中文医疗大模型的近况
发布时间:2023年12月26日
医疗大模型
- FROM BEGINNER TO EXPERT: MODELING MEDICAL KNOWLEDGE INTO GENERAL LLMS
- Taiyi: A Bilingual Fine-Tuned Large Language Model for Diverse Biomedical Tasks. 2023
- AlpaCare: Instruction-tuned Large Language Models for Medical Application.
- BianQue: Balancing the Questioning and Suggestion Ability of Health LLMs with Multi-turn Health Conversations Polished by ChatGPT
- Qilin-Med: Multi-stage Knowledge Injection Advanced Medical Large Language Model
- Zhongjing: Enhancing the Chinese Medical Capabilities of Large Language Model through Expert Feedback and Real-world Multi-turn Dialogue
FROM BEGINNER TO EXPERT: MODELING MEDICAL KNOWLEDGE INTO GENERAL LLMS
未开源
提出了三阶段训练方法:
- 医疗领域Post- Training
- 通用QA 微调
- 通过C-play 增强下游场景任务。
第一阶段训练数据:
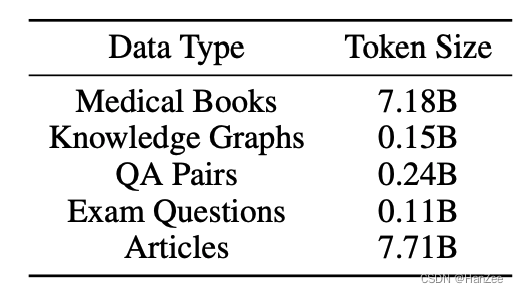
Taiyi: A Bilingual Fine-Tuned Large Language Model for Diverse Biomedical Tasks. 2023
提出了两阶段sft,差不多是大量的低质量多样性预料学习领域知识,医疗数据sft。
开源了数据集清单。
AlpaCare: Instruction-tuned Large Language Models for Medical Application.
提出了类似于self-instruct的医疗数据生成方法,并开源了52k sft data.通过Rouge-L去重。
BianQue: Balancing the Questioning and Suggestion Ability of Health LLMs with Multi-turn Health Conversations Polished by ChatGPT
主张多轮问询CoQ,通过好大夫开源的问答数据,清洗了一遍,然后用ChatGPT润色。
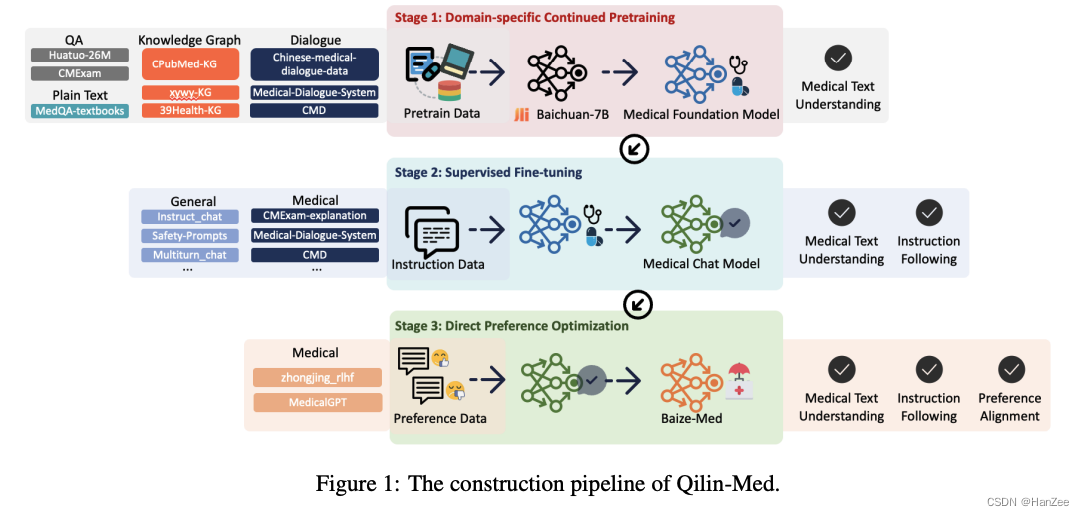
Qilin-Med: Multi-stage Knowledge Injection Advanced Medical Large Language Model
分为三阶段:CPT + SFT + DPO ,公开了使用的数据清单。
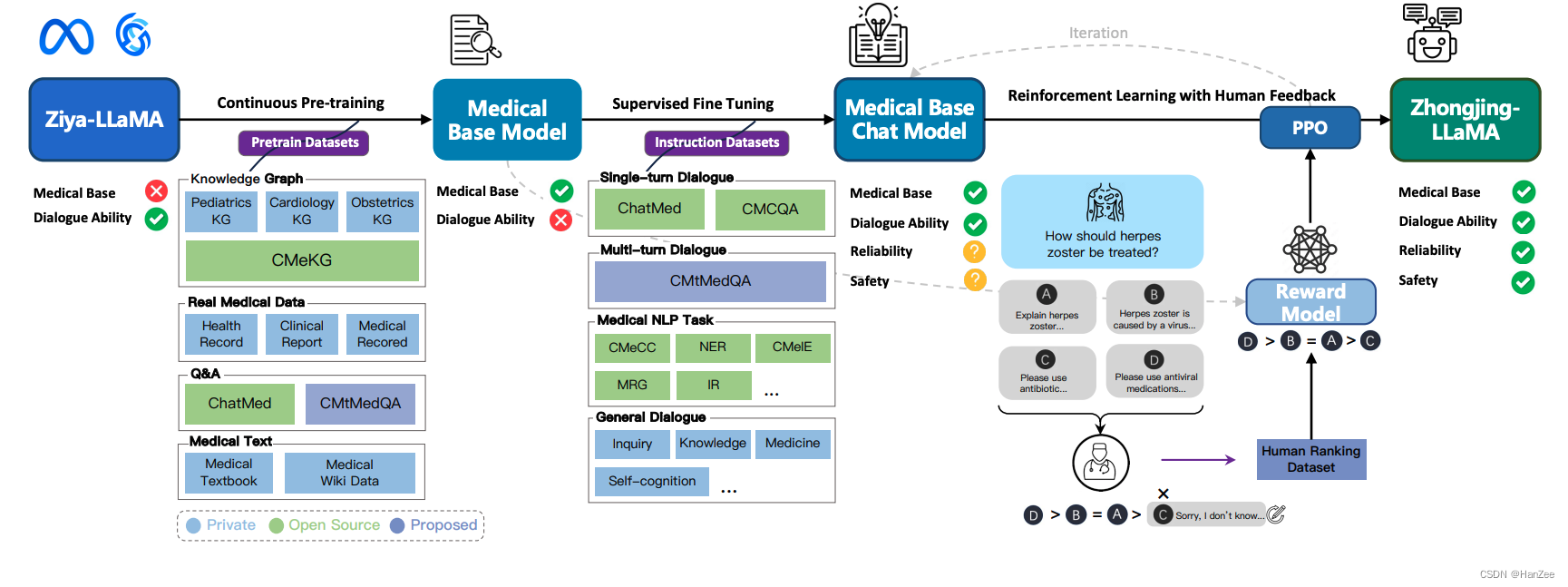
Zhongjing: Enhancing the Chinese Medical Capabilities of Large Language Model through Expert Feedback and Real-world Multi-turn Dialogue
开源了数据清单,跑通了CPT + SFT + PPO
文章来源:https://blog.csdn.net/qq_18555105/article/details/135204671
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 陀螺仪LSM6DSV16X与AI集成(6)----检测自由落体
- 鸿蒙OS应用开发之气泡提示
- 面向对象之深度优先和广度优先
- 你听说过OTA吗?
- 小程序模板大全:从入门到精通,助你开启小程序开发之旅
- 成本零压力,云桥通SD-WAN企业组网助力远程局域网智能组网
- 述职报告一般怎么写?
- 【HarmonyOS】装饰器下的状态管理与页面路由跳转实现
- 启英泰伦推出「离线自然说」,离线语音交互随意说,不需记忆词条
- 网络安全(黑客)自学启蒙