Linux系统三剑客之awk命令详解(三)
Linux系统三剑客之grep和正则表达式的介绍(一)-CSDN博客
接上文
目录
1.作用
awk是一个强大的文本分析工具,其主要工作原理就是将文件内容逐行读取,按照分隔符进行切片,切成多个组成部分,然后将每片保存到内建的变量中。如果指定了模式的话,根据模式匹配是否处理此行内容,若此行文本符合模式,则按照动作处理文本。
以上介绍到了几个关键词,分别是模式和动作,具体意思会放在后面介绍 。
在上面的文本中,通过分隔符将文本内容切割成多个列,那么如果想获取某个列怎么办呢 ?就可以使用$加上第几列的数量就可以。具体如下:
-
$0 : 代表所有数据
-
$1 : 代表第一列
-
$2 : 代表第二列
-
$n : 代表第n列
需要注意的是,若切割出的第n列已经没有数据,你继续输出的话就输出了空行 。
?
awk早期就以在Unix上实现了,现在Linux上所使用的awk其实是gawk,也就是GUN awk,简称为gawk。而在Linux中所使用的是awk其实就是链接到了gawk中了。
2.语法
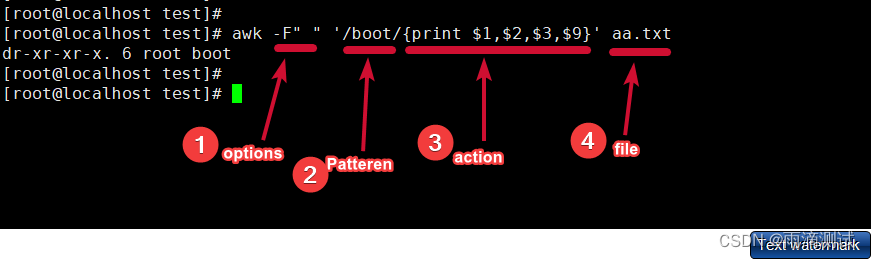
awk [options] 'Pattern {Action}' file-
awk是固定的语法,在Linux下也可以使用gawk代替
-
其中options为选项,在awk中支持的选项介绍具体见“选项”小结
-
其中Pattern为模式,在awk中支持的模式介绍有见“模式”小结
-
其中Action为要执行的命令,在awk中支持action介绍见"动作"小结
-
file为文本文件,需要注意的是awk读取的文件流不一定是要跟的这个file,也可以是通过管道输出的结果作为文件流。
?
3.变量
在介绍完awk的语法之后,我们有必要先了解下awk变量,因为无论是options还是Pattern,都会使用到变量。对于awk来说 ,主要包括内置变量和自定义变量两种。
-
内置变量:变量名已经定义好了,一般情况下一会给一个默认值 ,当然我们也可以自定义变量的值 。
-
自定义变量 : 用户自己去定义变量的名字和变量的值 。
变量的定义格式:var_name = value
内置变量
| 内置变量名 | 含义 |
|---|---|
FS | 输入字段分隔符,默认为空白字符 |
OFS | 输出字段分隔符,默认为空白字符 |
RS | 输入记录分隔符(输入换行符),指定输入时的换行符 |
ORS | 输出记录分隔符(输出换行符),指定输出时的换行符 |
NF | 当前行的字段数(当前行被分隔符分割成了几段) |
NR | 当前行的行号 |
FNR | 不同文件分别计数 |
FILENAME | 当前文件名 |
ARGV | 数组,保存的是命令行所给定的各参数 |
ARGC | ARGC数组的个数 |
变量使用也非常简单,直接使用变量名即可,具体如下:
自定义变量
自定义变量,简单来说就是用户自己定义的变量。在awk中有两种方式可以自定义变量。
方式1:使用-v参数,定义格式为:-v var_name = value .
方式2:在BEGIN模式中定义 。
以上的两种方式,目前还没有涉及到,故我们在下面内容中讲解 。
注意:定义变量最终的目的是要使用变量,那么在awk中怎么使用呢 ? 答案就是使用处直接写变量的名字就可以得到变量的值了 。那么变量一般会在哪使用呢 ? 在后面要讲解到的模式和动作都会用到 。
4.选项
所谓的选项,就是awk后面的options,一般都是通过减号(-) 加上一个英文字符组成,不同英文字符代表不同的意思 。在awk中支持的选项参数也有很多,放在方括号内([])代表这个选项是可选的。这里主要介绍最常用的。
?
-
-F : 指明用于分割内容的分隔符,若不加该参数,默认使用空格分割
-
-v : 自定义变量,具体格式为:var_name = value .
-
-f : 调用脚本。
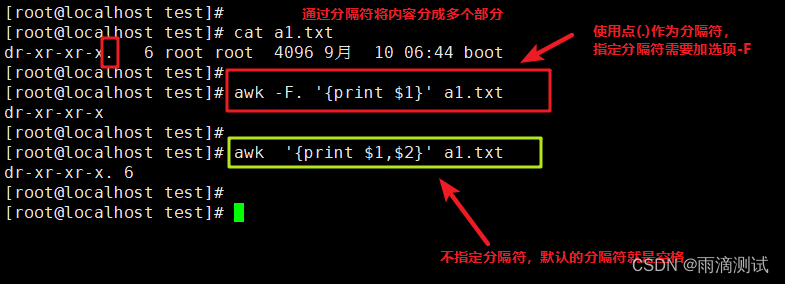
-F 选项
以下是对-F参数的说明,在此案例中使用英文点(.)作为分隔符,通过分隔符将文本内容分隔成多个部分。
-v 选项
在上面我们介绍-v可以自定义变量,自定义变量时,变量名可以是内置变量也可以用户自己定义的变量名 ,具体定义方式如下:
?2)自己定义变量名进行定义 
5.模式

所谓的模式,其实就是Pattern的部分,我们可以将模式理解为条件,在前面介绍到awk是逐行处理的,那怎么判断哪行该处理?哪行不该处理呢 ?答案就是这个模式,当匹配到的模式就是要处理的行,而不匹配的行就会被跳过。
另外,Pattern部分一定要放在引号当中,一般使用单引号引起来。一条awk指令可以包括0个模式或多个模式 ;如果后面有Action ,中间用空格隔开 。
Pattern主要包括以下几个部分:
-
BEGIN模式:初始化代码块,即开始处理文本前要执行的操作 。
-
END模式:收尾工作,即处理文本之后要执行的操作
-
关系表达式模式 :相当于条件判断,满足条件的就会执行后面的‘动作’,而这里就支持各种运算符,如比较运算符,算数运算符等。
-
空模式 :此模式会匹配文本的每一行,也就是每一行满足条件 。
-
正则模式:通过正则进行匹配,匹配后的将会执行后面的动作 。
-
行范围模式 :处理pattern1到pattern2之间(不包含pattern2) 。从pattern1匹配的行开始,到pattern2匹配的行结束 。
BEGIN模式
在前面介绍到,BEGIN模式是在处理文本之前的动作,在声明BEGIN时,后面括号内的语句就是BEGIN要执行的操作,
END模式
指定了处理完文本内容之后执行的操作,也就是进行一些收尾工作 。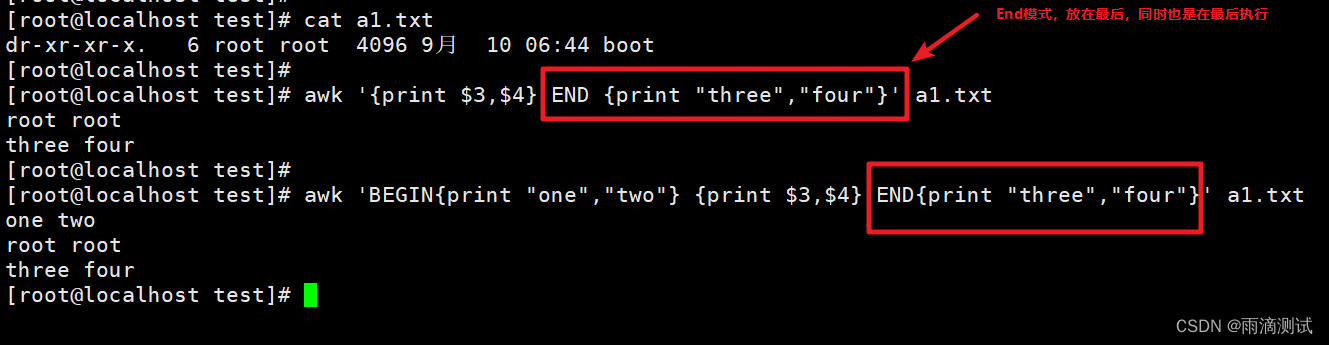
?
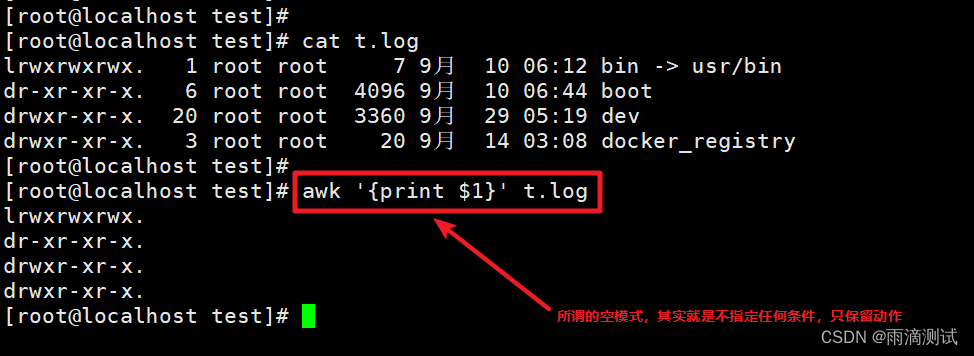
空模式
空模式其实就是不设置任何模式或条件 ,也就是说对文本的每一行需要执行的处理就是空模式,简单来说空模式就是对行不做过滤处理,具体如下:
关系表达式模式
所谓的关系表达式模式是指包含表达式的模式,通过该表达式对文本行进行过滤处理 。
-
表达式可以是比较表达式,也可以是赋值运算符
-
同时支持的操作符也是
以下为比较表达式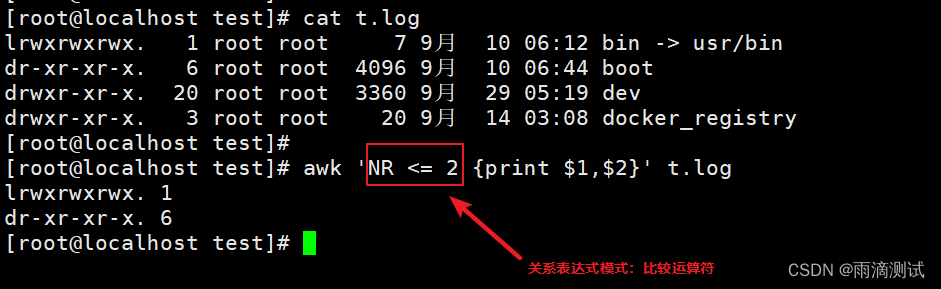
awk支持的比较运算符还包括:
-
x < y : 小于
-
x <= y :小于等于
-
x > y : 大于
-
x >= y :大于等于
-
x == y : 等于
-
x != y :不等于
-
x ~ y : 匹配正则y为真
-
x !~ y : 不匹配正则y为真
以下为赋值表达式
awk支持的赋值运算符包括:
-
x = y : 赋值
-
x += y : 先加后赋值
-
x -= y : 先减后赋值
-
x *= y : 先乘后赋值
-
x /= y : 先除后赋值
-
x %= y :先取余后赋值
-
x^= y:先次方后赋值
-
x ** y : 先次方后赋值
-
x ++ :对x+1
-
x -- : 对x-1
支持的算数运算符:
-
x+y:加法 -
x-y:减法 -
x*y: 乘法 -
x/y: 除法 -
x%y:取余 -
x^y: 次方(效果和**一样) -
x**y: 次方
支持布尔类型:
-
非0值为true
-
非空字符串为true
-
其余为为false
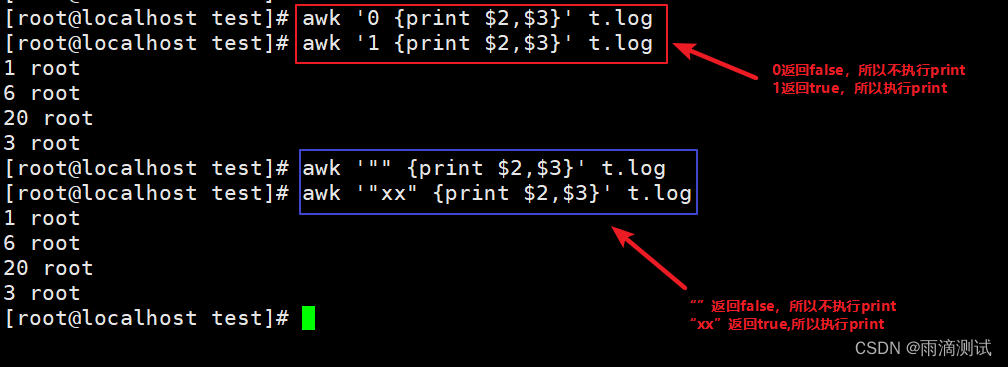
支持的逻辑操作符:
-
x && y: 两者都满足返回true
-
x || y :一个满足返回true
-
! x : x若返回假,则返回true
除了以上支持的各种运算符外,awk还支持函数调用,条件语句,循环语句
正则模式
所谓的正则模式,其实就是使用正则表达式作为的模式 。所以要想使用这个模式,我们就的熟悉正则表达式,如果你还是对正则表达式不太熟悉,可参考第一章的正则表达式。
使用正则表达式也有一定的规则,具体如下:
awk '/正则表达式/{Action}' file行范围模式
行范围模式,是使用正则表达式来匹配两个关键字之间行的数据,如果这个关键字在文本中出现过多次,那么也会匹配出多次 。它的使用规则如下:
awk '/正则1/,/正则2/{Action}' file
6.动作
所谓的动作,就是Action 的部分,在Action部分主要包括如下几个部分。
?
在Action中,虽然看语法写的是一个Action,但是在括号内可以有多个执行语句 ;也可以直接编写多个Action动作 。 ?
-
print :打印语句
-
printf:同样为打印语句,但是可以进行格式化 -
条件语句 :可以进行条件判断
-
循环语句 :可以进行循环.
print语句
在上面已经多次使用到,使用print语句可以输出变量值,在这里就不再赘述 。
printf语句
和print语句类似,但是比print语句更加强大,它的主要作用是可以对文本进行格式化处理,其语法格式为:
?printf format,item1,item2 ...
-
format用于指定后面每个item的输出格式
-
format一般输入的是格式符+修饰符+一些字符组成的字符串(见下),同时需要用双引号引起来
-
fromat和item都需要用逗号隔开
-
printf语句不会自动换行,若要进行换行,需通过\n
格式符
-
%f: 显示为浮点数 -
%g,%G: 以科学数法或浮点形式显示数值 -
%s: 显示字符串 -
%u: 无符号整数 -
%%: 显示%号自身,相当于转义
修饰符
-
N: 显示宽度 -
-: 左对齐(默认为右对齐) -
+: 显示数值符号
条件语句
如果学习过编程语言,都知道在编程语言中有if ...else语句 ,那么对于awk来说,也是支持if ... else 。在awk支持如下三种情况:
-
if(条件){执行语句1;执行语句2}
-
if(条件){执行语句1} else {执行语句2}
-
if(条件1){执行语句1} else if(条件2){执行语句2} else{执行语句3}
对于以上代码做个简单说明:
-
第一种情况:如果条件为真,执行大括号{}内的语句
-
第二种情况:如果条件为真,执行语句1;否则执行语句2
-
第三种情况:如果条件1为真,执行语句1,否则如果条件2为真,执行语句2,否则,执行语句3

循环语句
在awk中,支持的for循环也有三种,分别是for, while,do ... while .具体如下:
# for循环语法格式1:
for(初始化;布尔表达式;自增减){
//执行代码
}
# 实例
for(i=0;i<=10;i++){print i}
# 说明
1.初始化变量的值
2.开始执行布尔表达式,如果为真,执行后面的打印语句
3.进行+1
4.重复执行第2,3步骤
# for循环语法格式2:
for(变量 in 数组){
//执行代码
}
#实例
for(i in arrname){
print i,arrname[i]
}
# while循环语法格式
while(布尔表达式){
//执行代码
}
#实例
while(i<=10){print i}
# 说明
1.执行条件判断,若为真,执行后面打印语句
2.重复循环第1步骤
# do ... while循环语法
do{
//执行代码
}while(条件)
#实例
do{print "helloworld";i++}while(i<=3)
# 说明
1.先执行打印语句,然后再自加1
2.执行条件判断,若为真,继续执行打印语句,然后再自加1,依次循环,直到条件变为假。
当然除了以上的循环外,我们还可以在跳过本次循环,或者断开循环 . 分别使用的关键词为:
-
跳过循环:continue
-
断开循环:break

?
7.实例
以下练习主要使用abc.log文本进行练习;
[root@localhost test]# cat abc.log
drwxr-xr-x. 20 root root 3360 9月 29 05:19 dev
drwxr-xr-x. 3 root root 20 9月 14 03:08 docker_registry
drwxr-xr-x. 2 root root 41 9月 17 06:23 docker_study
drwxr-xr-x. 151 root root 12288 9月 29 05:20 etc
drwxr-xr-x. 3 root root 18 9月 10 06:57 home
lrwxrwxrwx. 1 root root 7 9月 10 06:12 lib -> usr/lib
lrwxrwxrwx. 1 root root 9 9月 10 06:12 lib64 -> usr/lib64
drwxr-xr-x. 2 root root 6 4月 11 2018 media
drwxr-xr-x. 2 root root 21 9月 19 21:51 mnt1.输出第一,第二列数据,中间不空格
2.输出第1,3,5列数据,以制表符进行分割 ?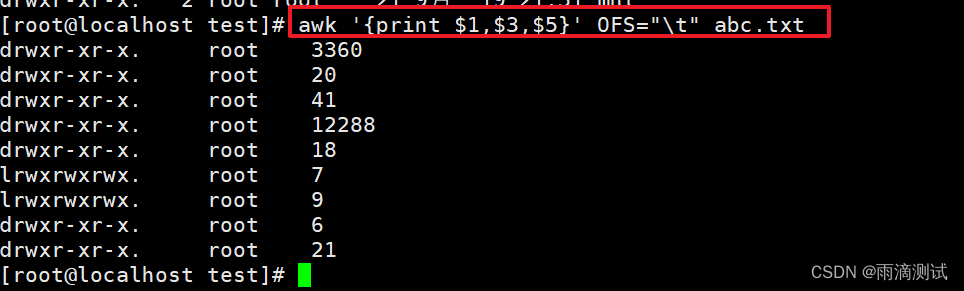
3.显示每行有多少字段 ?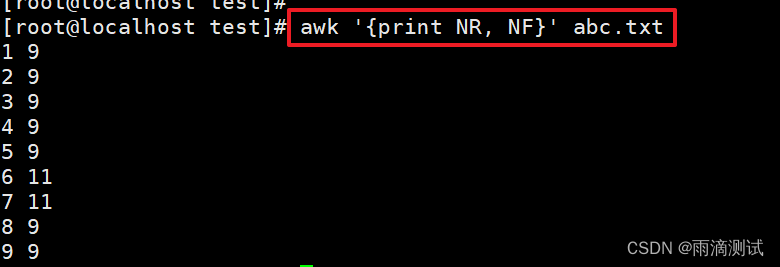
4.将列数大于等于10的行打印出来 ?
5.显示第5,第7行的数据 ?
6.打印出包含etc的行 ?
7.打印出含有etc或者home的行 ?
8.打印输出第二列小于5的行 ?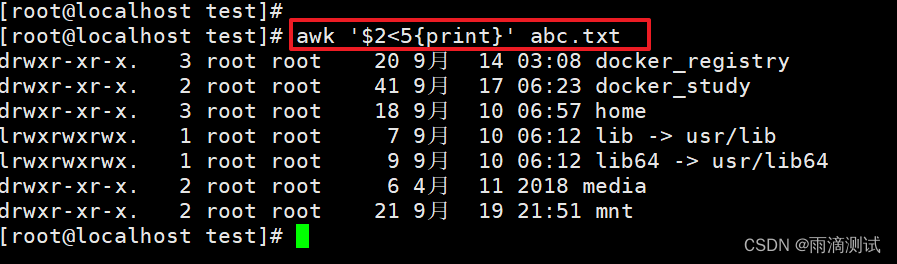
9.打印第一列中不是以目录开头的行 ?
10.显示文件中第9个字段包含dev的行的第1和第9个字段 ?
11.显示文件中第9个字段不包含dev的行的第1和第9个字段 ?
12.如果第2列以两个数字结束就打印这个记录。 ?
13.如果第2列等于1或者第7列小于15,则打印该行。 ?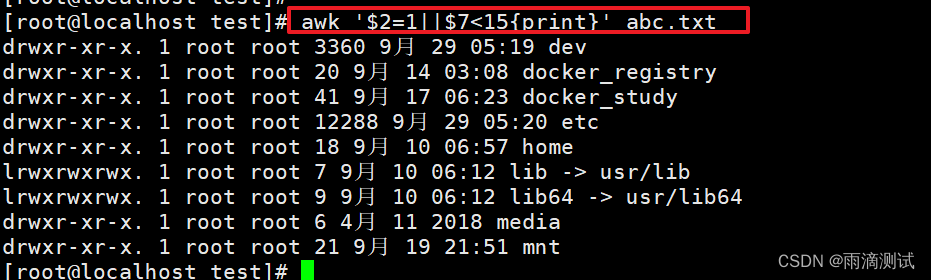
14.如果第2列大于5则打印?后面的表达式值,否则打印冒号后面的表达式值。 ?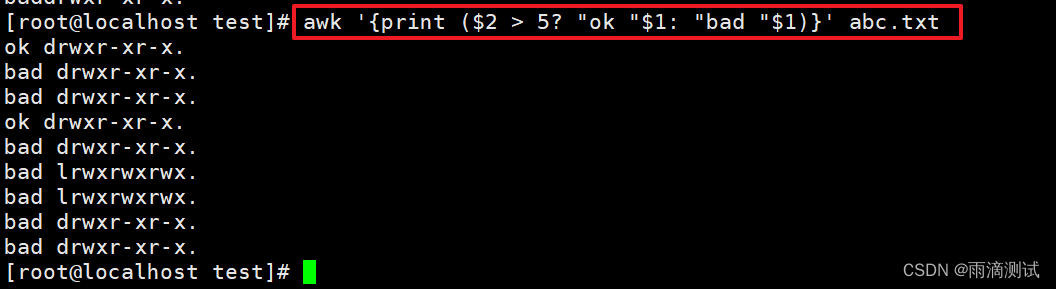
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Docker部署Mysql5.7x和Myslq8.x
- 图像分类任务的targeted和untargeted后门攻击分别指的是什么?
- 身份证和名片图像识别转文字的API选择指南
- 基于高斯过程的贝叶斯优化
- app测试必掌握的核心测试:UI、功能测试!
- 基于深度卷积神经网络的垃圾分类识别系统
- SSD-1B速度革命:文本到图像加速60%
- WPS 删除设备提示:请先清空设备内的文件
- P73 bert奇闻
- Spring MVC 的核心组件