008-1.数据库管理-exp&imp
?
我 的 个 人 主 页:👉👉 失心疯的个人主页 👈👈
入 门 教 程 推 荐 :👉👉 Python零基础入门教程合集 👈👈
虚 拟 环 境 搭 建 :👉👉 Python项目虚拟环境(超详细讲解) 👈👈
PyQt5 系 列 教 程:👉👉 Python GUI(PyQt5)文章合集 👈👈
Oracle数据库教程:👉👉 Oracle数据库文章合集 👈👈
优 质 资 源 下 载 :👉👉 资源下载合集 👈👈优 质 教 程 推 荐:👉👉 Python爬虫从入门到入狱系列 合集👈👈

数据库管理1
- 数据库管理员
- 数据库(表)的逻辑备份与恢复
- 数据字典和动态性能视图
- 管理表空间和数据文件
- 目标:
- 了解Oracle管理员的基本职责
- 掌握备份和恢复数据库/表的方法
- 理解表空间、数据字典、性能视图
数据库管理员
- 每个Oracle数据库应该至少有一名数据库管理员(dba),但是对于一个大的数据库可能需要多个dba分别担负不同的管理职责,那么一个数据库管理员的主要工作是什么呢?
- 职责:
- 安装和升级Oracle数据库
- 建库、表空间、表、视图、索引......
- 制定并实施备份与恢复计划
- 数据库权限管理,调优,故障排除
- 对于高级dba,要求能参与项目开发,会编写sql语句、存储过程、触发器、规则、约束、包
- 管理数据库的用户主要是sys(董事长)和system(总经理)
sys和system的主要区别
- 存储的数据的重要性不同
- sys:所有的oracle的数据字典的基表和视图都存放在sys用户中。这些基表和视图对于oracle的运行是至关重要的,由数据库自己维护,任何用户都不能手动更改。sys用户拥有dab(数据库管理员)、sysdba(系统管理员)、sysoper(系统操作员)角色或权限。sys是oracle权限最高的用户
- system:用于存放次一级的内部数据。如oracle的一些特性或工具的管理信息。system用户拥有dba()、sysdba角色或系统权限

- 权限不一样
- sys用户必须以as sysdba或asoper形式登陆。不能以normal方式登陆数据库
- system如果正常登陆,他其实就是一个普通的dba用户。但如果以as sysdba登陆,其实结果实际上它是作为sys用户登陆的,从登陆信息里面我们可以看出来
- sysdba和sysoper权限区别
-
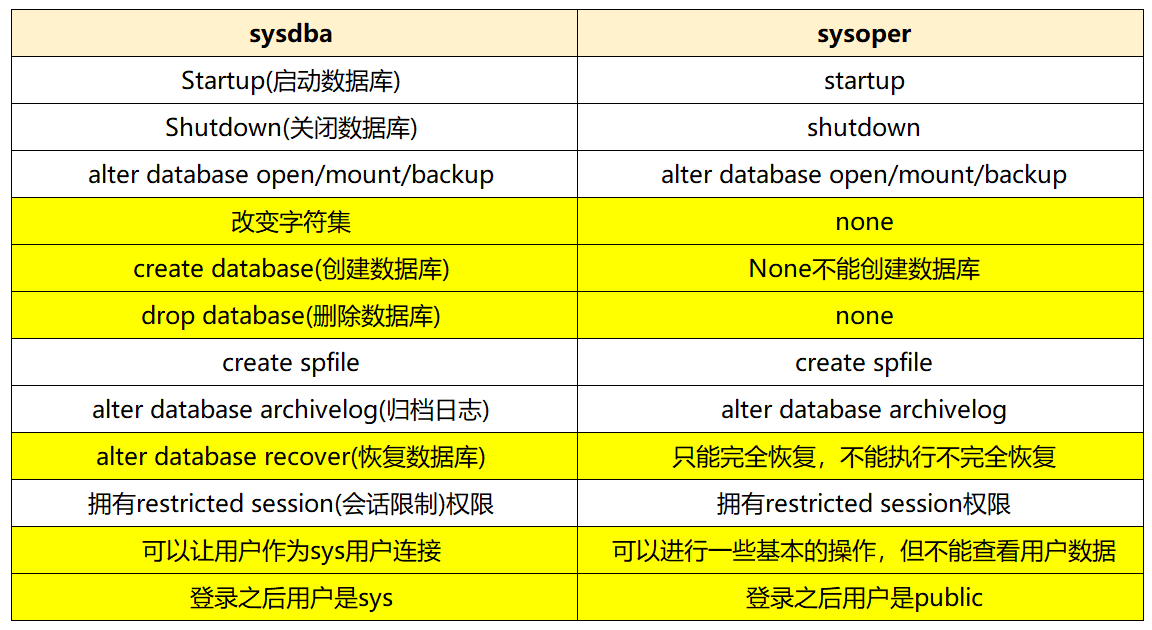
- dba权限:dba用户是指具有dba角色的数据库用户,特权用户可以执行启动实例、关闭实例等特殊操作。dba用户只有在启动数据库之后才有执行各种管理工作
管理初始化参数
- 初始化参数用于设置实例或是数据库的特征。oracle 9i提供了200多个初始化参数,并且每个初始化参数都有默认值
- 显示初始化参数命令:
show parameter - 如何修改参数
- 如果需要修改这些初始化的参数,可以到文件D:\oracle\admin\myoral\pfile\init.ora文件中修改(如:修改实例的名字)
数据库(表)的逻辑备份与恢复
- 逻辑备份:是指使用export工具将数据对象的结构和数据到处到文件的过程。
- 逻辑恢复:是指当数据库对象被误操作而损坏后使用import工具利用备份的文件把数据对象导入到数据库的过程
- 物理备份即可在数据库open的状态下进行,也可以在关闭数据库后进行。但是逻辑备份和恢复只能在open的状态下进行。
导出(exp)
- 导出使用exp命令来完成。
- 导出具体分为三种
- 导出表
- 导出方案
- 导出数据库
- 常用参数:
| 参数 | 说明 | 值 |
|---|---|---|
| userid | 用于指定导出操作的用户名,口令,连接字符串 | username/password@oracle |
| tables | 用于指定执行导出操作的表名称 | 要导出的表名称 |
| owner | 用于指定执行导出操作的方案 | 导出指定对象的名称 |
| full | 用于指定导出操作的数据库 | y:导出全部 |
| inctype | 用于指定执行导出操作的增量类型 | complete:第一次导出之后,第二次导出会比较是否有更新。相对会比较快 |
| rows | 用于指定执行导出操作是否要导出表中的数据 | n:只导出表结构,不导出数据 |
| file | 指定导出文件路径及文件名 | 文件保存路径/文件名.dmp |
| log | 指定记录日志的路径及文件名 | 日志保存路径/日志名.log |
-

-
导出表
-
导出自己的表
exp userid=username/password@oracle tables=(emp,dept) file=d:\emp.dmp log=d:\emp.logusername:用户名 password:用户密码 oracle:数据库实例名 emp:要导出的表名称 -
导出其他方案的表
- 要导出其他方案的表,需要dba的权限或exp_full_database的权限(如:system可以导出scott的表)
exp userid=system/123456@oracle tables=(scott.emp) file=d:\emp.dmp log=d:\emp.log -
导出表结构
exp userid=username/password@oracle tables=(emp) file=d:\emp.dmp log=d:\emp.log rows=n -
使用直接导出方式
exp userid=username/password@oracle tables=(emp) file=d:\emp.dmp log=d:\emp.log direct=y- 这种方式比默认的常规方式速度要快,当数据量大时,可以考虑使用这样的方法
- 使用直接导出方式,数据库字符集与客户端字符集必须完全一致,否则会报错
-
-
导出方案
-
导出方案是指使用export工具导出一个方案或多个方案中的所有对象(表、索引、约束)和数据,并存放到文件中
-
导出自己的方案
exp username/password@oracle owner=username file=d:\filename.dmp log=d:\filename.log -
导出其他方案
- 导出其他方案,需要有dba的权限或exp_full_database权限(如:system可以导出任何方案)
exp system/password@oracle owner=(system,scott) file=d:\filename.dmp log=d:\filename.log
-
-
导出数据库
- 导出数据库是指利用export导出数据库中的所有对象及数据,需要有dba权限或是exp_full_database权限
exp userid=system/password@oracle file=d:\dba.dmp log=d:\dba.log full=y -
inctype=complete 这个参数已经被废弃了
-
数据库在导出时提示警告没有关系,主要提示“导出成功终止”才是最重要的
导出问题
- 由于Oracle 11g的新特性,表数据如果为空,则延迟分配表空间,所以导出的数据不全
- 设置系统参数deferred_segment_creation【默认是TRUE】。
-
dba用户在PLSQL命令窗口输入SQL语句,查询参数值。
show parameter deferred_segment_creation; -
dba用户设置立刻分配表空间(设置后,后续新增的表即使没有数据会自动创建表空间,不再延迟创建)
alter system set deferred_segment_creation=false; -
在新建用户下,查询当前用户下的所有空表
select table_name from user_tables where NUM_ROWS=0; -
根据上述查询,可以构建针对空表分配空间的命令语句,再把下列查询结果语句执行即可
Select 'alter table '||table_name||' allocate extent;' from user_tables where num_rows=0 or num_rows is null;
- 通过以上3步操作后便能正常导出所有空表
- 后续直接exp导出数据即可
导入(imp)
- 导入就是使用import工具将文件中的对象和数据导入导数据库中,但是导入要使用的文件必须是export导出的文件。
- 导入具体分为三种
- 导入表
- 导入方案
- 导入数据库
- imp常用参数
| 参数 | 说明 | 值 |
|---|---|---|
| userid | 用于指定导入操作的用户名,口令,连接字符串 | username/password@oracle |
| tables | 用于指定执行导入操作的表名称 | 要导入的表名称 |
| foruser | 用于指定源用户 | 导出数据的用户 |
| touser | 用于指定目标用户 | 接收导入数据的用户 |
| full | 用于指定执行导入整个文件 | y:导入全部 |
| inctype | 用于指定执行导入操作的增量类型 | complete:第一次导入之后,第二次导入会比较是否有更新。相对会比较快 |
| rows | 用于指定执行导入操作是否要导入表中的数据 | n:只导入表结构,不导入数据,需写在导入语句最后面 |
| ignore | 是否只导入数据(表结构已存在) | y:只导入数据,不导入表结构 |
| file | 指定导入文件路径及文件名 | 文件保存路径/文件名.dmp |
| log | 指定记录日志的路径及文件名 | 日志保存路径/日志名.log |
- 导入表给自己(导入表结构和数据)
imp userid=username/password@oracle file=e:\dba.dmp log=e:\dba.log tables=(emp) - 导入表给其他用户
imp userid=username/password@oracle file=e:\dba.dmp log=e:\dba.log tables=(emp) touser=username2 - 导入表结构(只导结构,不导数据)
imp userid=username/password@oracle file=e:\dba.dmp log=e:\dba.log tables=(emp) rows=n - 导入表数据(只导数据,不导结构)
imp userid=username/password@oracle file=e:\dba.dmp log=e:\dba.log tables=(emp) ignore=y - 导入方案给自己
imp userid=username/password@oracle file:\e:dba.dmp log=e:\dba.log - 导入方案给其他用户
imp userid=username/password@oracle file=e:\dba.dmp log=e:\dba.log fromuser=username tousername=username2 - 导入数据库
imp userid=username/password file=e:\dba.dmp log=e:\dba.log full=y
导出exp参数说明
| 参数 | 说明 |
|---|---|
| USERID | ?户名/?令 |
| FULL | 导出整个?件 (N) |
| BUFFER | 数据缓冲区的?? |
| OWNER | 所有者?户名列表 |
| FILE | 输出?件 (EXPDAT.DMP) |
| TABLES | 表名列表 |
| COMPRESS | 导??个范围 (Y) |
| RECORDLENGTH | IO 记录的长度 |
| GRANTS | 导出权限 (Y) |
| INCTYPE | 增量导出类型 |
| INDEXES | 导出索引 (Y) |
| RECORD | 跟踪增量导出 (Y) |
| ROWS | 导出数据? (Y) |
| PARFILE | 参数?件名 |
| CONSTRAINTS | 导出限制 (Y) |
| CONSISTENT | 交叉表?致性 |
| LOG | 记录屏幕输出的?志?件 |
| STATISTICS | 分析对象 (ESTIMATE) |
| DIRECT | 直接路径 (N) |
| TRIGGERS | 导出触发器 (Y) |
| FEEDBACK | 显?每 x ? (0) 的进度 |
| FILESIZE | 各转储?件的最?尺? |
| QUERY | 选定导出表?集的?句 |
导入imp参数
| 参数 | 说明 |
|---|---|
| USERID | ?户名/?令 |
| FULL | 导?整个?件 (N) |
| BUFFER | 数据缓冲区?? |
| FROMUSER | 所有??户名列表 |
| FILE | 输??件 (EXPDAT.DMP) |
| TOUSER | ?户名列表 |
| SHOW | 只列出?件内容 (N) |
| TABLES | 表名列表 |
| IGNORE | 忽略创建错误 (N) |
| RECORDLENGTH | IO 记录的长度 |
| GRANTS | 导?权限 (Y) |
| INCTYPE | 增量导?类型 |
| INDEXES | 导?索引 (Y) |
| COMMIT | 提交数组插? (N) |
| ROWS | 导?数据? (Y) |
| PARFILE | 参数?件名 |
| LOG | 记录屏幕输出的?志?件 |
| CONSTRAINTS | 导?限制 (Y) |
| DESTROY | 覆盖表空间数据?件 (N) |
| INDEXFILE | 将表/索引信息写?指定的?件 |
| SKIP_UNUSABLE_INDEXES | 跳过不可?索引的维护 (N) |
| ANALYZE | 执?转储?件中的 ANALYZE 语句 (Y) |
| FEEDBACK | 显?每 x ? (0) 的进度 |
| TOID_NOVALIDATE | 跳过指定类型 id 的校验 |
| FILESIZE | 各转储?件的最?尺? |
| RECALCULATE_STATISTICS | 重新计算统计值 (N) |
-
exp/imp是Oracle自带的导入导出命令,运用它,即使不需要那结UI工具也能轻易的完成数据导出导入工作,下面是它们的参数:
-
EXP参数详解
-
使用的格式是:EXP KEYWORD=value 或 KEYWORD=(value1,value2,...,valueN)
-
其中USERID是必须的且为第一个参数
| 关键字 | 备注 |
|---|---|
| USERID | 用户名/口令 |
| FULL | 导出整个文件 (N) |
| BUFFER | 数据缓冲区的大小 |
| OWNER | 所有者用户名列表 |
| FILE | 输出文件 (EXPDAT.DMP) |
| TABLES | 表名列表 |
| COMPRESS | 导入一个范围 (Y) |
| RECORDLENGTH | IO 记录的长度 |
| GRANTS | 导出权限 (Y) |
| INCTYPE | 增量导出类型 |
| INDEXES | 导出索引 (Y) |
| RECORD | 跟踪增量导出 (Y) |
| ROWS | 导出数据行 (Y) |
| PARFILE | 参数文件名 |
| CONSTRAINTS | 导出限制 (Y) |
| CONSISTENT | 交叉表一致性 |
| LOG | 屏幕输出的日志文件 |
| STATISTICS | 分析对象 (ESTIMATE) |
| DIRECT | 直接路径 (N) |
| TRIGGERS | 导出触发器 (Y) |
| FEEDBACK | 显示每 x 行 (0) 的进度 |
| FILESIZE | 各转储文件的最大尺寸 |
| QUERY | 选定导出表子集的子句 |
| 下列关键字仅用于可传输的表空间 | |
| TRANSPORT_TABLESPACE | 导出可传输的表空间元数据 (N) |
| TABLESPACES | 将传输的表空间列表 |
- IMP参数详解
- 使用的格式是:IMP KEYWORD=value 或 KEYWORD=(value1,value2,...,valueN)
- 其中USERID是必须的且为第一个参数
| 关键字 | 备注 |
|---|---|
| USERID | 用户名/口令 |
| FULL | 导入整个文件(N) |
| BUFFER | 数据缓冲区大小 |
| FROMUSER | 所有者用户名列表 |
| TOUSER | 用户名列表 |
| FILE | 输入文件 (EXPDAT.DMP) |
| SHOW | 只列出文件内容(N) |
| TABLES | 表名列表 |
| IGNORE | 忽略创建错误 (N) |
| RECORDLENGTH | IO 记录的长度 |
| GRANTS | 导入权限 (Y) |
| INCTYPE | 增量导入类型 |
| INDEXES | 导入索引 (Y) |
| COMMIT | 提交数组插入 (N) |
| ROWS | 导入数据行 (Y) |
| PARFILE | 参数文件名 |
| LOG | 屏幕输出的日志文件 |
| CONSTRAINTS | 导入限制 (Y) |
| DESTROY | 覆盖表空间数据文件 (N) |
| INDEXFILE | 将表/索引信息写入指定的文件 |
| SKIP_UNUSABLE_INDEXES | 跳过不可用索引的维护 (N) |
| FEEDBACK | 每 x 行显示进度 (0) |
| TOID_NOVALIDATE | 跳过指定类型 ID 的验证 |
| FILESIZE | 每个转储文件的最大大小 |
| STATISTICS | 始终导入预计算的统计信息 |
| RESUMABLE | 在遇到有关空间的错误时挂起 (N) |
| RESUMABLE_NAME | 用来标识可恢复语句的文本字符串 |
| RESUMABLE_TIMEOUT | RESUMABLE 的等待时间 |
| COMPILE | 编译过程, 程序包和函数 (Y) |
| STREAMS_CONFIGURATION | 导入流的一般元数据 (Y) |
| STREAMS_INSTANTIATION | 导入流实例化元数据 (N) |
| 下列关键字仅用于可传输的表空间 | |
| TRANSPORT_TABLESPACE | 导入可传输的表空间元数据 (N) |
| TABLESPACES | 将要传输到数据库的表空间 |
| DATAFILES | 将要传输到数据库的数据文件 |
| TTS_OWNERS | 拥有可传输表空间集中数据的用户 |
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于OpenCv的车道检测
- 虚拟化技术、Docker、K8s笔记总结
- 高中数学:不等式(初接高)
- 解决Java中GB2312字符集缺失的汉字乱码问题
- rust使用protobuf
- 算法的空间复杂度
- 对Array.apply()用法的理解
- CMake入门教程【核心篇】包含目录(include_directories)
- 【Redis】远程访问配置教程与远程客户端连接测试
- 解密!神奇代码消除 Vue 中 Mac 电脑左滑右滑页面跳转