


答:
方式一:
采用循环展开的 VLIW 指令进行7次循环展开。假设没有分支延迟,代码一共需要执行10个周期,10个周期内进行了23次操作,指令发射速率为每周期2.3次操作; 操作槽共计5*10=50个槽位,操作槽的有效利用率约为23/50=46%。(可进行优化)

方式二:
采用循环展开的 VLIW 指今进行7次循环展开。假设没有分支延迟期,9个周期内进行了23次操作,指令发射速率为每周期2.5次操作;操作槽个数为5*9=45个,操作槽的有效利用率约为23/45=51.1%

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 嵌入式学习二
- 【Linux】nc 网络诊断 | 文件传输 命令详解
- [GN] 微服务开发框架 --- Docker的应用 (24.1.9)
- 美易makeasy平台:小米汽车雄心勃勃
- 2023全球移动应用营销趋势洞察!Flat Ads白皮书正式发布
- 《WebKit 技术内幕》之四(3): 资源加载和网络栈
- 结合eNSP实验讲VLAN,让理论生动
- 变种水仙花(C语言算法题)
- 使用acado生成mpc控制器c++代码
- 【算法分析与设计】统计数字问题