lv12 交叉编译工具链 7
目录
1 交叉编译
1.1 镜像来源
上一节的rootfs、dtb、linux、uboot的都是来自开源软件,这些软件和硬件是不匹配的
整个过程:开源->移植->编译 ->安装

1.2 编译原理
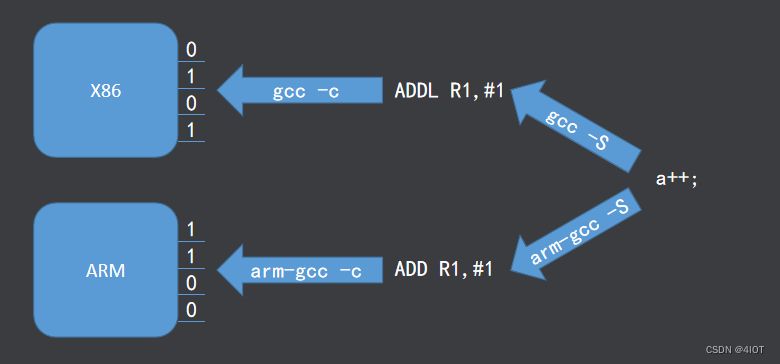
机器码(二进制)是处理器能直接识别的语言,不同的机器码代表不同的运算指令,处理器能够识别哪些机器码是由处理器的硬件设计所决定的,不同的处理器机器码不同,所以机器码不可移植.二进制机器码查错很困难,不可读
汇编语言是机器码的符号化,即汇编就是用一个符号来代替一条机器码,所以不同的处理器汇编也不一样,即汇编语言也不可移植
C语言、C++、python等上层语言在编译时我们可以使用不同的编译器将源码编译成不同架构处理器的汇编,使得上层语言可以移植
1.3 编译过程
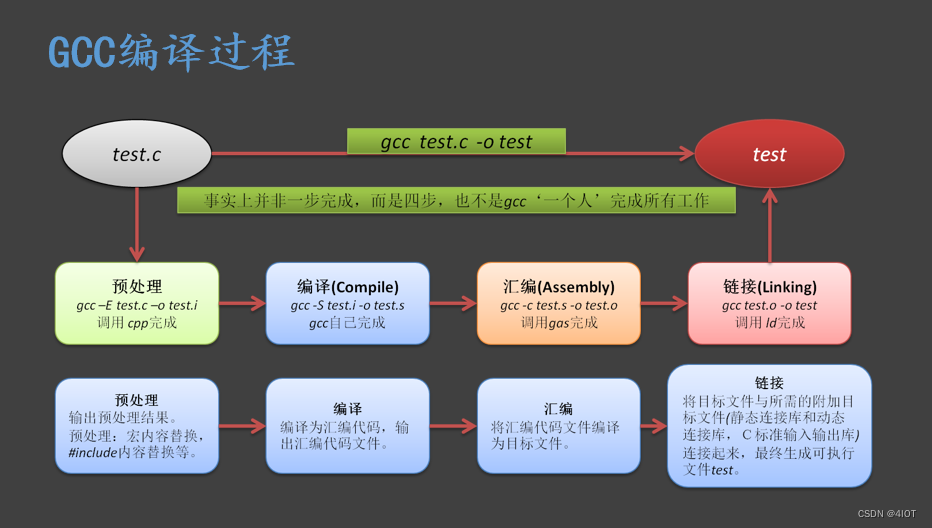
例:
1 预处理把不能直接编译成汇编的内容进行处理,头文件展开

2 编译把C语言处理成汇编(x86上的汇编语言)

3 汇编,把汇编转换成二进制文件

?4 链接,把不同的机器码(库,别人写好的文件)链接在一块

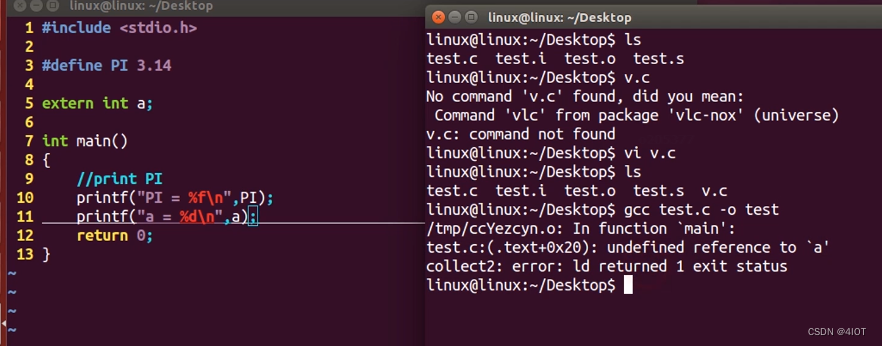
?先预处理、编译和汇编


最后放在一起编译,即ld链接的原理

1.4 交叉编译


1.5 交叉编译工具链获取
?1交叉编译工具链的获取: ?? ?
- 1) 官网获取(不推荐,需要自己进行复杂配置与编译) ?? ??? ?http://ftp.gnu.org/gnu/gcc/ ?? ?
- 2) BSP板级开发支持包(推荐) ?? ??? ?samsung、全志...
2交叉编译工具链的内容 ?? ?
- 1) 交叉编译工具 ?? ??? ?gcc/readelf/size/nm/strip/objcopy/objdump/addr2line ?? ?
- 2) 库 ?? ?ARM架构的库
bin工具目录

ARM共享库(与ubuntu直接提供的库不一样,二进制文件都有平台特性)

 ?
?
2 ELF文件格式?
?ELF格式是Linux平台上应用最广泛的二进制工业标准之一
ELF格式的文件内包含了很多个段不同的段存储了不同的信息;因为ELF格式的文件要通过Linux系统的加载和管理才能运行,所以除了最基本的代码段和数据段之外,其中还存储了很多其它的信息,如符号表、调试信息等(如生成调试文件+G,与不加G生成的elf文件是不一样的)

file
file + 文件名 查看文件的详细信息
readelf
readelf -h + 文件名 列出elf文件的头部信息
readelf -a + 文件名 列出elf文件的所有信息
示例:?


 3 BIN文件格式
3 BIN文件格式
BIN文件一般是直接运行在CPU之上 的可执行文件,文件内只包含了CPU能够直接识别和运行的指令和数据,不包含其它系统相关的信息

4?交叉编译工具链常用工具
size 列出目标文件每一段的大小以及总体的大小
size + 文件名
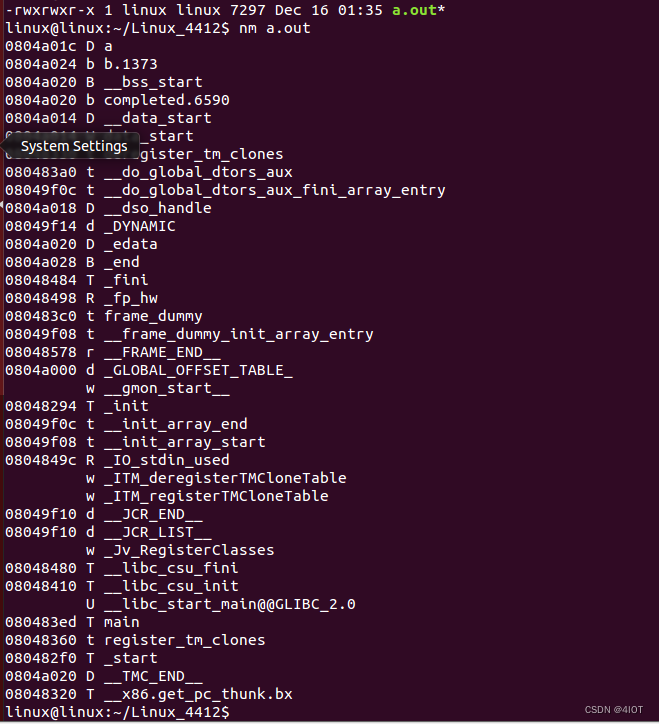
nm 列出目标文件中的符号表(标示符)
nm + 文件名
strip 丢弃目标文件中的符号
strip + 文件名
注:对于嵌入式开发,这个命令很重要
objdump 从目标文件中显示信息
eg:
objdump -d + 文件名 将目标文件反汇编(机器码->汇编)
objcopy 对目标文件进行复制和转换
eg:
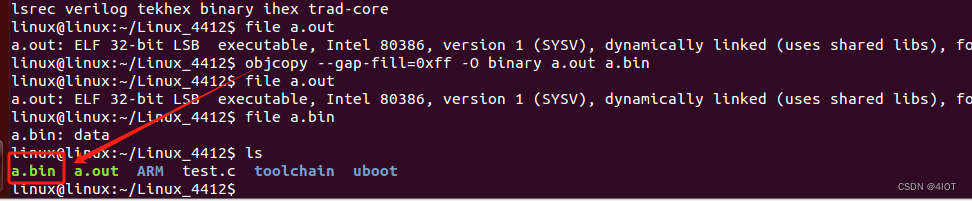
objcopy --gap-fill=0xff -O binary a.out a.bin
将目标文件转换为bin格式
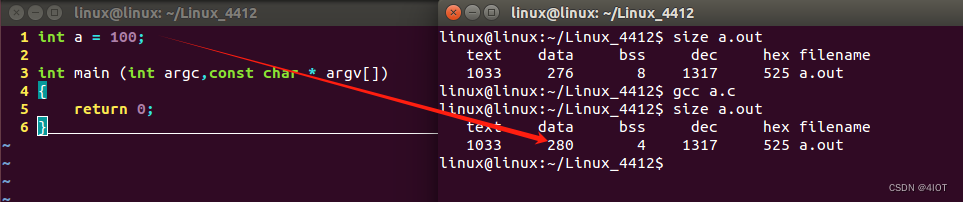
4.1 size命令举例
text 汇编码
data 存放全局变量(static 局部变量)(int a =100)
bss 存放未初始化全局变量和静态局部变量(int a)
示例:

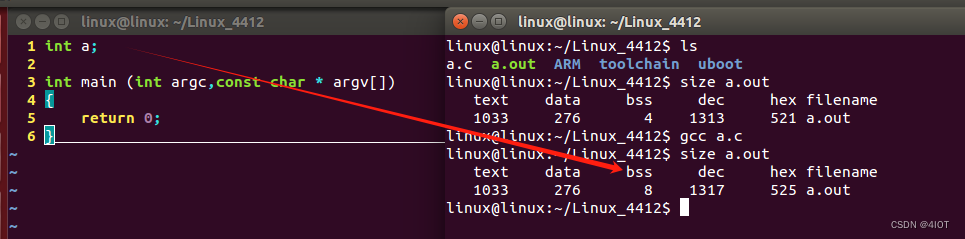
 ?局部变量存放在栈空间,不占用代码大小
?局部变量存放在栈空间,不占用代码大小
?注意:与ll的文件大小相比,size只列出了.text部分的大小

使用编译器

4.2 rm命令举例?
像main函数即是一个符号
4.3 strip命令
丢弃符号表中的符号.symtab,因为程序运行的是很好只有代码段和数据段会加载到内存,符号表并不参与实际程序运行,但是会使得elf文件所占空间变大。
示例:程序瘦身
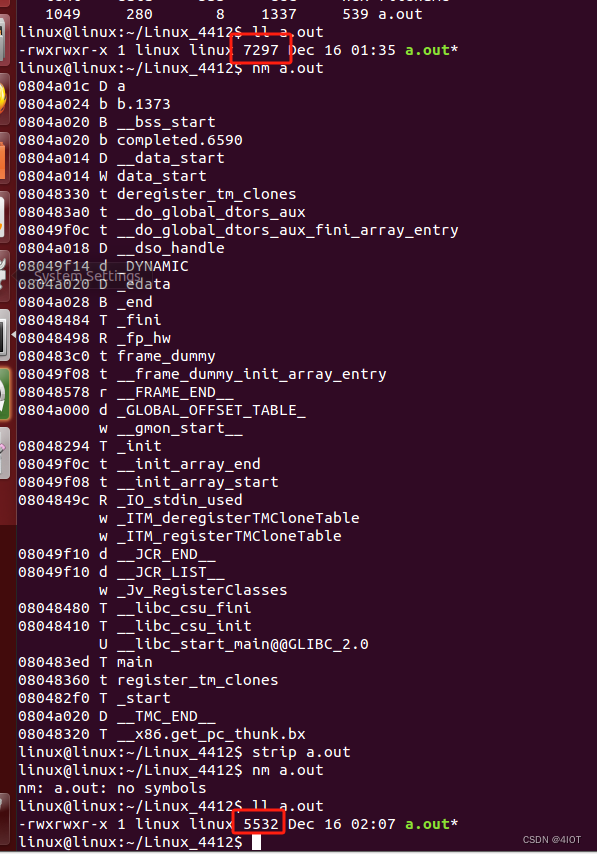
注:对于嵌入式开发,这个命令很重要,arm中使用arm工具的strip命令
可以使用file来查看文件是否瘦身

也可以使用nm来查看库文件中的函数
?4.4 OBJDUMP命令介绍
主要介绍2个,其余可以自己看
-d 反汇编

arm-none-linux的反汇编

如果大写D可以显示更多信息。
用法:
如拿到可执行程序,有些程序需要账号和密码,如果使用b跳转指令,即可直接使用程序运行。
4.5 OBJCOPY命令介绍
把elf文件转换未bin文件,因为elf文件需要运行在linux之上。原理即把代码段数据段的内容提取出来即为bin文件。把许多段,使用gap-fill 填充为0xff即可。
5 练习
1.简述GCC编译C语言程序的步骤及每一步的主要工作?
2.简述ELF格式文件与BIN格式文件的主要区别是什么?
3.简述交叉编译工具链中strip及objdump工具的主要用途是什么?
略
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【华为OD机试真题2023C&D卷 JAVA&JS】高效货运
- linux解压命令
- 深度学习|5.2 偏差和方差
- 波奇学Linux:进程替换
- 淘客返利系统自动赚佣金机器人深度解析
- (C00147)基于SSM(非maven)的学生成绩管理系统-有报告
- C-数据类型的内存表示
- 导致OpenAI内乱的罪魁祸首,背后的技术是什么?
- 使用Flask快速部署PyTorch模型
- JavaScript:Date 对象-时间日期