Transformer
1.学习总结
摘要:Transformer是一种神经网络结构,由Vaswani等人在2017年的论文“Attention Is All You Need”中提出,用于处理机器翻译、语言建模和文本生成等自然语言处理任务。
1.1注意力机制
注意力机制(Attention Mechanism)是深度学习中一种模拟人类视觉或听觉系统的工作方式的技术。它的灵感来自于人类的感知过程,即根据输入的信息,有选择性地关注或聚焦于不同部分,以便更有效地处理信息。在深度学习中,注意力机制被广泛应用于序列数据、图像处理等任务。
注意力机制的基本思想是在处理输入序列时,不同位置的信息被赋予不同的权重,以便网络更集中地关注对当前任务有用的部分。这样可以提高模型对长序列或大型数据的处理能力,同时降低处理的复杂性。
在自然语言处理中,注意力机制常常被用于机器翻译、文本摘要等任务。在图像处理中,它可以用于图像分类、图像生成等任务。在注意力机制的基础上,出现了不同的变种,如自注意力机制(Self-Attention)等,用于更好地捕捉序列内部的依赖关系。
具体来说,注意力机制允许模型在处理输入时,对不同位置的信息分配不同的权重,以便网络更有针对性地处理输入序列。这种权重的分配是动态的,可以根据当前输入的情况调整。这种能力使得模型能够更灵活地处理各种输入,并且在处理长序列时不容易出现信息丢失的问题。
在自然语言任务中,通过注意力分数来表达某个词在句子中的重要性,分数越高,说明该词对完成该任务的重要性越大。
计算注意力分数时,我们主要参考三个因素:query、key和value。
query:任务内容key:索引/标签(帮助定位到答案)value:答案
下面一张图可以帮助我们更好地认识q,k,v之间的关系

在文本翻译中,我们希望翻译后的句子的意思和原始句子相似,所以进行注意力分数计算时,query一般和目标序列,即翻译后的句子有关,key则与源序列,即翻译前的原始句子有关。
常用的计算注意力分数的方式有两种:additive attention和scaled dot-product attention。这里主要介绍第二种方法:
scaled dot-product attention
在几何角度,点积(dot product)表示一个向量在另一个向量方向上的投影。换句话说,从几何角度上解读,点积代表了某个向量中的多少是和另一个向量相似的。

图片来源: Understanding the Dot Product from BetterExplained
将这个概念运用到当前的情境中,我们想要求query和key之间有多少是相似的,则需要计算query和key的点积。
下面是注意力机制的公式:
Attention ( Q , K , V ) = softmax ( Q K T d m o d e l ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_{model}}}\right)V Attention(Q,K,V)=softmax(dmodel??QKT?)V
1.2 自注意力机制(Self-Attention)
自注意力机制中,我们关注句子本身,查看每个单词对于周边单词的重要性。这样可以很好地理清句子中的逻辑关系,如代词指代。
举个例子,在’The animal didn’t cross the street because it was too tired’这句话中,‘it’指代句中的’The animal’,所以自注意力会赋予’The’、'animal’更高的注意力分值。
自注意力分数的计算还是遵循着上述的公式,只不过这里的query, key和value都变成了句子本身点乘各自权重。
给定序列
X
∈
R
n
×
d
m
o
d
e
l
X \in \mathbb{R}^{n \times d_{model}}
X∈Rn×dmodel?,序列长度为n,维度为
d
m
o
d
e
l
d_{model}
dmodel?。在计算自注意力时,
Q
=
W
Q
X
,
K
=
W
K
X
,
V
=
W
V
X
Q = W^QX, K = W^KX, V = W^VX
Q=WQX,K=WKX,V=WVX
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
m
o
d
e
l
)
V
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_{model}}}\right)V
Attention(Q,K,V)=softmax(dmodel??QKT?)V。
其中,序列中位置为i的词与位置为j的词之间的自注意力分数为:
Attention
(
Q
,
K
,
V
)
i
,
j
=
exp
(
Q
i
K
j
T
d
m
o
d
e
l
)
∑
k
=
1
n
exp
(
Q
i
K
k
T
d
m
o
d
e
l
)
V
j
\text{Attention}(Q, K, V)_{i,j} = \frac{\text{exp}\left(\frac{Q_iK_j^T}{\sqrt{d_{model}}}\right)}{\sum_{k=1}^{n}\text{exp}\left(\frac{Q_iK_k^T}{\sqrt{d_{model}}}\right)}V_j
Attention(Q,K,V)i,j?=∑k=1n?exp(dmodel??Qi?KkT??)exp(dmodel??Qi?KjT??)?Vj?
1.3 多头注意力(Multi-Head Attention)
多头注意力是注意力机制的扩展,它可以使模型通过不同的方式关注输入序列的不同部分,从而提升模型的训练效果。
不同于之前一次计算整体输入的注意力分数,多头注意力是多次计算,每次计算输入序列中某一部分的注意力分数,最后再将结果进行整合。

图片来源:Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2017.
多头注意力通过对输入的embedding乘以不同的权重参数
W
Q
W^{Q}
WQ、
W
K
W^{K}
WK和
W
V
W^{V}
WV,将其映射到多个小维度空间中,我们称之为“头”(head),每个头部会并行计算自己的自注意力分数。
head
i
=
Attention
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
=
softmax
(
Q
i
K
i
T
d
k
)
V
i
\text{head}_i = \text{Attention}(QW^Q_i, KW^K_i, VW^V_i) = \text{softmax}\left(\frac{Q_iK_i^T}{\sqrt{d_{k}}}\right)V_i
headi?=Attention(QWiQ?,KWiK?,VWiV?)=softmax(dk??Qi?KiT??)Vi?
W
i
Q
∈
R
d
m
o
d
e
l
×
d
k
、
W
i
K
∈
R
d
m
o
d
e
l
×
d
k
W^Q_i \in \mathbb{R}^{d_{model}\times d_{k}}、W^K_i \in \mathbb{R}^{d_{model}\times d_{k}}
WiQ?∈Rdmodel?×dk?、WiK?∈Rdmodel?×dk?和
W
i
V
∈
R
d
m
o
d
e
l
×
d
v
W^V_i \in \mathbb{R}^{d_{model}\times d_{v}}
WiV?∈Rdmodel?×dv?为可学习的权重参数。一般为了平衡计算成本,我们会取
d
k
=
d
v
=
d
m
o
d
e
l
/
n
h
e
a
d
d_k = d_v = d_{model} / n_{head}
dk?=dv?=dmodel?/nhead?。
在获得多组自注意力分数后,我们将结果拼接到一起,得到多头注意力的最终输出。
W
O
W^O
WO为可学习的权重参数,用于将拼接后的多头注意力输出映射回原来的维度。
MultiHead
(
Q
,
K
,
V
)
=
Concat
(
head
1
,
.
.
.
,
head
h
)
W
O
\text{MultiHead}(Q, K, V)=\text{Concat}(\text{head}_1, ..., \text{head}_h)W^O
MultiHead(Q,K,V)=Concat(head1?,...,headh?)WO
简单来说,在多头注意力中,每个头部可以’解读’输入内容的不同方面,比如:捕捉全局依赖关系、关注特定语境下的词元、识别词和词之间的语法关系等。
1.4 Transformer结构
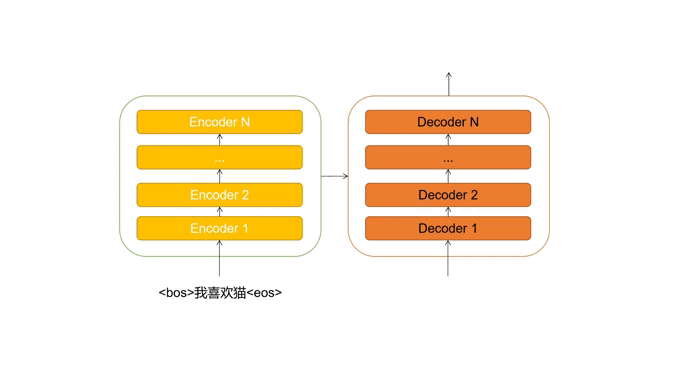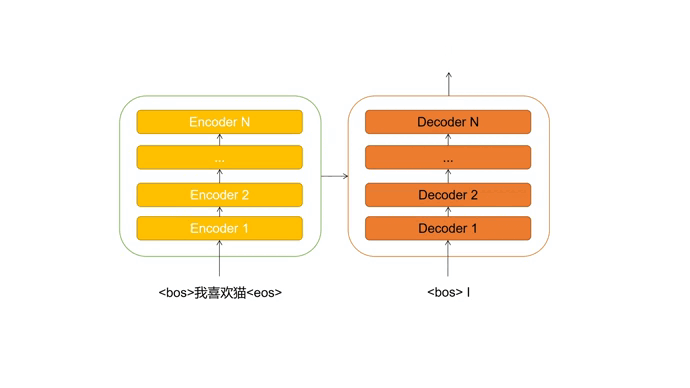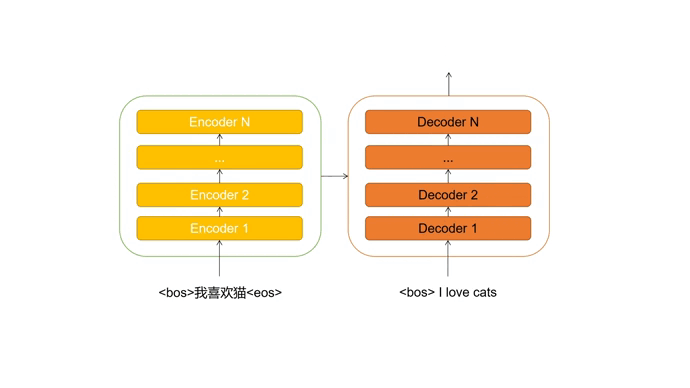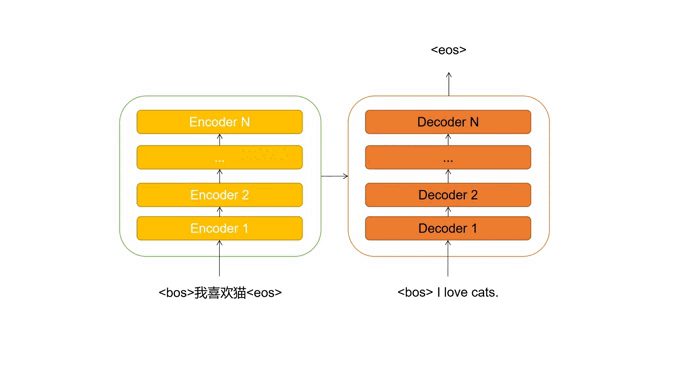
Transformer是encoder-decoder的结构,这里的“encoder”和“decoder”是由无数个同样结构的encoder层和decoder层堆叠组成。
比如在进行机器翻译时,encoder解读源语句(被翻译的句子)的信息,并传输给decoder。decoder接收源语句信息后,结合当前输入(目前翻译的情况),预测下一个单词,直到生成完整的句子。
1.4.1 位置编码(Positional Encoding)
Transformer模型不包含RNN,所以无法在模型中记录时序信息,这样会导致模型无法识别由顺序改变而产生的句子含义的改变,如“我爱我的小猫”和“我的小猫爱我”。
为了弥补这个缺陷,我们选择在输入数据中额外添加表示位置信息的位置编码。
位置编码
P
E
PE
PE的形状与经过word embedding后的输出X相同,对于索引为[pos, 2i]的元素,以及索引为[pos, 2i+1]的元素,位置编码的计算如下:
P
E
(
p
o
s
,
2
i
)
=
sin
?
(
p
o
s
1000
0
2
i
/
d
model
)
PE_{(pos,2i)} = \sin\Bigg(\frac{pos}{10000^{2i/d_{\text{model}}}}\Bigg)
PE(pos,2i)?=sin(100002i/dmodel?pos?)
P
E
(
p
o
s
,
2
i
+
1
)
=
cos
?
(
p
o
s
1000
0
2
i
/
d
model
)
PE_{(pos,2i+1)} = \cos\Bigg(\frac{pos}{10000^{2i/d_{\text{model}}}}\Bigg)
PE(pos,2i+1)?=cos(100002i/dmodel?pos?)
1.4.2 编码器(Encoder)
Transformer的Encoder负责处理输入的源序列,并将输入信息整合为一系列的上下文向量(context vector)输出。
每个encoder层中存在两个子层:多头自注意力(multi-head self-attention)和基于位置的前馈神经网络(position-wise feed-forward network)。
子层之间使用了残差连接(residual connection),并使用了层规范化(layer normalization)。二者统称为“Add & Norm”
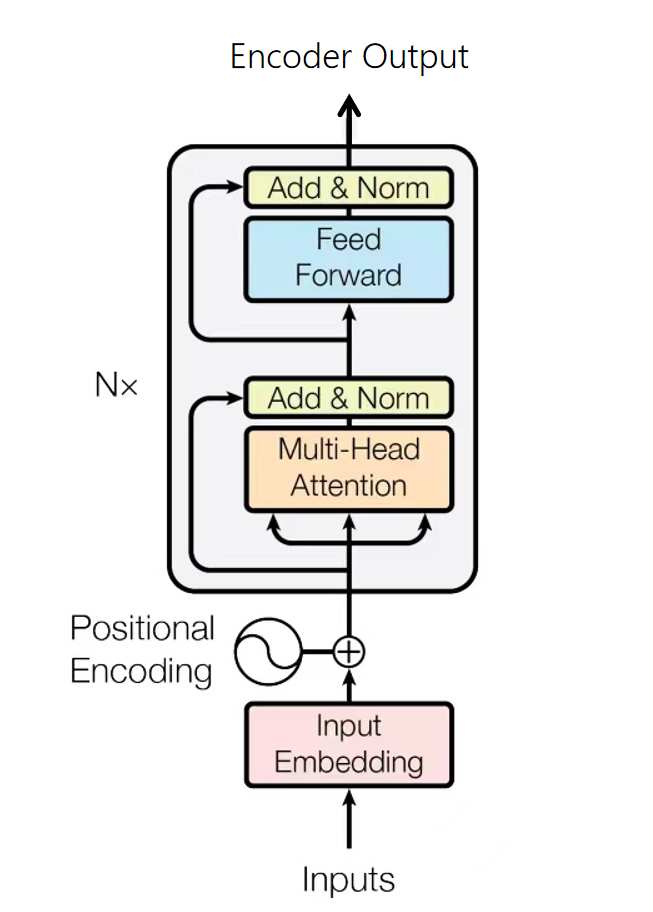
1.4.3Add & Norm
Add & Norm层本质上是残差连接后紧接了一个LayerNorm层。
Add&Norm
(
x
)
=
LayerNorm
(
x
+
Sublayer
(
x
)
)
\text{Add\&Norm}(x) = \text{LayerNorm}(x + \text{Sublayer}(x))
Add&Norm(x)=LayerNorm(x+Sublayer(x))
- Add:残差连接,帮助缓解网络退化问题,注意需要满足 x x x与 SubLayer ( x ) 的形状一致 \text{SubLayer}(x)的形状一致 SubLayer(x)的形状一致
- Norm:Layer Norm,层归一化,帮助模型更快地进行收敛;
1.4.4 解码器 (Decoder)
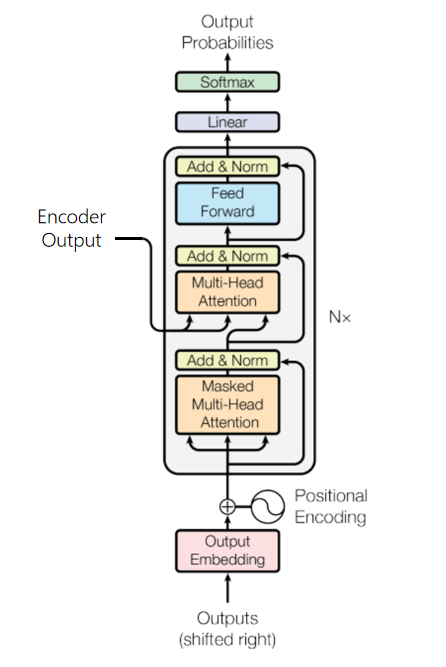
解码器将编码器输出的上下文序列转换为目标序列的预测结果
Y
^
\hat{Y}
Y^,该输出将在模型训练中与真实目标输出
Y
Y
Y进行比较,计算损失。
不同于编码器,每个Decoder层中包含两层多头注意力机制,并在最后多出一个线性层,输出对目标序列的预测结果。
- 第一层:计算目标序列的注意力分数的掩码多头自注意力;
- 第二层:用于计算上下文序列与目标序列对应关系,其中Decoder掩码多头注意力的输出作为query,Encoder的输出(上下文序列)作为key和value;
2.课程实践
实验目标
通过Transformer实现文本机器翻译
全流程
数据预处理: 将图像、文本等数据处理为可以计算的Tensor
模型构建: 使用框架API, 搭建模型
模型训练: 定义模型训练逻辑, 遍历训练集进行训练
模型评估: 使用训练好的模型, 在测试集评估效果
模型推理: 将训练好的模型部署, 输入新数据获得预测结果
这里实验代码比较多,重点从模型构建开始讲
模型构建
定义超参数,实例化模型。
src_vocab_size = len(de_vocab)
trg_vocab_size = len(en_vocab)
src_pad_idx = de_vocab.pad_idx
trg_pad_idx = en_vocab.pad_idx
d_model = 512
d_ff = 2048
n_layers = 6
n_heads = 8
encoder = Encoder(src_vocab_size, d_model, n_heads, d_ff, n_layers, dropout_p=0.1)
decoder = Decoder(trg_vocab_size, d_model, n_heads, d_ff, n_layers, dropout_p=0.1)
model = Transformer(encoder, decoder)
模型训练 & 模型评估
模型训练逻辑
MindSpore在模型训练部分使用了函数式编程(FP)。
构造函数
→
函数变换
→
函数调用
\text{构造函数}\rightarrow \text{函数变换} \rightarrow \text{函数调用}
构造函数→函数变换→函数调用
def train(iterator, epoch=0):
model.set_train(True)
num_batches = len(iterator)
total_loss = 0
total_steps = 0
with tqdm(total=num_batches) as t:
t.set_description(f'Epoch: {epoch}')
for src, src_len, trg in iterator():
loss = train_step(src, trg)
total_loss += loss.asnumpy()
total_steps += 1
curr_loss = total_loss / total_steps
t.set_postfix({'loss': f'{curr_loss:.2f}'})
t.update(1)
return total_loss / total_steps
定义模型评估逻辑
def evaluate(iterator):
model.set_train(False)
num_batches = len(iterator)
total_loss = 0
total_steps = 0
with tqdm(total=num_batches) as t:
for src, _, trg in iterator():
loss = forward(src, trg)
total_loss += loss.asnumpy()
total_steps += 1
curr_loss = total_loss / total_steps
t.set_postfix({'loss': f'{curr_loss:.2f}'})
t.update(1)
return total_loss / total_steps
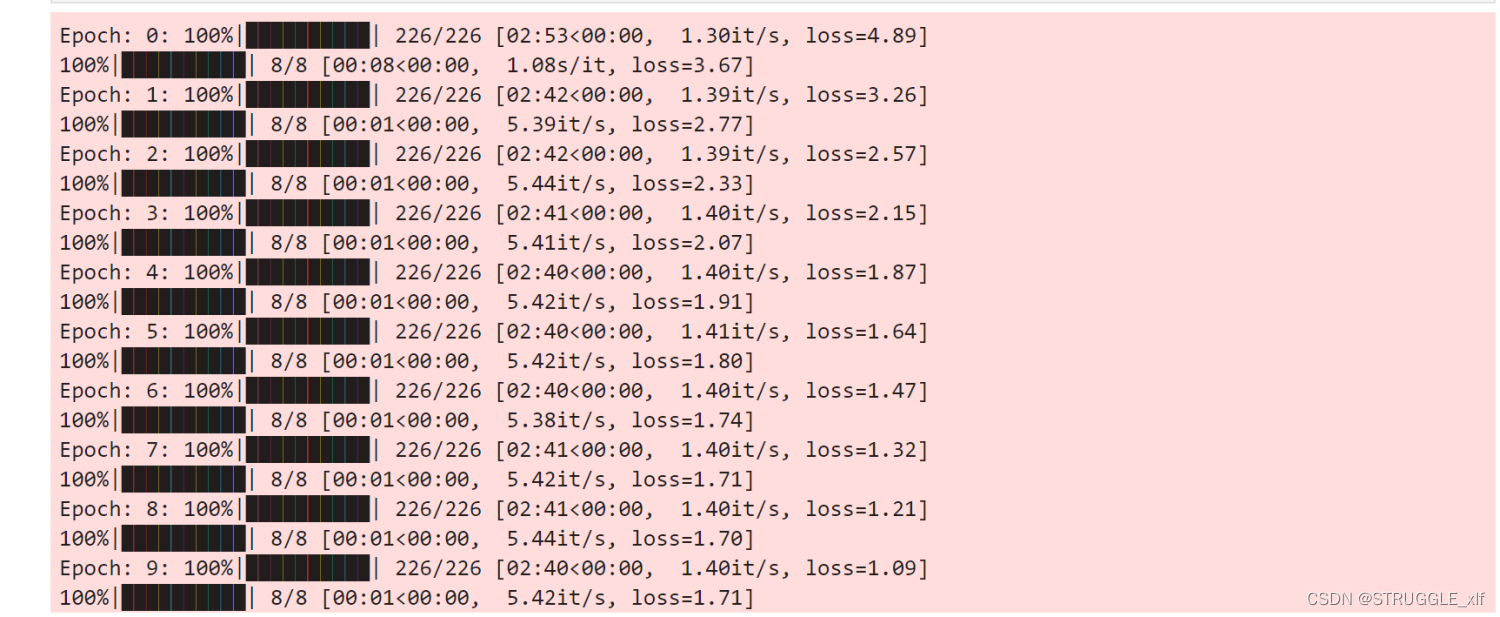
模型训练
数据集遍历迭代,一次完整的数据集遍历成为一个epoch。我们逐个epoch打印训练的损失值和评估精度,并通过save_checkpoint保存评估精度最高的ckpt文件(transformer.ckpt)到home_path/.mindspore_examples/transformer.ckpt。
from mindspore import save_checkpoint
num_epochs = 10
best_valid_loss = float('inf')
ckpt_file_name = os.path.join(cache_dir, 'transformer.ckpt')
for i in range(num_epochs):
train_loss = train(train_iterator, i)
valid_loss = evaluate(valid_iterator)
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
save_checkpoint(model, ckpt_file_name)
模型推理
def inference(sentence, max_len=32):
"""模型推理:输入一个德语句子,输出翻译后的英文句子
enc_inputs: [batch_size(1), src_len]
"""
new_model.set_train(False)
if isinstance(sentence, str):
tokens = [tok.lower() for tok in re.findall(r'\w+|[^\w\s]', sentence.rstrip())]
else:
tokens = [token.lower() for token in sentence]
if len(tokens) > max_len - 2:
src_len = max_len
tokens = ['<bos>'] + tokens[:max_len - 2] + ['<eos>']
else:
src_len = len(tokens) + 2
tokens = ['<bos>'] + tokens + ['<eos>'] + ['<pad>'] * (max_len - src_len)
indexes = de_vocab.encode(tokens)
enc_inputs = Tensor(indexes, mstype.float32).expand_dims(0)
enc_outputs, _ = new_model.encoder(enc_inputs, src_pad_idx)
dec_inputs = Tensor([[en_vocab.bos_idx]], mstype.float32)
max_len = enc_inputs.shape[1]
for _ in range(max_len):
dec_outputs, _, _ = new_model.decoder(dec_inputs, enc_inputs, enc_outputs, src_pad_idx, trg_pad_idx)
dec_logits = dec_outputs.view((-1, dec_outputs.shape[-1]))
dec_logits = dec_logits[-1, :]
pred = dec_logits.argmax(axis=0).expand_dims(0).expand_dims(0)
pred = pred.astype(mstype.float32)
dec_inputs = ops.concat((dec_inputs, pred), axis=1)
if int(pred.asnumpy()[0]) == en_vocab.eos_idx:
break
trg_indexes = [int(i) for i in dec_inputs.view(-1).asnumpy()]
eos_idx = trg_indexes.index(en_vocab.eos_idx) if en_vocab.eos_idx in trg_indexes else -1
trg_tokens = en_vocab.decode(trg_indexes[1:eos_idx])
return trg_tokens
以测试数据集中的第一组语句为例,进行测试。
example_idx = 0
src = test_dataset[example_idx][0]
trg = test_dataset[example_idx][1]
pred_trg = inference(src)
print(f'src = {src}')
print(f'trg = {trg}')
print(f"predicted trg = {pred_trg}")

3.课程心得
我的硕士研究方向是显著性目标检测,毕业论文方向是基于Transformer的显著性目标检测研究,随着Transformer机制在自然语言方向逐渐取得巨大突破,有很多学者都把目光投向了计算机视觉方向,显然Transformer在计算机视觉方向也有巨大进展,带着这样的学习目的,我参加了昇思MindSpore技术公开课,希望对Transformer有一个更加深刻而全面的认识,可以更好地开展我的毕业设计。以下是我的几点课程学习心得:
首先,Transformer引入的注意力机制是一次巨大的创新。相较于传统的循环神经网络(RNN)或长短时记忆网络(LSTM),Transformer采用了自注意力机制,使模型能够在处理长序列时保持更好的信息传递。通过对输入序列中不同位置的信息分配不同的权重,Transformer在语言建模、机器翻译等任务上表现出色。
其次,多头注意力机制使得模型能够同时关注不同的子空间,进一步提高了模型的学习能力。这种并行性的设计使得Transformer在处理大规模数据时表现出色,且能够更好地捕捉序列中的局部和全局依赖关系。
另外,位置编码的引入解决了Transformer无法处理序列顺序信息的问题。通过将位置信息嵌入到输入数据中,Transformer能够更好地理解序列中元素的相对位置,这对于语言等需要考虑单词顺序的任务至关重要。
此外,课程中还深入探讨了Transformer的训练过程,包括Add&Norm、残差连接等技术。这些技术的运用使得Transformer更易于训练,且对于不同类型的数据和任务都具有广泛的适用性。
总的来说,学习Transformer是我深度学习课程中的一大亮点。这一模型的创新性设计和在实际任务中的卓越表现让我深感神经网络领域的不断进步,也让我对深度学习的前景充满信心。Transformer不仅是一种模型,更是一次对神经网络结构的重要革新,为我们进一步探索复杂任务提供了全新的思路和工具。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 使用强化学习提升扩散模型;轻量级LLM无损加速模块;使用RL动态调整Transformer每层参数量;Lumiere文本生成视频
- 【LV13 DAY16 轮询与中断】
- 分发糖果,Java经典算法编程实战。
- 量化择时——动量策略
- 什么是反射?(详解)
- 系列七、Ribbon
- 【进阶】【Python网络爬虫】【18.爬虫框架】scrapy深入,CrawlSpider全栈爬取(附大量案例代码)(建议收藏)
- 【Python】编程练习的解密与实战(二)
- SAP中通过预留简单实现备件领料单的功能
- Java内存模型之原子性