深度学习|5.2 偏差和方差
发布时间:2024年01月03日
偏差和方差
Bias(偏差):偏差是指对样本点的估计值和实际值的偏离程度。偏差越大,样本点越不符合实际值。偏差衡量单个数据点的偏离程度,如下图的第二行。
Variance(方差):方差能代表对样本点的估计值的范围,衡量的是数据的聚散程度,如下图的第二列。
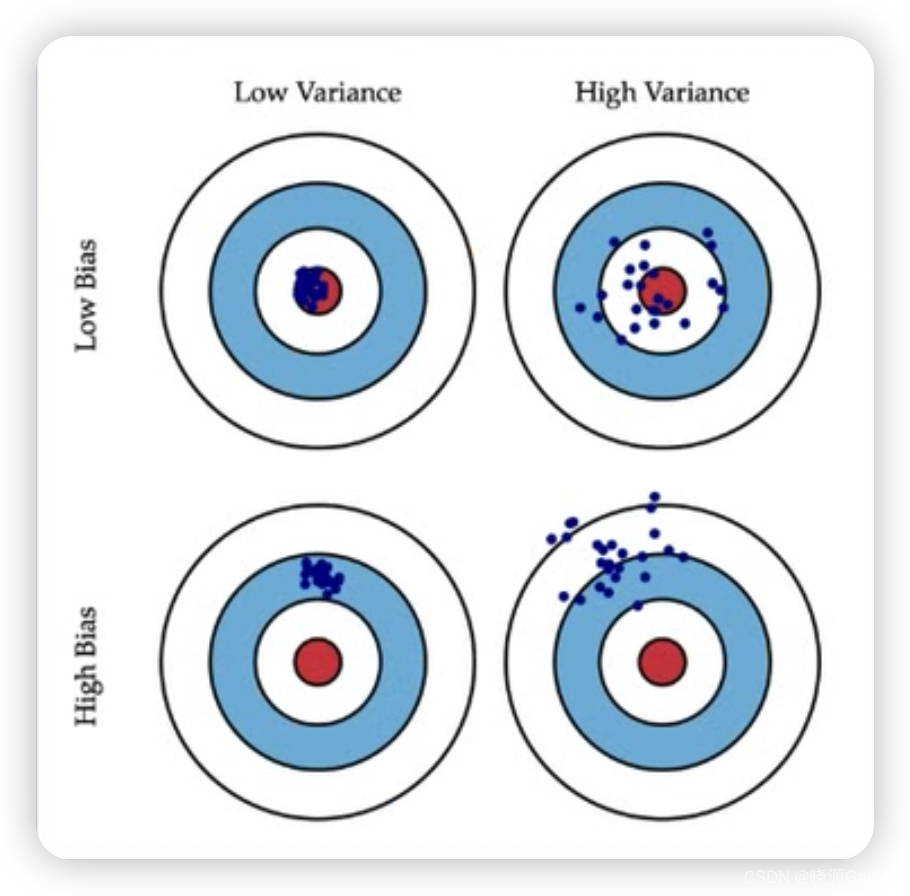
二维图
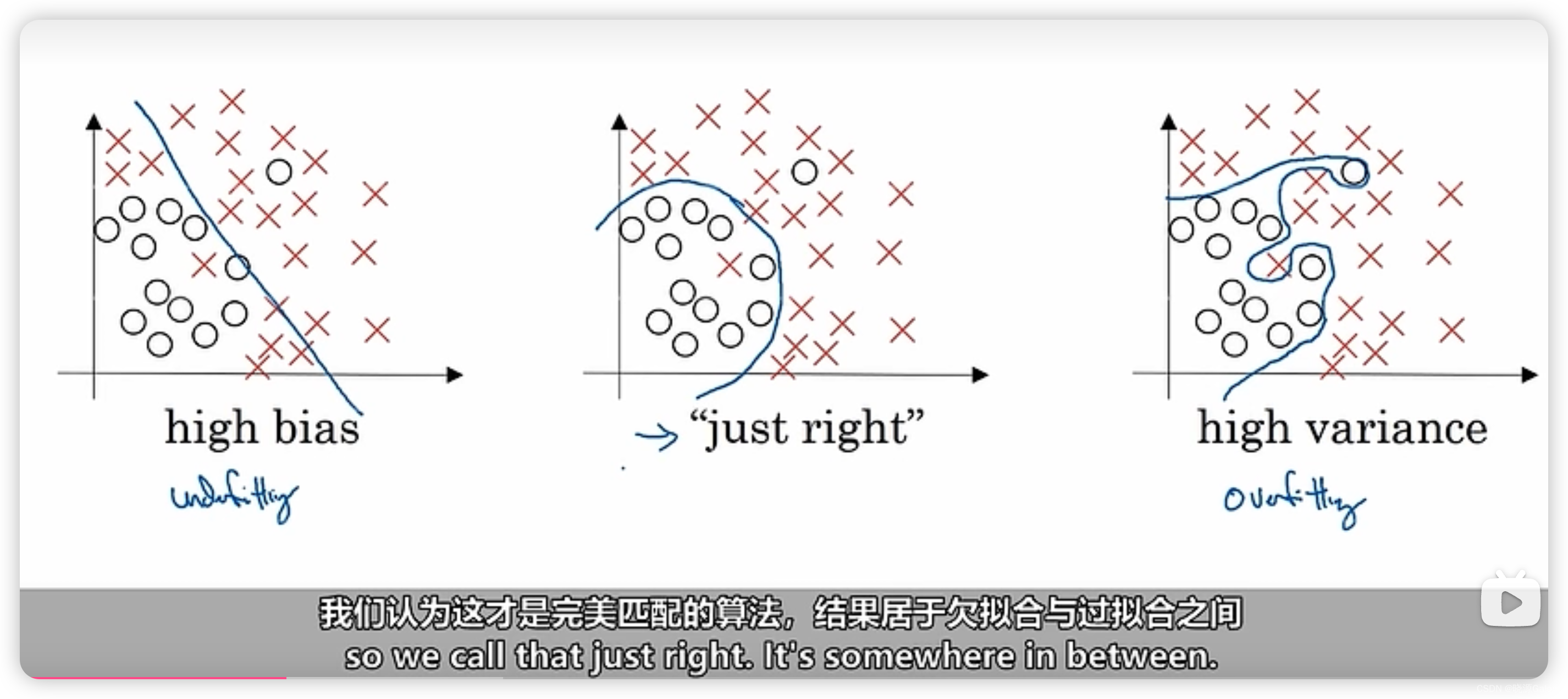
在二维图表上,可以直观感受到决策边界的存在,而到了高维,决策边界就没有那么容易观察得到。
偏差和方差在训练集和验证集的应用。

Train set error = 1%,Dev set error = 11%
说明训练集错误率低,训练后的模型能够很好算出和测试数据真实值相近的预测值,但验证集的错误率高,说明了过拟合(过度适应测试数据,但对新数据的泛化能力弱)和高方差(测试集和训练集的数据都是整体数据的一部分,高方差说明整体数据是一种相对分散的状态,该模型只能很好的去适应整体中的一部分,该模型在整体的其他部分效果就没有那么好)。
Train set error = 15%,Dev set error = 16%
训练集的错误率相对高,说明了模型的偏差较高,而训练集的错误率和测试集的错误率相差不大,说明,训练集内的数据和测试集内的数据相差不大,相对聚拢。
Train set error = 15%,Dev set error = 30%
双高
Train set error = 0.5%,Dev set error = 1%
双低
偏差和方差在二维图中的体现/应用
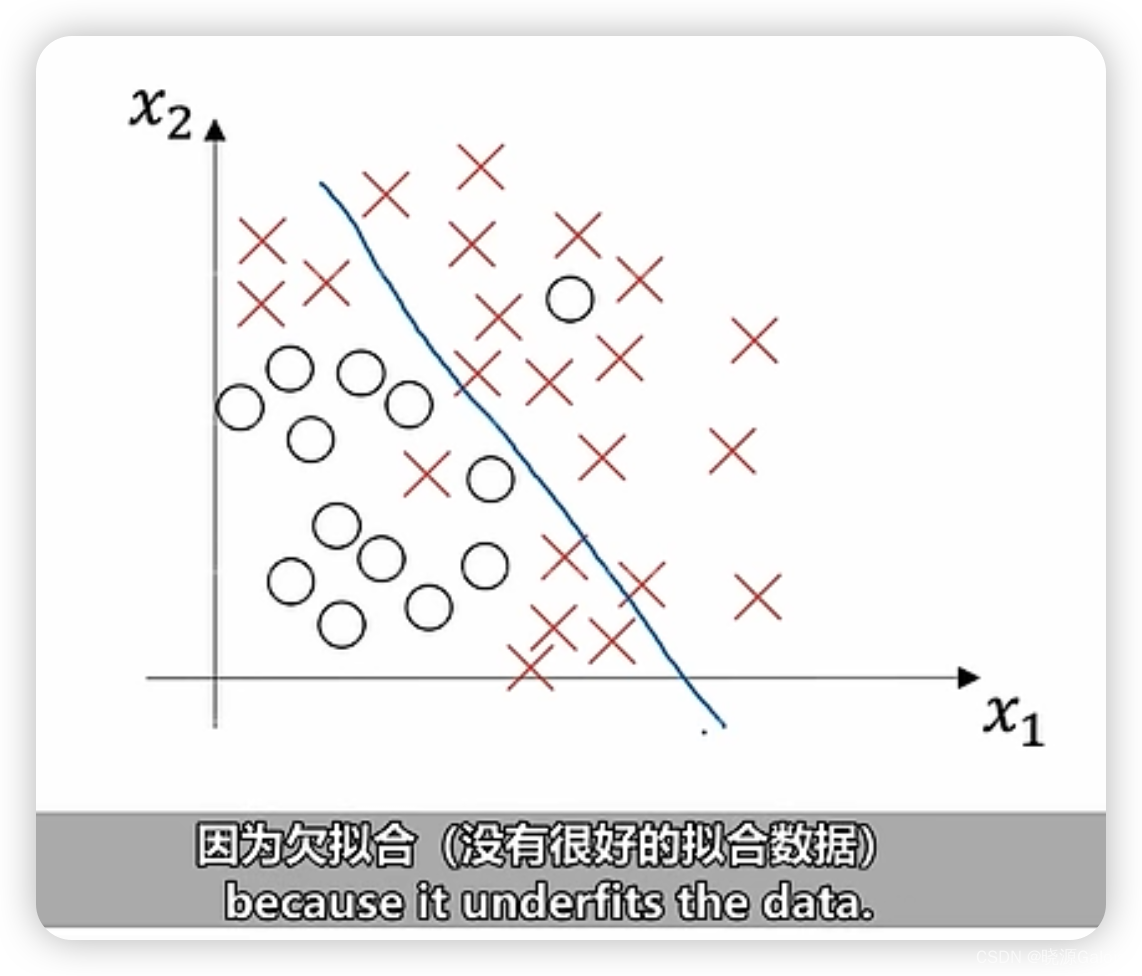
线性分类器并没有很好地将数据分好(很多数据都会被误判),所以属于高偏差的情况。
偏差和方差在设计神经网络中的应用
高偏差说明说当前模型计算出来的预测值和实际值有较大差距。这是模型本身的问题,如果想凭借增添测试集来降低偏差,这是一种不切合实际的做法。
文章来源:https://blog.csdn.net/Fangyechy/article/details/135247186
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!