Fluent Bit配置与使用——基于版本V2.2.2
Fluent Bit日志采集终端
文档适用版本:V2.2
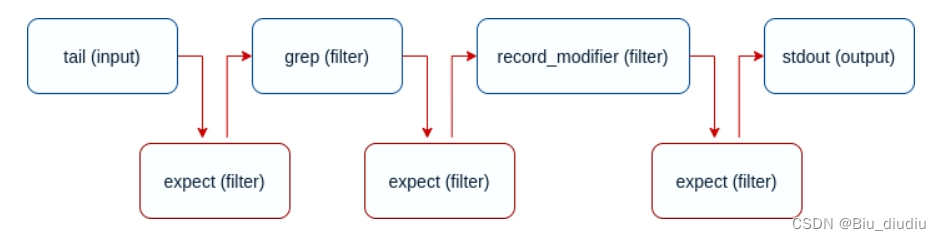
1、日志文件处理流程
数据源是一个普通文件,其中包含 JSON 内容,使用tail插件记录日志,通过parsers进行格式化匹配(图里没写),通过两个筛选器(filter): grep初步排除某些记录,以及record_modifier更改记录内容,添加和删除特定键,最终通过输出器(output)输出。

还可以每个步骤之间添加数据验证检查点,以便了解数据结构是否正确,我们通过使用期望过滤器(expect filter)来实现这一点 。
可选值:
| 参数值 | 描述 |
|---|---|
| key_exists | 检查日志中是否存在Key |
| key_not_exists | 检查日志中是否不存在Key |
| key_val_is_null | 检查Key的值是否为Null |
| key_val_is_not_null | 检查Key的值是否不为Null |
| key_val_eq | 检查Key的值是否等于配置值 |
| action | 不匹配时采取的操作,警告(warn)、退出(exit),警告会记录日志,错误会直接退出(状态码:255) |
示例:
[FILTER]
name expect
match *
key_exists color # color键是否存在
action exit # 不存在直接退出
2、安装流程
RPM包安装
tar zxf fluent-bit_v2.2.2.gz
rpm -ivh libyaml-0.1.4-11.el7_0.x86_64.rpm
rpm -ivh postgresql-libs-9.2.24-9.el7_9.x86_64.rpm
rpm -ivh fluent-bit-2.2.2-1.x86_64.rpm
总配置文件路径:/etc/fluent-bit/fluent-bit.conf
执行文件路径:/opt/fluent-bit/bin/fluent-bit
docker安装
docker pull cr.fluentbit.io/fluent/fluent-bit
kubernetes安装(Helm方式)
# 添加FluentBit Helm库
helm repo add fluent https://fluent.github.io/helm-charts
# 安装默认配置的FluentBit
helm upgrade --install fluent-bit fluent/fluent-bit
3、配置详情
配置 Fluent Bit 的方法之一是使用主配置文件。Fluent Bit 允许使用一个配置文件,该配置文件可以在全局范围内工作。
主配置文件支持 4 种类型的配置段:
Service 全局配置(在这里引入解析器parsers)
Input 输入器
Filter 过滤器
Output 输出器
此外,还可以使用函数将主配置文件拆分为多个文件,以包含外部文件:
Include File
[SERVICE]
flush 1 # 设置引擎将由输入插件进入的记录何时由输出插件输出
daemon Off # Fluent Bit 是否应该作为守护(后台)进程运行
log_file /var/log/fluentbit.log # 可选日志文件的绝对路径。默认情况下,所有日志都输出到标准输出(stdout)
log_level info # 输出的日志级别
parsers_file parsers.conf # 解析器配置文件路径。配置段中可配置多个 Parsers_File 配置项
plugins_file plugins.conf # plugins 配置文件中可定义外部插件的路径。
http_server Off # 是否启用内置 HTTP 服务
http_listen 0.0.0.0 # HTTP 服务启用时,监听地址
http_port 2020 # HTTP 服务的 TCP 端口
[INPUT] # INPUT 配置段定义数据源(与输入插件相关联)。请注意,每个输入插件都可以添加自己的配置项:
name cpu # 输入插件名称(必须项)
tag cpu.local # 与该插件产生的所有记录关联的标签名称
[FILTER] # FILTER 配置段定义一个过滤器(与过滤插件相关联)。请注意,每个过滤插件都可以添加自己的配置项:
Name stdout # 过滤插件名称
Match * # 与传入记录的标签匹配的模式
[OUTPUT] # UTPUT 配置段指定记录标签匹配后的目的地。该配置支持以下配置项
name stdout # 输出插件名称
match * # 匹配输入插件标签
@INCLUDE input-nginx.conf # 调用其它配置文件,避免单文件过长(INPUT、FILTER、OUTPUT字段均可进行外部引入)
4、数据管道
4.1 Input 插入插件
Dummy # 虚拟输入插件,用于生成虚拟事件。它对于测试、调试、基准测试和开始使用 Fluent Bit 非常有用。
HTTP # HTTP 输入插件允许您将自定义记录发送到 HTTP 端点。
Health # Health插件允许您检查 TCP 服务器的健康状况。它通过每隔一定的时间间隔发出一次 TCP 连接来执行检查。
Tail # Tail输入插件允许监控一个或多个文本文件。它具有类似于
tail -f shell命令的行为。
Dummy插件
该插件用于生成虚拟时间记录,主要用于测试、调试。
配置参数
| 键 | 描述 |
|---|---|
| Dummy | 模拟的 JSON 事件记录,默认为 {"message":"dummy"} |
| Rate | 每秒产生的事件数,默认为 1 |
| Interval_sec | 以秒为单位的虚拟基本时间戳。默认值:0 |
| Interval_nsec | 以纳秒为单位的虚拟基本时间戳。默认值:0 |
| Samples | 如果设置有值,则事件的数量将受到限制。例如,如果 Samples=3,插件只生成三个事件并停止。 |
| Copies | 每次生成消息时要生成的消息数。默认值为 1。 |
| Flush_on_startup | 如果设置为 true,则在启动时生成第一个虚拟事件。默认值:false |
| Metadata | 虚拟 JSON 元数据。默认:{} |
| Start_time_sec | 以秒为单位的虚拟基本时间戳。默认值:0 |
| Start_time_nsec | 以纳秒为单位的虚拟基本时间戳。默认值:0 |
示例
[INPUT]
Name dummy
Dummy {"message": "custom dummy"}
[OUTPUT]
Name stdout
Match *
HTTP插件
HTTP 输入插件允许您将自定义记录发送到 HTTP 端点。
配置参数
| 键 | 描述 | 默认值 |
|---|---|---|
| listen | 监听地址 | 0.0.0.0 |
| port | 监听端口 | 9880 |
| tag_key | 指定要覆盖标签的Key值。如果设置,则标记将被键的值覆盖 | 4M |
| buffer_max_size | 指定接收 JSON 消息的最大缓冲区大小(以 KB 为单位)。 | 512K |
| buffer_chunk_size | 设置传入传入 JSON 消息的区块大小。 | |
| successful_response_code | 成功响应代码 | 201 |
| success_header | 添加HTTP头 |
示例
# 模拟http请求
curl -d '{"key1":"value1","key2":"value2"}' -XPOST -H "content-type: application/json" http://localhost:8888/app.log
# 配置文件
[INPUT]
name http
listen 0.0.0.0
port 8888
[OUTPUT]
name stdout
match app.log
Health插件
该插件允许您检查 TCP 服务器的健康状况。它通过每隔一定的时间间隔发出一次 TCP 连接来执行检查。
配置参数
| 键 | 描述 |
|---|---|
| Host | 要检查的目标主机或 IP 地址的名称。 |
| Port | 要检查的目标主机或 IP 地址的端口。 |
| Interval_Sec | 服务检查间隔(以秒为单位)。默认值为 1。 |
| Internal_Nsec | 服务检查指定纳秒间隔,与Interval_Sec配置键结合使用。默认值为 0。 |
| Alert | 如果启用,则仅当探活失败时,它才会生成消息。默认情况下,此选项处于禁用状态。 |
| Add_Host | 将主机名追加到每条记录。默认值为 false。 |
| Add_Port | 将端口号追加到每条记录。默认值为 false。 |
示例
[INPUT]
Name health
Host 127.0.0.1
Port 80
Interval_Sec 1
Interval_NSec 0
[OUTPUT]
Name stdout
Match *
Tail插件
该插件读取 Path 路径下的每个匹配文件,对于找到的每个新行(用换行符 (\n) 分隔),它会生成
一条新记录。或者,可以使用数据库文件(使用Sqlite记录),以便插件可以具有跟踪文件的历史记录
和偏移状态,用于重启后恢复进度。
配置参数
| 键 | 描述 | 默认值 |
|---|---|---|
| Buffer_Chunk_Size | 设置初始缓冲区大小以读取文件数据。此值用于增加缓冲区大小。 | 32k |
| Buffer_Max_Size | 设置每个监控文件的缓冲区大小。如果超过此限制,则将从监控文件列表中删除该文件。 | 32k |
| Path | 通过使用通配符指定一个或多个日志文件的 | |
| Path_Key | 如果启用,它将附加监控文件的名称作为记录的一部分。指定的值成为映射中的键 | |
| Exclude_Path | 文件排除,使用逗号分隔 | |
| Read_from_Head | 从文件的头部读取内容,而不是从文件尾部读取内容。 | False |
| Refresh_Interval | 刷新监控文件列表的时间间隔(秒) | |
| Rotate_Wait | 指定监控文件的额外时间,以防止日志文件滚动丢失某些数据 | |
| Skip_Long_Lines | 当监控的文件由于行(Buffer_Max_Size)很长而达到缓冲区容量时,默认行为是停止监视该文件。 | Off |
| Skip_Empty_Lines | 跳过日志中的空行 | Off |
| DB | 指定跟踪监控文件的偏移量的数据库文件 | |
| DB.Sync | 设置默认sqlite同步方法。 | FULL |
| DB.journal_mode | 设置数据库的日志模式 (WAL)。 | WAL |
| Mem_Buf_Limit | 指定tail插件使用的最大内存,如果达到限制,插件会停止采集,刷新数据后会恢复 | |
| Parser | 指定解析器 | |
| Key | 当消息是非结构化数据时(未应用解析器),消息将以字符串形式作为 log 键的值。此选项允许为该键指定名称 | log |
| Tag | Tag 标识数据源,用于后续处理流程Filter,output时选择数据 | |
| Tag_Regex | 使用通配符方法进行数据源标识 |
示例
[INPUT]
# 使用 tail 插件
Name tail
# Tag 标识数据源,用于后续处理流程Filter,output时选择数据
Tag nginx.*
Path /var/log/nginx/access.log
# 指定解析器
Parser json
Mem_Buf_Limit 15MB
# 初始buffer size
Buffer_Chunk_Size 32k
# 每个文件的最大buffer size
Buffer_Max_Size 64k
# 跳过长度大于 Buffer_Max_Size 的行,Skip_Long_Lines 若设为Off遇到超过长度的行会停止采集
Skip_Long_Lines On
# 监控日志文件 refresh 间隔
Refresh_Interval 10
4.2 Parsers 解析插件
默认情况
使用该插件,将非结构化日志条目格式化为一个具体、统一的结构,使其更容易处理和进一步过滤。
格式化类型:
Json映射
正则匹配 Fluent Bit 使用基于 Ruby 的正则表达式
配置参数
| 键 | 描述 |
|---|---|
| Name | 解析器名称(唯一) |
| Format | 指定解析器格式,选项:JSON、正则、logfmt |
| Regex | 正则表达式 |
| Time_Key | |
| Time_Format | 指定时间字段的格式。 |
| Time_Offset | 为本地日期指定固定的 UTC 时间偏移量(例如 -0600、+0200 等)。 |
| Time_Keep | 启用此选项将使解析器在日志条目中保留原始时间字段及其值。 |
| Skip_Empty_Values | 指定一个布尔值,用于确定解析器是否应跳过空值。默认值为 true。 |
示例
# 原始日志
23-Jan-2024 18:42:06.178 信息 [Periodic background build discarder thread] hudson.model.AsyncPeriodicWork.lambda$doRun$0 Finished Periodic background build discarder. 1 ms
# 解析器
[PARSER]
Name tomcat
Format regex
Regex ^(?<time>\d{2}-\w{3}-\d{4} (.*).(\d{3})) (?<level>[\u4e00-\u9fa5]+) (?<class>\[.*\]) (?<msg>.*)
# 输出日志
## 将原始日志拆为了
### time字段:"23-Jan-2024 18:42:06.178";
### level字段:"信息";
### class字段:"[Periodic background build discarder thread]";
### msg字段:"hudson.model.AsyncPeriodicWork.lambda$doRun$0 Finished Periodic background build discarder. 1 ms"
{
"_time_":"2024-01-23T10:42:06.178810Z"
"time":"23-Jan-2024 18:42:06.178"
"level":"信息"
"class":"[Periodic background build discarder thread]"
"msg":"hudson.model.AsyncPeriodicWork.lambda$doRun$0 Finished Periodic background build discarder. 1 ms"
}
多行情况
多行解析器(Multiline Parser)默认内置了以下几种:
| 解析器 | 描述 |
|---|---|
| docker | 处理 Docker 容器引擎生成的日志条目。此解析器支持由 Docker 拆分的日志条目的串联。 |
| cri | 处理 CRI-O 容器引擎生成的日志条目。与 docker 解析器类似,用于解析containerd的日志 |
| go | 处理基于 Go 的语言应用程序生成的日志条目,并在检测到多行消息时执行串联。 |
| python | 处理基于 Python 的语言应用程序生成的日志条目,并在检测到多行消息时执行串联。 |
| java | 处理由 Java 语言应用程序生成的日志条目,并在检测到多行消息时执行串联。 |
可自定义的多行匹配规则
| 键 | 描述 | 默认值 |
|---|---|---|
| name | 为多行解析器指定名称 | |
| type | 设置多行解析模式,一般为:regex正则 | |
| parser | 事先定义解析器。注意:当解析器应用于原始文本时,正则表达式将使用 key_content 配置属性应用于结构化消息的特定键(见下文)。 | |
| key_content | 对于传入的结构化消息,请指定包含应由正则表达式处理并可能连接的数据的键。 | |
| flush_timeout | 超时刷新时间 | 5s |
| rule | 定义多行匹配规则,可定义多个规则,但存在一定使用规定。 |
Rule规则的定义
一条规则由四部分组成
# 规则名 | 状态名称 | 正则规则 | 下一步状态
rules | state name | regex pattern | next state
# 第一步必须为“start_state”,正则与多行文本的首行匹配
rule "start_state" "/([a-zA-Z]+ \d+ \d+\:\d+\:\d+)(.*)/" "cont"
4.3 Filters 过滤插件
官方文档:Expect - Fluent Bit: Official Manual
多个Filier过滤器顺序执行
CheckList插件
该插件会查找指定列表中的值是否存在,然后允许添加记录以告知是否找到。
配置参数
| 键 | 描述 |
|---|---|
| file | 关键字匹配文件 |
| lookup_key | 日志文件中需要查找的字段 |
| record | 当在lookup_key字段中查到对应值时要添加的值。value:键 值 |
| mode | 设置检查模式。 支持精准exact和模糊partial。默认值:exact。 |
| ignore_case | 是否忽略大小写。默认:false |
示例:
[INPUT]
name tail
tag test1
path test1.log
read_from_head true
parser json
[FILTER]
name checklist
match test1
# 在日志中查找含有文件中包含关键字的部分
file ip_list.txt
# 关键字所在字段
lookup_key $remote_addr
# 添加/替换(这里为:将`ioc`字段的值替换为abc)
record ioc abc
[OUTPUT]
name stdout
match test1
Grep插件
该插件允许您根据值或嵌套值的正则表达式模式匹配或排除特定记录。
配置参数
| 键 | 格式 | 描述 |
|---|---|---|
| Regex | key regex | 仅保留与正则表达式匹配的字段的记录 |
| Exclude | key regex | 排除与正则表达式匹配的字段的记录 |
| Logical_Op | Operation | Specify which logical operator to use. AND , OR and legacy are allowed as an Operation. Default is legacy for backward compatibility. In legacy mode the behaviour is either AND or OR depending whether the grep is including (uses AND) or excluding (uses OR). Only available from 2.1+. |
示例
[INPUT]
name tail
path lines.txt
parser json
[FILTER]
name grep
match *
# 仅保留log字段值为aa的日志
regex log aa
[OUTPUT]
name stdout
match *
Lua插件
用于应用lua脚本
Lua - Fluent Bit: Official Manual
Parser插件(常用)
该插件用于解析事件记录中的字段。
配置参数
| 键 | 描述 | 默认值 |
|---|---|---|
| Key_Name | 指定要解析的日志中的具体字段名称。 | |
| Parser | 指定解析器名称,允许多个解析器条目(每行一个)。 | |
| Preserve_Key | 是否保留原始字段(Key_Name里写的) | False |
| Reserve_Data | 是否保留其它原始字段 | False |
示例
# 原始日志
{"data":"100 0.5 true This is example"}
# 解析器
[PARSER]
Name dummy_test
Format regex
Regex ^(?<INT>[^ ]+) (?<FLOAT>[^ ]+) (?<BOOL>[^ ]+) (?<STRING>.+)$
# 过滤器
[FILTER]
Name parser
Match dummy.*
Key_Name data
Parser dummy_test
# 输出
[0] dummy.data: [1499347993.001371317, {"INT"=>"100", "FLOAT"=>"0.5", "BOOL"=>"true", "STRING"=>"This is example"}]
Record Modifier插件
Record Modifier插件允许附加字段或排除特定字段。
配置参数
| 键 | 描述 |
|---|---|
| Record | 追加字段。值为键值对 |
| Remove_key | 如果键匹配,则删除。(黑名单)值为:mem.total |
| Allowlist_key | 如果键不匹配,则删除。(白名单)值为:mem.total |
| Uuid_key | 如果设置,插件会将 uuid 附加到每条记录。分配的值将成为映射中的键。 |
示例
# 原始记录
{"Mem.total"=>1016024, "Mem.used"=>716672, "Mem.free"=>299352, "Swap.total"=>2064380, "Swap.used"=>32656, "Swap.free"=>2031724}
# 追加
[FILTER]
Name record_modifier
Match *
Record hostname ${HOSTNAME}
Record product Awesome_Tool
# 删除Swap.used
[FILTER]
Name record_modifier
Match *
Remove_key Swap.used
# 仅保留Swap.used
[FILTER]
Name record_modifier
Match *
Allowlist_key Swap.used
Modify插件(常用)
详情:修改 - Fluent Bit: Official Manual
Multiline插件(常用)
该插件主要用于上下文拆分为多个日志行的消息进行合并。
默认支持格式:
GO
Python
Ruby
Java(Google Cloud Platform Java stacktrace format)
配置参数
| 键 | 描述 |
|---|---|
| multiline.parser | 指定一个或多个多行解析器,通过逗号分隔 |
| multiline.key_content | 用于保存处理后内容键的名称。 |
| mode | |
| buffer | 启用缓冲模式。在缓冲模式下,筛选器可以从逐个引入记录的输入中连接多行(例如:转发),而不是以块的形式连接 |
| flush_ms | 挂起的多行记录的刷新时间。默认值为 2000。 |
| emitter_name | |
| emitter_storage.type | |
| emitter_mem_buf_limit |
示例
test.log通过tail插件输入,接着进入parsers_multiline.conf进行多行解析,然后调用multiline进行多行过滤,最终输出。
[SERVICE]
flush 1
log_level info
parsers_file parsers_multiline.conf
[INPUT]
name tail
path test.log
read_from_head true
[FILTER]
name multiline
match *
multiline.key_content log
multiline.parser go, multiline-regex-test
[OUTPUT]
name stdout
match *
Nest插件
Nest 插件允许您对嵌套数据进行操作或处理嵌套数据。
配置参数
| 键 | 值格式 | 描述 |
|---|---|---|
| Operation | nest / lift | 选择操作:嵌套(nest)或拆解(lift) |
| Wildcard | 通配符 | 记录哪个字段需要进行嵌套(nest) |
| Nest_under | 字符串 | 记录新嵌套字段的键名称 |
| Nested_under | 字符串 | 取消嵌套(lift)的嵌套字段的键名称 |
| Add_prefix | 字符串 | 使用此字符串作为受影响的键的前缀(在Key前加文本) |
| Remove_prefix | 字符串 | 如果前缀与此字符串匹配,请从受影响的键中删除前缀 |
示例
# 原始文本:{"Mem.total"=>3865308, "Mem.used"=>3648492, "Mem.free"=>216816, "Swap.total"=>4194300, "Swap.used"=>1065856, "Swap.free"=>3128444}
[INPUT]
Name mem
Tag mem.local
[OUTPUT]
Name stdout
Match *
# 将所有Mem.*嵌套在LAYER1下
# 输出为:{"Swap.total"=>4194300, "Swap.used"=>1065888, "Swap.free"=>3128412, "LAYER1"=>{"Mem.total"=>3865308, "Mem.used"=>3643692, "Mem.free"=>221616}
[FILTER]
Name nest
Match *
Operation nest
Wildcard Mem.*
Nest_under LAYER1
[FILTER]
Name nest
Match *
Operation nest
Wildcard LAYER1*
Nest_under LAYER2
# 取消LAYER2字段嵌套,并在下一级LAYER1前新增Lifted2_
# 输出为:{"Swap.total"=>4194300, "Swap.used"=>1065680, "Swap.free"=>3128620, "Lifted2_LAYER1"=>{"Mem.total"=>3865308, "Mem.used"=>3688680, "Mem.free"=>176628}}
[FILTER]
Name nest
Match *
Operation lift
Nested_under LAYER2
Add_prefix Lifted2_
# 新增LAYER3嵌套,并删除上一级字段Lifted2_前缀
# 输出为:{"Swap.total"=>4194300, "Swap.used"=>1066244, "Swap.free"=>3128056, "LAYER3"=>{"LAYER1"=>{"Mem.total"=>3865308, "Mem.used"=>3660424, "Mem.free"=>204884}}}
[FILTER]
Name nest
Match *
Operation nest
Wildcard Lifted2_*
Nest_under LAYER3
Remove_prefix Lifted2_
Kubernetes插件
kubernetes 过滤器插件允许使用元数据丰富您的日志文件。
当 Fluent Bit 作为 DaemonSet 部署在 Kubernetes 并配置为从容器(使用 tail 或 systemd 输入插件)读取日志时,此过滤器可以执行以下操作:
分析 Tag 标签并提取以下元数据:
Pod Name
Namespace
Container Name
Container ID
查询 Kubernetes API Server 以获取有关 Pod 的额外元数据:
Pod ID
Labels
Annotations
数据将会缓存在本地内存中,并附加到每个日志记录上。
详情:Kubernetes - Fluent Bit:官方手册
示例
[FILTER]
# 使用kubernetes过滤器
Name kubernetes
# 匹配ingress.*这个Tag对应的 INPUT
Match ingress.*
# kubernetes API Server 地址
Kube_URL https://kubernetes.default.svc:443
# kubernetes 上serviceAccount的CA证书路径
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
# kubernetes 上serviceAccount的token路径
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
# 当源日志来自tail插件,这个配置用于指定tail插件使用的前缀值
Kube_Tag_Prefix ingress.var.log.containers.
# Merge_Log=On 解析log字段的json内容,提取到根层级, 附加到Merge_Log_Key指定的字段上
Merge_Log Off
# 合并log字段后是否保持原始log字段
Keep_Log Off
# 允许Kubernetes Pod 建议预定义的解析器
K8S-Logging.Parser Off
# 允许Kubernetes Pod 从日志处理器中排除其日志
K8S-Logging.Exclude Off
# 是否在额外的元数据中包含 Kubernetes 资源标签信息
Labels Off
# 是否在额外的元数据中包括 Kubernetes 资源信息
Annotations Off
4.4 Output 输出插件
Amazon S3
详情:Amazon S3 – Fluent Bit:官方手册
Elasticsearch
详情:Elasticsearch - Fluent Bit:官方手册
输出至文件
配置参数
| 键 | 描述 | 默认值 |
|---|---|---|
| Path | 用于存储文件的目录路径。 | |
| File | 设置用于存储记录的文件名。 | |
| Format | 文件内容的格式。(out_file、JSON、CSV、LTSV、Template) | out_file |
| Mkdir | 是否递归创建输出目录。 | |
| Workers | 专用线程数量 | 1 |
HTTP
详情:HTTP - Fluent Bit: Official Manual
kafka
详情:Kafka - Fluent Bit: Official Manual
示例
[OUTPUT]
# 使用kafka插件
Name kafka
# 匹配Nginx access日志
Match tomcat.*
# 指定Kafka Brokers地址
Brokers 192.168.142.12:9092
# 指定Kafka topic,如果需要推送到多个topic,多个topic通过','分隔
Topics fluentBit-tomcat-topic
# 将Timestamp_Key设置为_time_,原默认值为@timestamp
Timestamp_Key _time_
# 指定时间戳转成成的时间字符串格式
Timestamp_Format iso8601
# 设置为false表示不限制重试次数
Retry_Limit false
# 当kafka结束空闲连接时,隐藏"Receive failed: Disconnected"报错
rdkafka.log.connection.close false
# Kafka生产者队列中总消息容量最大值,此处设置为10MB,producer buffer is not included in http://fluentbit.io/documentation/0.12/configuration/memory_usage.html#estimating
rdkafka.queue.buffering.max.kbytes 10240
# Kafka生产者在leader已成功收到的数据并得到确认后才发送下一条message。
rdkafka.request.required.acks 1
5、配置实例
Nginx
输入日志:"192.168.142.1 - - [22/Jan/2024:08:25:24 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36" "-" "
[PARSER]
Name nginx
Format regex
Regex ^(?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)")
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
[INPUT]
Name tail
Tag nginx.*
Path /var/log/nginx/access.log
Parser json
Mem_Buf_Limit 15MB
Buffer_Chunk_Size 32k
Buffer_Max_Size 64k
Skip_Long_Lines On
Refresh_Interval 10
[OUTPUT]
Name kafka
Match nginx.*
Brokers 192.168.142.12:9092
Topics fluentBit-nginx-topic
Timestamp_Key _time_
Timestamp_Format iso8601
Retry_Limit false
rdkafka.log.connection.close false
rdkafka.queue.buffering.max.kbytes 10240
rdkafka.request.required.acks 1
输出:
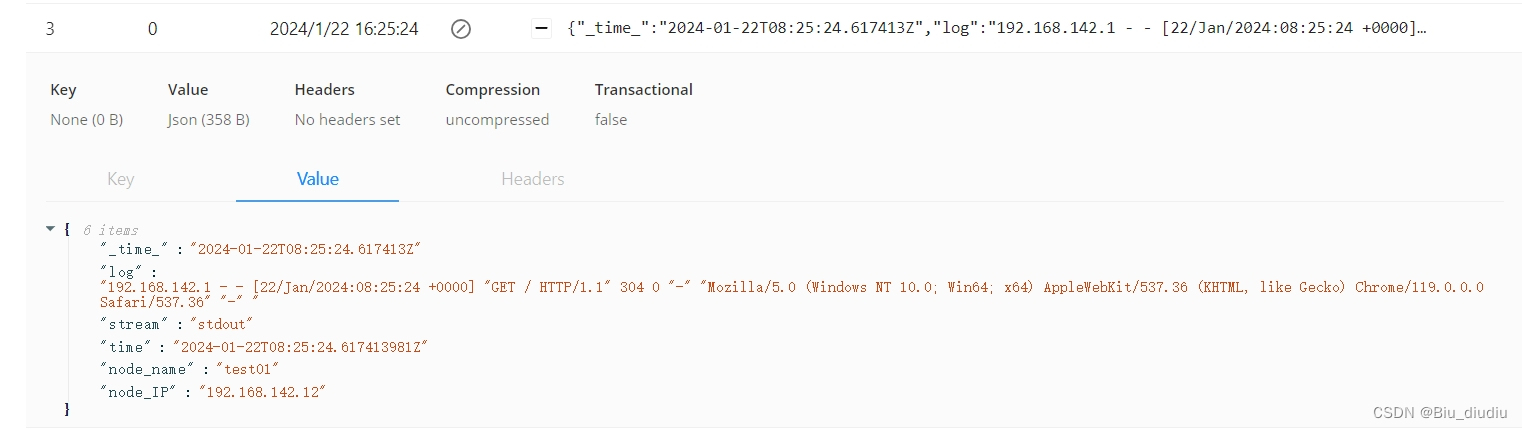
Tomcat
输入日志:[INFO ] 2024-01-22 01:42:32,748 --http-nio-8080-exec-7-- [com.hylh.mobile.biz.mq.sender.impl.QueueSenderServiceImpl] 测试发送结束
[MULTILINE_PARSER]
Name multiline-tomcat
Type regex
Flush_timeout 1000
rule "start_state" "/^(?<level>\[ERROR\]) (?<time>\d{4}-\d{2}-\d{2} (.*),(\d{3})) (?<thread>--(.*)--) (?<class>\[\w(.*).\w\]) (?<message>(.*))/" "cont"
rule "cont" "/(^com|org|java).\w(.*).\w(.*): \w(.*)/" "cont"
rule "cont" "/\s+at.*/" "cont"
[INPUT]
Name tail
Tag tomcat.*
Path /opt/apache-tomcat-8.5.88/logs/catalina.out
Parser tomcat
Mem_Buf_Limit 15MB
Buffer_Chunk_Size 32k
Buffer_Max_Size 64k
Skip_Long_Lines On
Refresh_Interval 5
[FILTER]
name multiline
match tomcat.*
multiline.key_content log
multiline.parser multiline-tomcat
[OUTPUT]
Name kafka
Match tomcat.*
Brokers 192.168.142.12:9092
Topics fluentBit-tomcat-topic
Timestamp_Key _time_
Timestamp_Format iso8601
Retry_Limit false
rdkafka.log.connection.close false
rdkafka.queue.buffering.max.kbytes 10240
rdkafka.request.required.acks 1
Docker-Tomcat
输入日志:{"log":"[ERROR] 2024-01-22 08:53:22,090 --schedule-pool-6-- [com.rx.common.utils.Threads] Invalid bound statement (not found): com.test.system.mapper.store.sytem.SysStoreOperLogMapper.insertOperlog \r\n","stream":"stdout","time":"2024-01-22T00:53:22.092252133Z"}
[MULTILINE_PARSER]
Name multiline-tomcat
Type regex
Flush_timeout 1000
rule "start_state" "/^(?<level>\[ERROR\]) (?<time>\d{4}-\d{2}-\d{2} (.*),(\d{3})) (?<thread>--(.*)--) (?<class>\[\w(.*).\w\]) (?<message>(.*))/" "cont"
rule "cont" "/(^com|org|java).\w(.*).\w(.*): \w(.*)/" "cont"
rule "cont" "/\s+at.*/" "cont"
[PARSER]
Name get_level
Format regex
Regex (?<level>\[\w{4,5} *\])
[INPUT]
Name tail
Tag dockerTomcat.*
Path /opt/test-json.log
Read_from_head true
Mem_Buf_Limit 15MB
# 指定多行匹配,先按照docker模式进行分割
multiline.parser docker, cri
Buffer_Chunk_Size 32k
Buffer_Max_Size 64k
Skip_Long_Lines On
Refresh_Interval 5
[FILTER]
name multiline
match dockerTomcat.*
multiline.key_content log
multiline.parser multiline-tomcat
[FILTER]
Name parser
match dockerTomcat.*
Key_Name log
Parser get_level
Reserve_Data True
Preserve_Key True
[OUTPUT]
Name kafka
Match dockerTomcat.*
Brokers 192.168.142.12:9092
Topics fluentBit-docker-tomcat-topic
Timestamp_Key _time_
Timestamp_Format iso8601
Retry_Limit false
rdkafka.log.connection.close false
rdkafka.queue.buffering.max.kbytes 10240
rdkafka.request.required.acks 1
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Arduino驱动AS3935数字闪电传感器(闪电传感器)
- Spring IOC 与 AOP 基础原理,一篇搞定
- 基于Java SSM框架实现员工婚恋交友平台项目【项目源码+论文说明】
- 力扣算法-Day16
- QLExpress
- 【LeetCode】101. 对称二叉树(简单)——代码随想录算法训练营Day15
- x-cmd pkg | tmux - 开源终端多路复用器(terminal multiplexer)
- Java医生咨询系统(源码+开题)
- 华为鸿蒙应用--Toast工具(鸿蒙工具)-ArkTs
- 在 Mac 上轻松安装和配置 JMeter