几行Python代码,轻松搞定Excel表格数据去重

转载说明:如果您喜欢这篇文章并打算转载它,请私信作者取得授权。感谢您喜爱本文,请文明转载,谢谢。
众所周知,Python在处理Excel数据文档时非常强大。最近也尝试了一下使用Python处理Excel数据,几行代码就能实现一个非常有用的功能,非常棒!
这次实验的是,使用Python给Excel数据去重。
创建原始数据
以2023年的四川农产品土特产销售额数据为例,做成原数据文档《SRE成长记2023年四川特产销售额统计.xlsx》,数据如下:
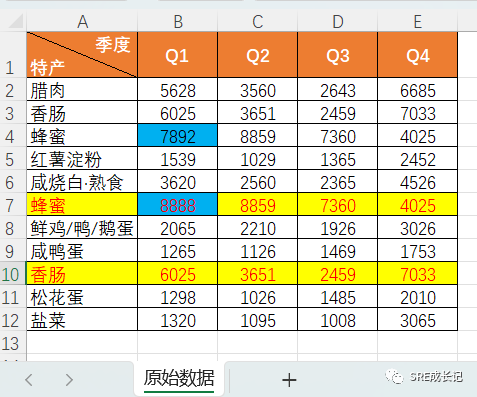
备注:
表格中两行黄色底色数据,为重复数据。其中重复的蜂蜜Q1季度的销售额数据改为了8888,用途后边详解,即蓝色底色的两组数据。
数据处理实验
1. 以“特产”字段为参照,有重复的数据都删掉,并将处理后的数据存入新Excel文件。
代码:
import pandas as pd
data = pd.DataFrame(pd.read_excel("SRE成长记2023年四川特产销售额统计.xlsx","原始数据")) #文件名要带上扩展名.xlsx
# print(data.columns) #查看index,为data.drop_duplicates参数subset的value值提供依据
data.drop_duplicates(subset=[' 季度\n特产'],keep='first',inplace=True)
data.to_excel("SRE成长记2023年四川特产销售额统计-副本1.xlsx")
drop_duplicates参数解释:
subset:以该列为标准,只要在这一列中出现了重复的数据,都会被处理;
keep:出现重复的数据中,保存第几个数据行;first表示保留第一个;last表示保留最后一个;False表示所有重复的行都删除,设置为False时不加引号。
inplace:表示是否在原数据上修改,True表示修改。
执行代码后,在当前目录生成了一个新文件《SRE成长记2023年四川特产销售额统计-副本1.xlsx》,文件中数据为删除了重复数据的新数据:
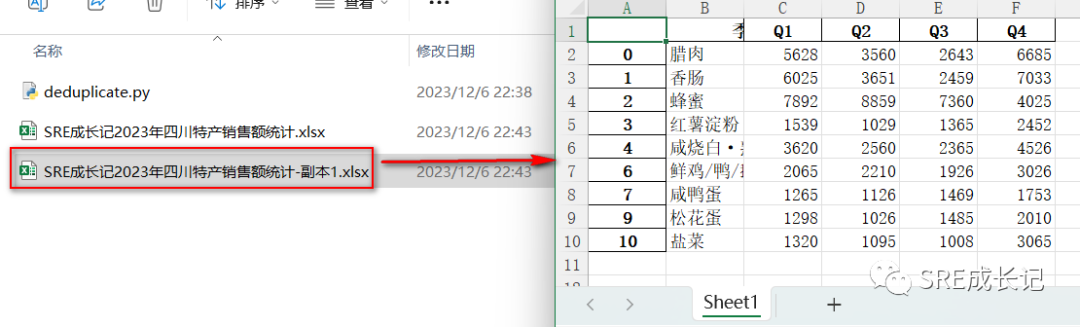
有个问题,即蜂蜜数据。
两行重复的蜂蜜数据,在Q1的销售额是不同的(好比一个班有两个同名同姓的学生,他们语文成绩一样,但其它科目的成绩不相同一样),但因为使用的特产名称来判断数据重复,所以第二条蜂蜜数据就被删除了。
如果用特产名称(或学生姓名)来作为去重标准,就会有类似这种数据被删除的风险。
避免这个风险,可以在去重时,去掉subset参数,默认所有列作为数据重复的对比项。即需要所有列的数据都一模一样,才会被判断为重复数据,被删除,即下一种方法。
2. 对比所有列数据,删除重复数据
代码:
import pandas as pd
data = pd.DataFrame(pd.read_excel("SRE成长记2023年四川特产销售额统计.xlsx","原始数据"))
data.drop_duplicates(keep='first',inplace=True)
data.to_excel("SRE成长记2023年四川特产销售额统计-副本2.xlsx")
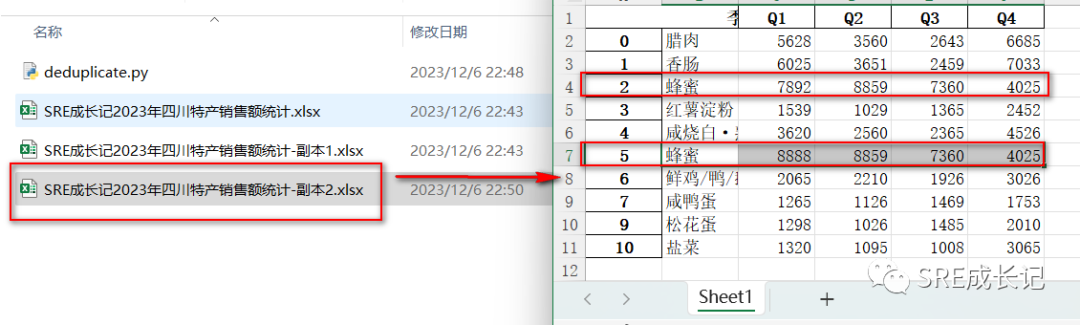
执行代码后,在当前目录生成了新文件《SRE成长记2023年四川特产销售额统计-副本2.xlsx》,文件中数据为处理之后的新数据。
可以看到,因为对比了全局列,所有Q1季度销售额不一样的两条蜂蜜数据都被保留了下来:
3. 将去重后的数据原地保存
将去重后的数据在当前Excel文档相同sheet保存,重新打开文件,就是处理之后的数据了,新数据会覆盖原来的原始数据。
代码:
import pandas as pd
data = pd.DataFrame(pd.read_excel("SRE成长记2023年四川特产销售额统计.xlsx","原始数据"))
data.drop_duplicates(keep='first',inplace=True)
with pd.ExcelWriter("SRE成长记2023年四川特产销售额统计.xlsx") as writer:
data.to_excel(writer)
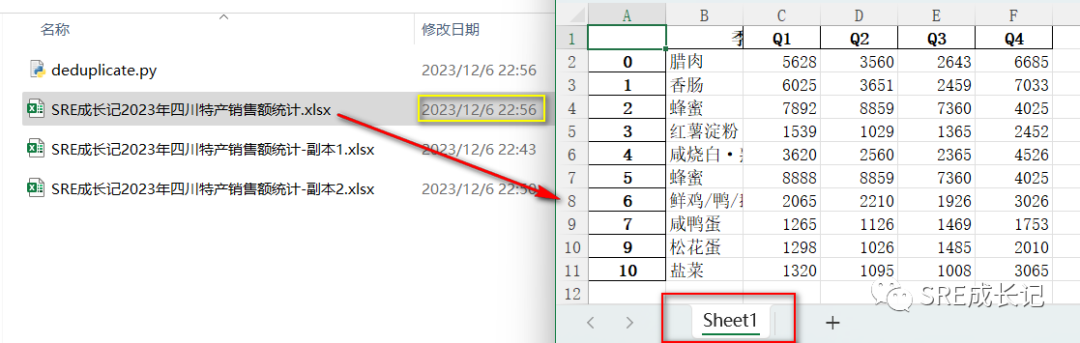
运行代码后,发现原始数据文档《SRE成长记2023年四川特产销售额统计.xlsx》的修改日期变成了最新。
打开文档,文档中数据为处理后的数据,连sheet名称也由原来的“原始数据”变成了“sheet1”:
可以修改上面最后一行代码data.to_excel(writer) 为data.to_excel(writer,sheet_name=‘处理数据’) 给新的sheet重命名:
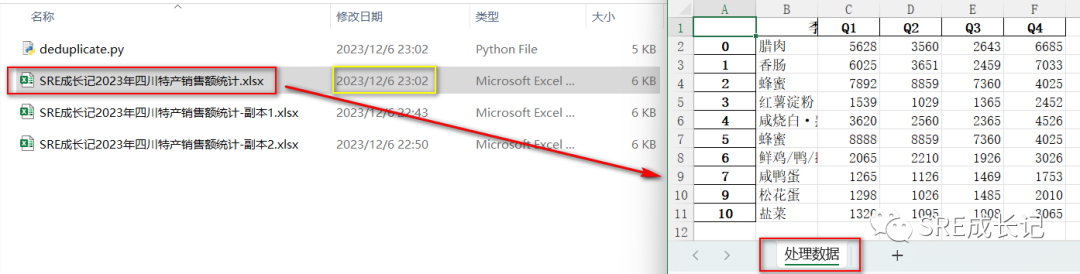
4. 将去重后的数据在原Excel,新建sheet保存
将修改后的数据原地保存,是比较危险的,覆盖了原始数据。如果不想新建文件,可以在当前Excel文件新建sheet保存修改后的数据。
代码:
import pandas as pd
data = pd.DataFrame(pd.read_excel("SRE成长记2023年四川特产销售额统计.xlsx","原始数据"))
data.drop_duplicates(keep='first',inplace=True)
with pd.ExcelWriter("SRE成长记2023年四川特产销售额统计.xlsx",mode='a') as writer:
data.to_excel(writer,sheet_name="处理数据")
执行代码后,原始数据文档《SRE成长记2023年四川特产销售额统计.xlsx》修改时间变成了最新。打开文档,发现已经新建了“处理数据”sheet,原sheet数据未被覆盖:
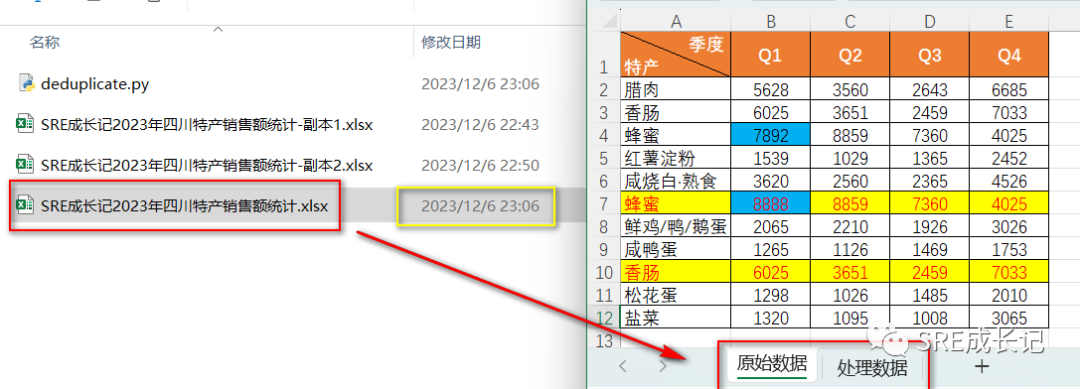
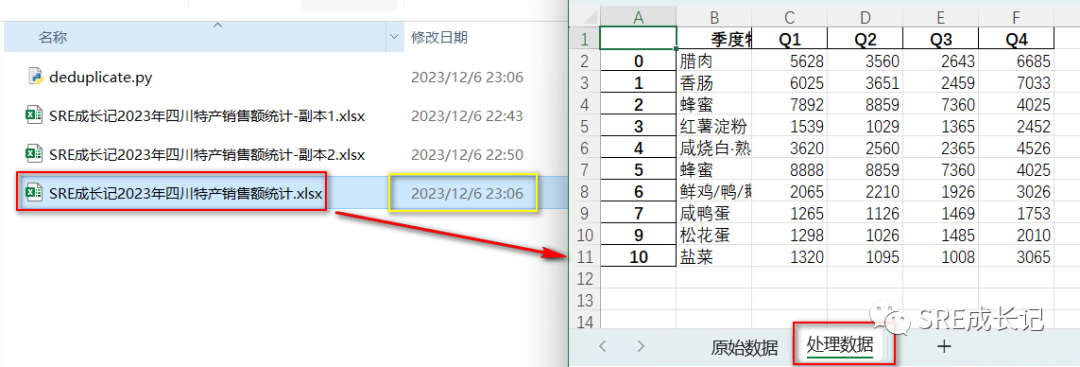
“处理数据”sheet为修改后的数据:
去重处理Excel实验,到此为止,很有意思,你也试试吧。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Transformer and Pretrain Language Models3-3
- 【c++】入门2
- 甜蜜而简洁——深入了解Pytest插件pytest-sugar
- MongoDB的基本使用
- Java 实现自动获取法定节假日
- 【Unity编辑器】使用AssetDatabase创建、删、改、加载资源
- Netty核心——Reactor中篇(九)
- 读书心得(内容取自高质量C/C++编程)
- 【MySQL变更】gh-online-schema-change(gh-ost)原理解读
- vscode配置Todo Tree插件