真香!EasyExcel实现Excel百万级数据导入导出,高效低内存占用
真香!EasyExcel实现Excel百万级数据导入导出,高效低内存占用
一、简介
高效地读取和处理Excel文件对于任何处理数据的系统来说都是至关重要的。本文将以Apache POI和EasyExcel这两款热门工具为例,探讨它们处理大数据量Excel的能力以及优缺点,并深入理解百万级别Excel高效解析读取的实现策略。
Apache POI和EasyExcel都是处理Excel的优秀框架。POI强大且功能齐全,支持对Word、Excel和PowerPoint等多种文档格式的读写。EasyExcel,如其名,专注于Excel处理,并着重优化了对大规模数据的处理性能。两者的核心区别在于处理大数据的策略,Apache POI主要采取的是基于用户模式的处理方式,EasyExcel则主要采用的是基于事件模式的处理方式。
二、基于用户模式的处理方式(Apache POI)
Apache POI在处理Excel时,会将整个工作表加载到内存中,然后遍历每个单元格来读取数据。这种方式的优点是处理速度快、代码容易编写,能够支持复杂的数据处理,如公式计算、样式调整等。
然而,它的缺点同样明显。首先,将整个工作表加载到内存中会有很大的内存消耗,消耗内存可能是上传文件的大小的100多倍,对稍大些的Excel文件或者服务器压力较大的情况下,可能导致内存溢出。其次,整个工作表必须全部读取完毕,数据才能开始处理,这在处理大型Excel时非常耗时。
// 示例代码
Workbook workbook = new XSSFWorkbook(new FileInputStream(file));
Sheet sheet = workbook.getSheetAt(0);
for (Row row : sheet) {
for (Cell cell : row) {
// do something
}
}
三、基于事件模式的处理方式(EasyExcel)
与Apache POI不同,EasyExcel并不会将整个工作表加载到内存中。而是采用流的形式,一边读取一边处理。这极大地节省了内存消耗,同时由于数据在读取的同时就开始处理,所以在时间效率上也有显著提升。

但EasyExcel的这种方式也有其局限性,由于数据是流式处理,一旦读取过的数据就无法再获取,所以对Excel的操作就显得比较受限,比如无法进行样式调整等操作。
// 示例代码
EasyExcel.read(file, Data.class, new AnalysisEventListener<Data>() {
@Override
public void invoke(Data data, AnalysisContext context) {/*do something*/}
}).sheet().doRead();
四、高效解析百万级Excel
对于百万级的Excel数据,我们往往不能接受其占用大量内存或者处理时间过长的问题。因此,事件模式的处理方式更适合这种情况。即使Apache POI也提供了基于事件模式的API,但由于其API使用起来相对复杂,对于大部分简单的数据处理任务,我们更推荐EasyExcel。只有当你需要进行复杂的样式调整或公式计算时,才需要考虑Apache POI。
同时,我们可以借鉴数据库对大数据的处理思想,将大数据分批次处理,每次只处理一部分数据。这样既可以降低内存消耗,又可以更好地控制处理进度。
对于百万级别的Excel数据,我们推荐使用基于事件模式的处理方式,如EasyExcel,以实现高效的数据解析和读取。
实测
我们可以通过代码示例和相关的内存监控来进一步明白Apache POI和EasyExcel的处理区别。下面我们用一个文件大小为78.1M,数据量为255999条记录,每行有73列的Excel文件进行实战分析。
Apache POI读取Excel:
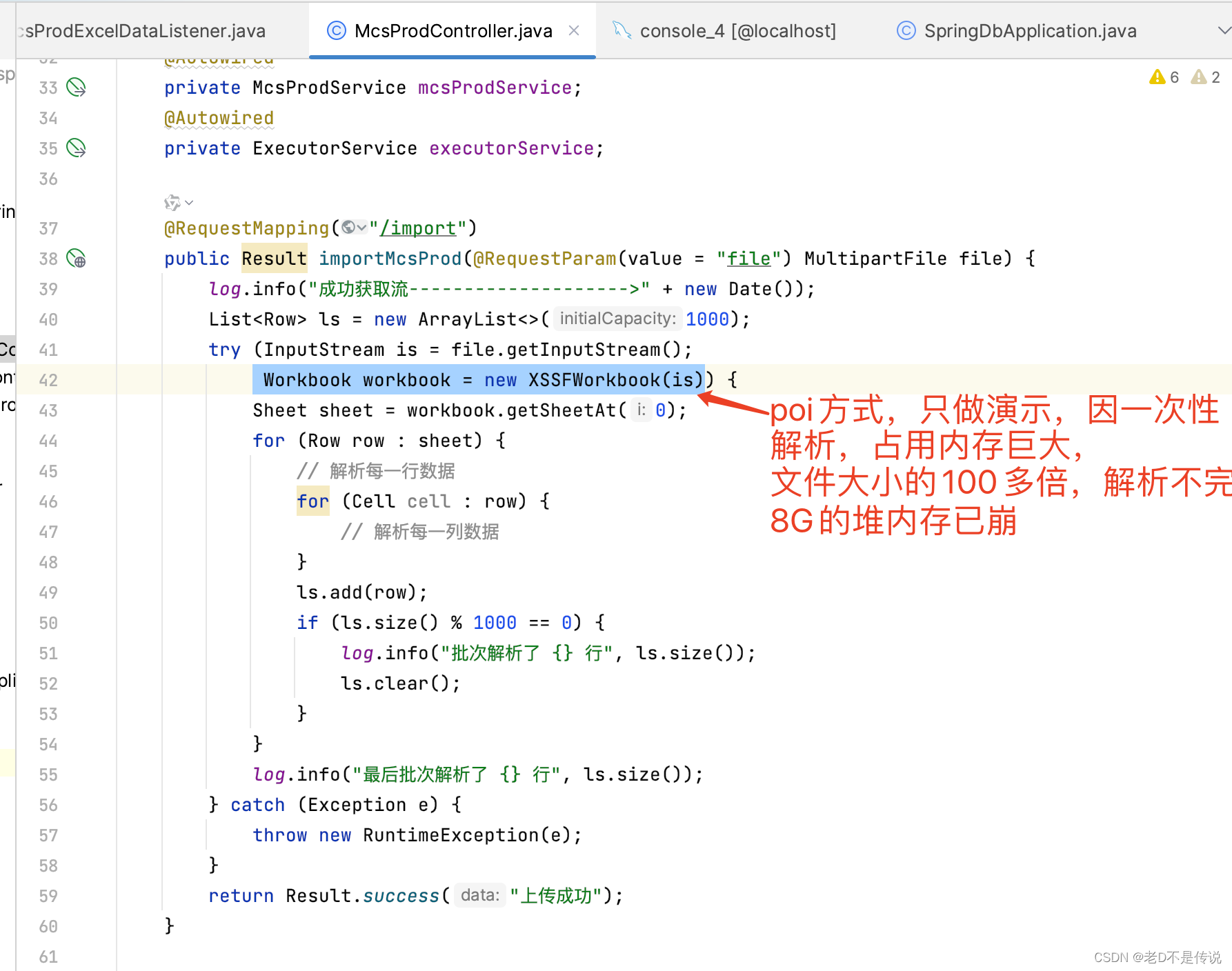
1,因poi一次性解析,并且使用的堆内存暴增100多倍,在8G的堆内存下,导入的excel无法完成解析,代码只做示例,解析输出,无业务,如下所示:
2,应用启动,无导入操作时,内存监控情况,可以看到,堆内存使用100M左右,如下图:

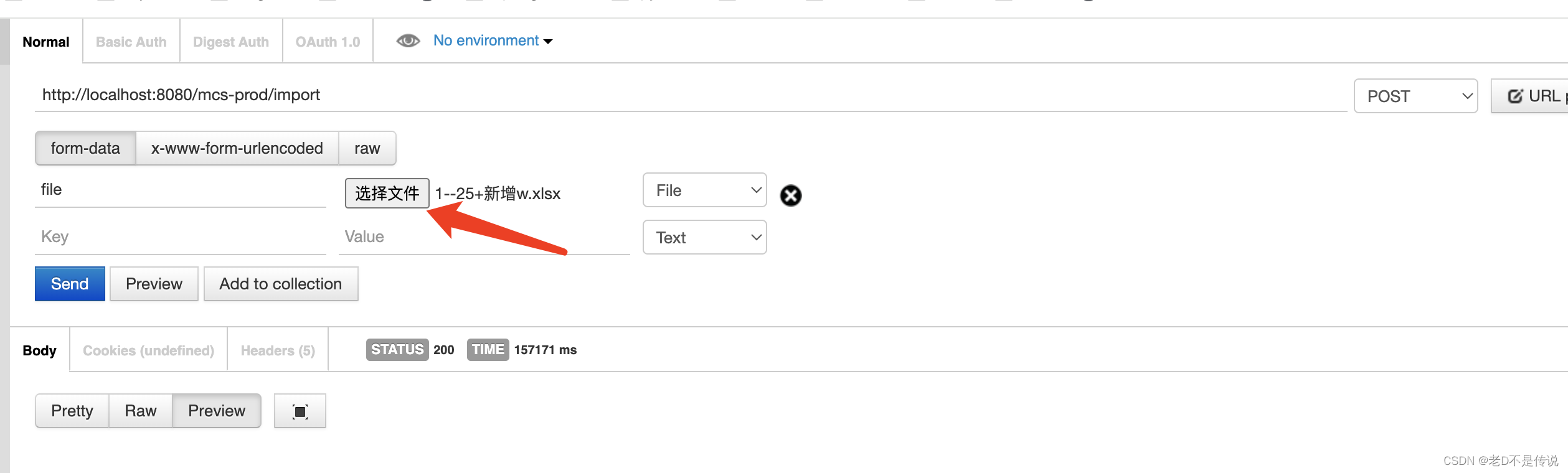
3,使用post,上传文件,文件大小78.1M。
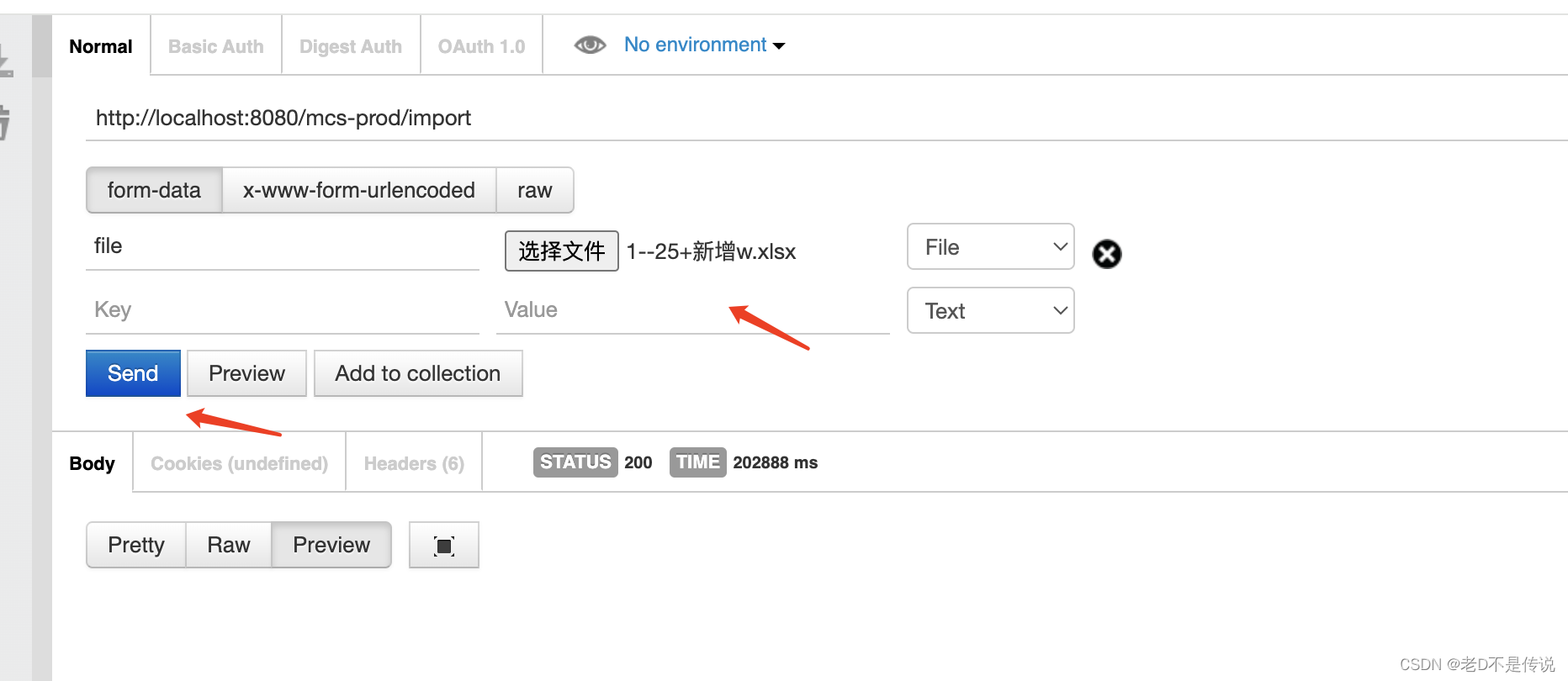
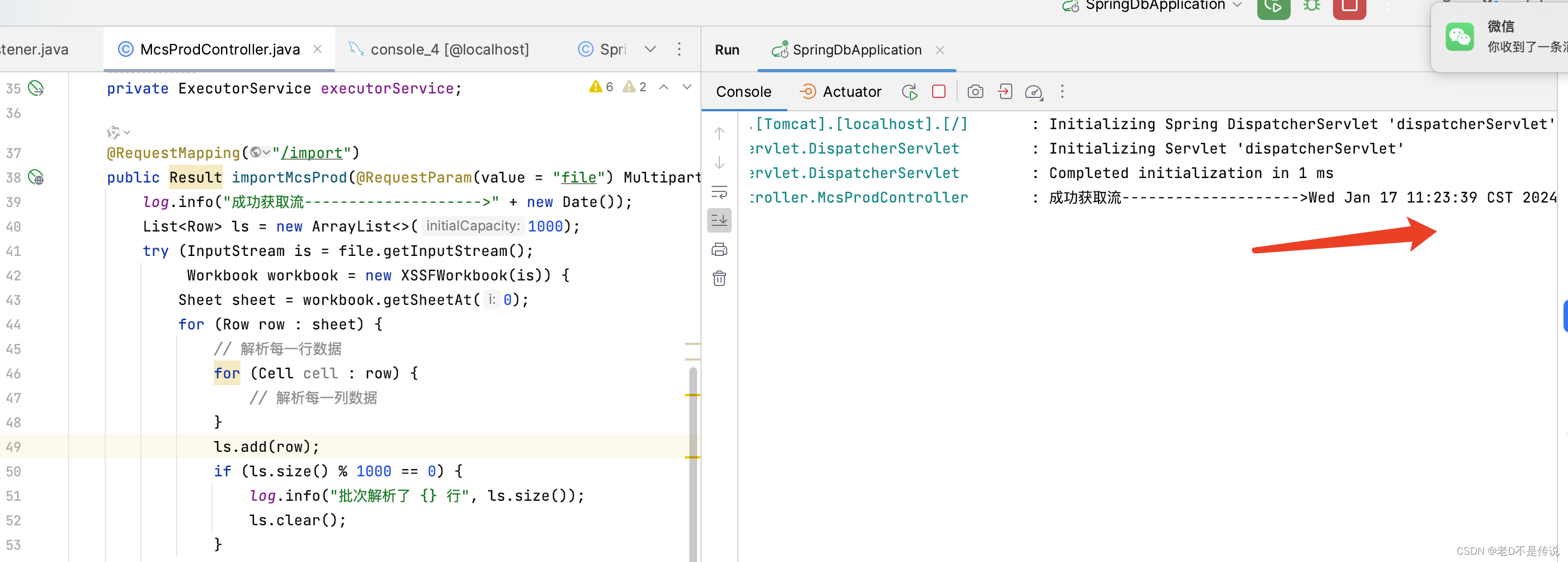
4,导入文件后,应用系统获取文件流,然后开始一次性解析excel文件内容,如下图日志:
5,从监控中看到堆内存使用一直在爆涨,直到涨到堆内存最大值8G,然后经过几轮FGC,仍无法释放堆内存,应用直接挂掉,报内存不足异常。如下图所示:

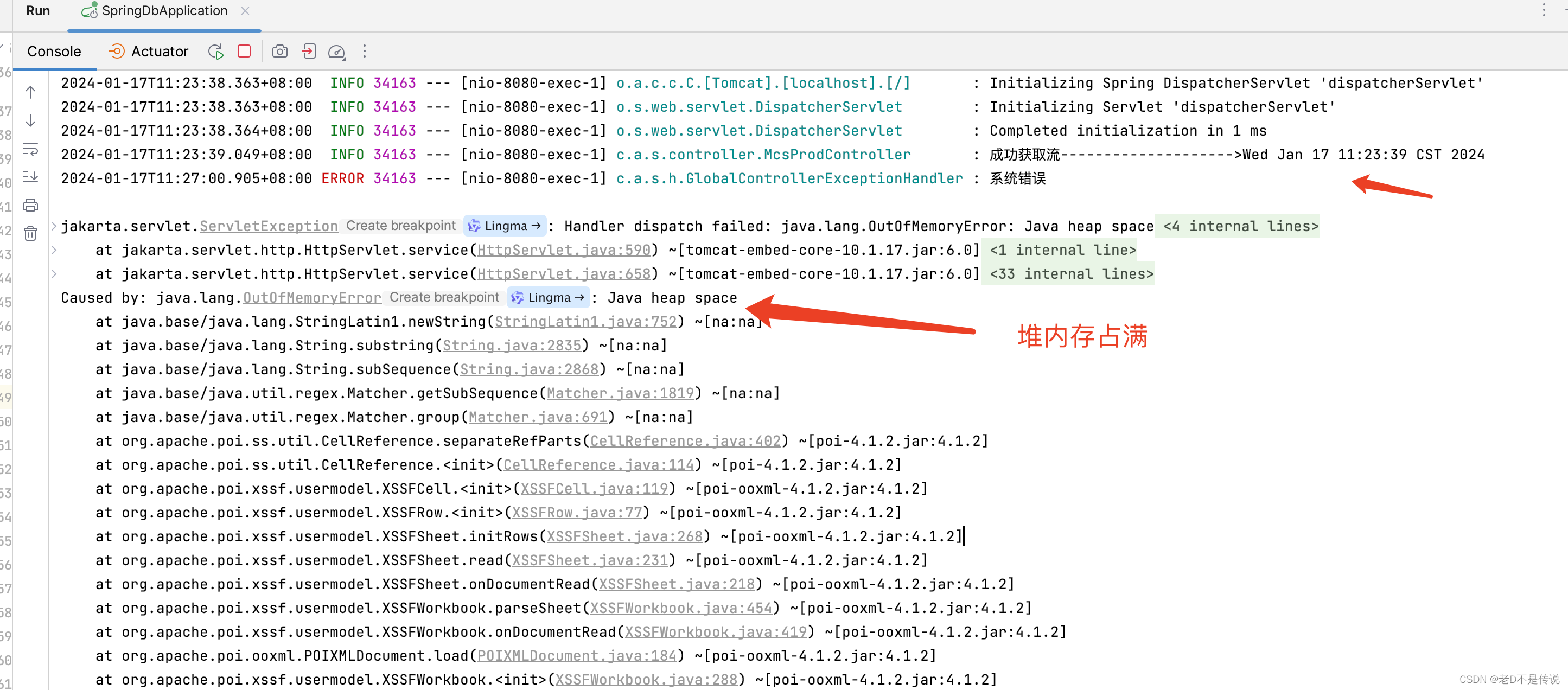
根据以上实测,POI在处理Excel时,整个工作簿都被加载进内存,可以发现内存的剧烈飙升,占用堆内存超过原始文件大小100多倍,对于稍大些的excel处理,很容易就出现内存溢出的状况。
EasyExcel读取Excel:
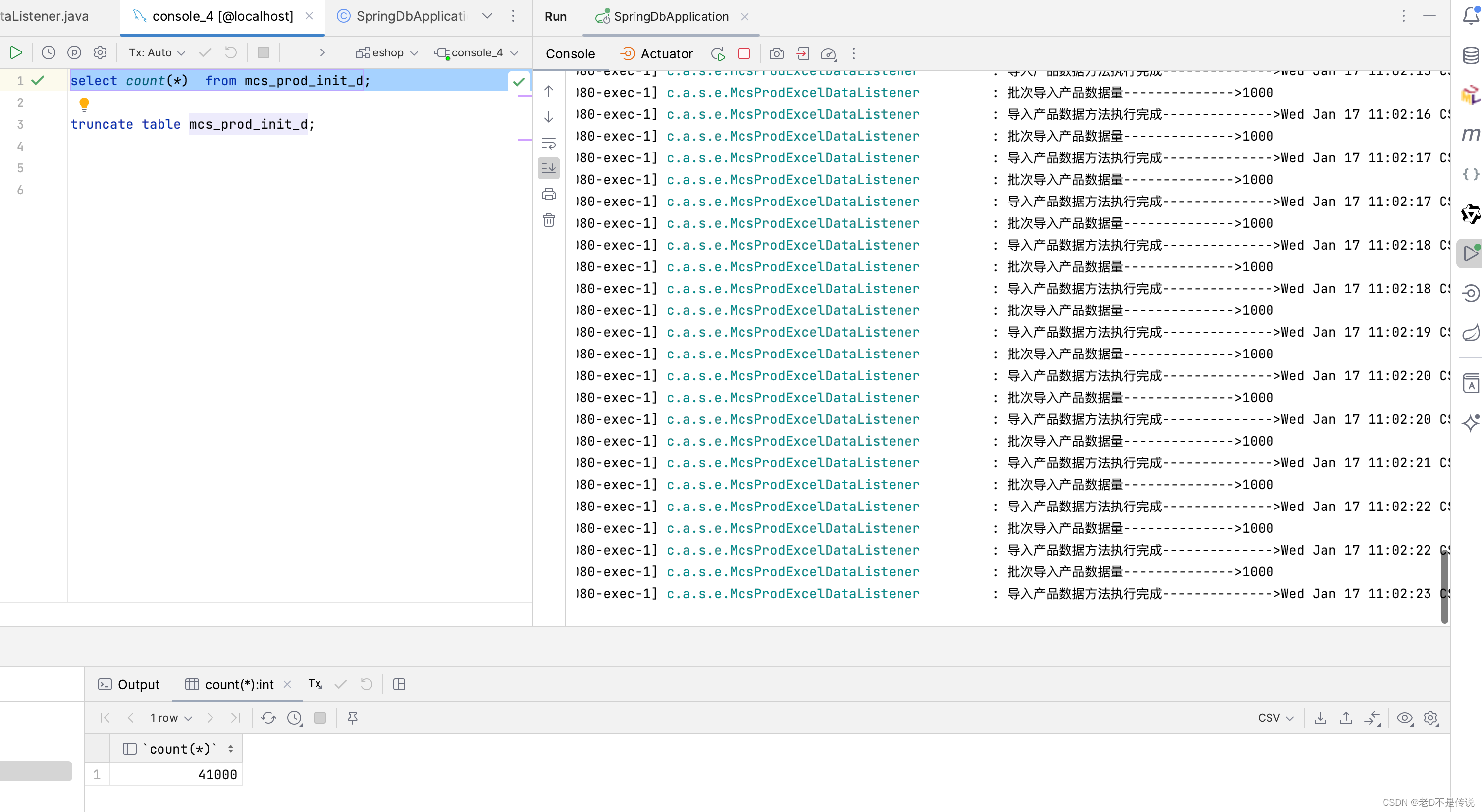
1,同样的文件,excel解析完,做了业务实现,批量入库,批量入库操作使用线程池包含10个线程,进行处理,如下所示:

2,每解析1000行数据,提交给线程池进行异步执行。


3,应用启动,未上传文件时,监控情况如下,系统占用堆内存大小150M左右。
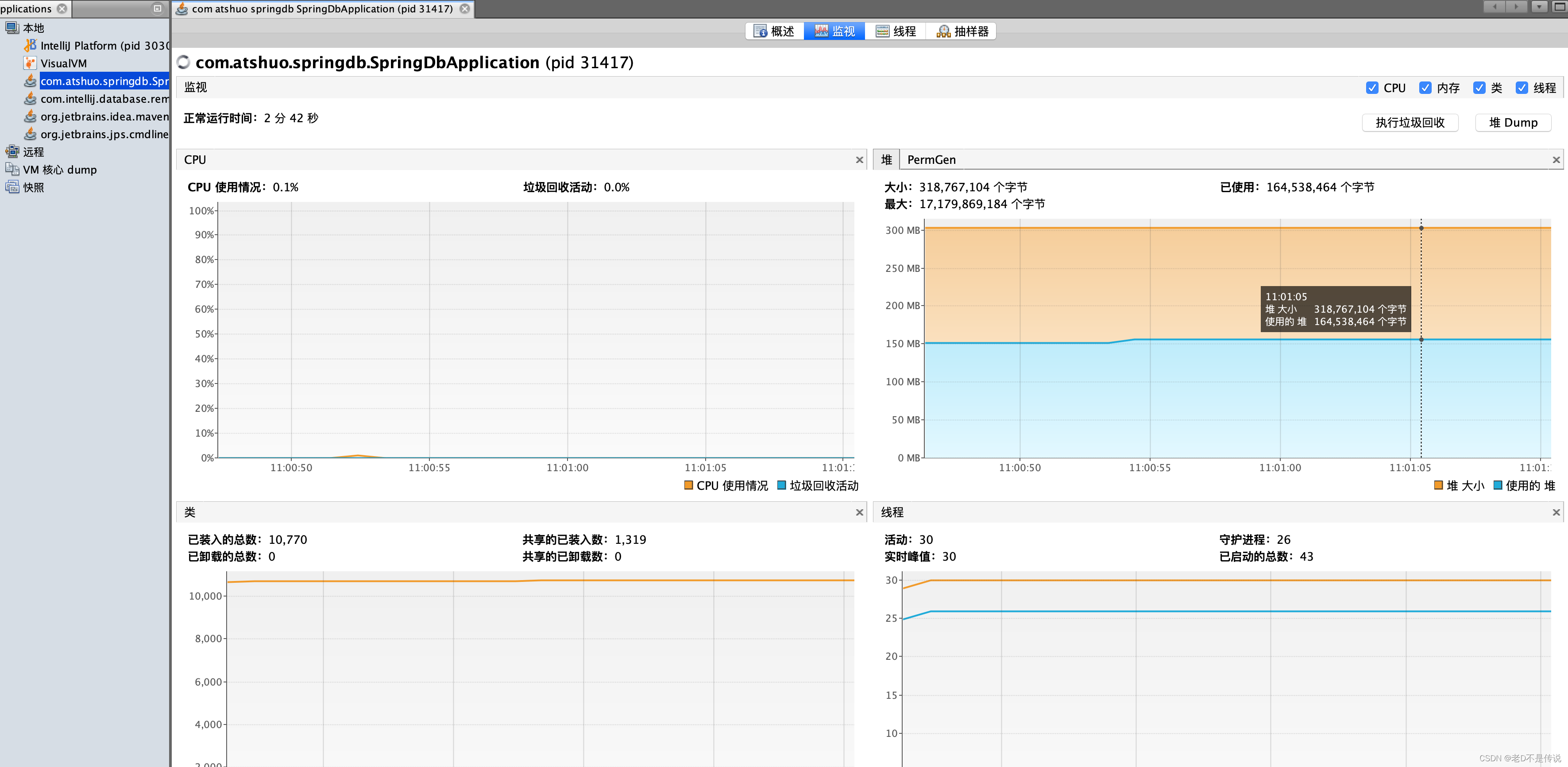
4,使用PostMan上传文件执行。
5,服务端马上进入边解析边处理。
6,监控看出来,在处理的过程中,堆内存的使用量在300M上下波动。
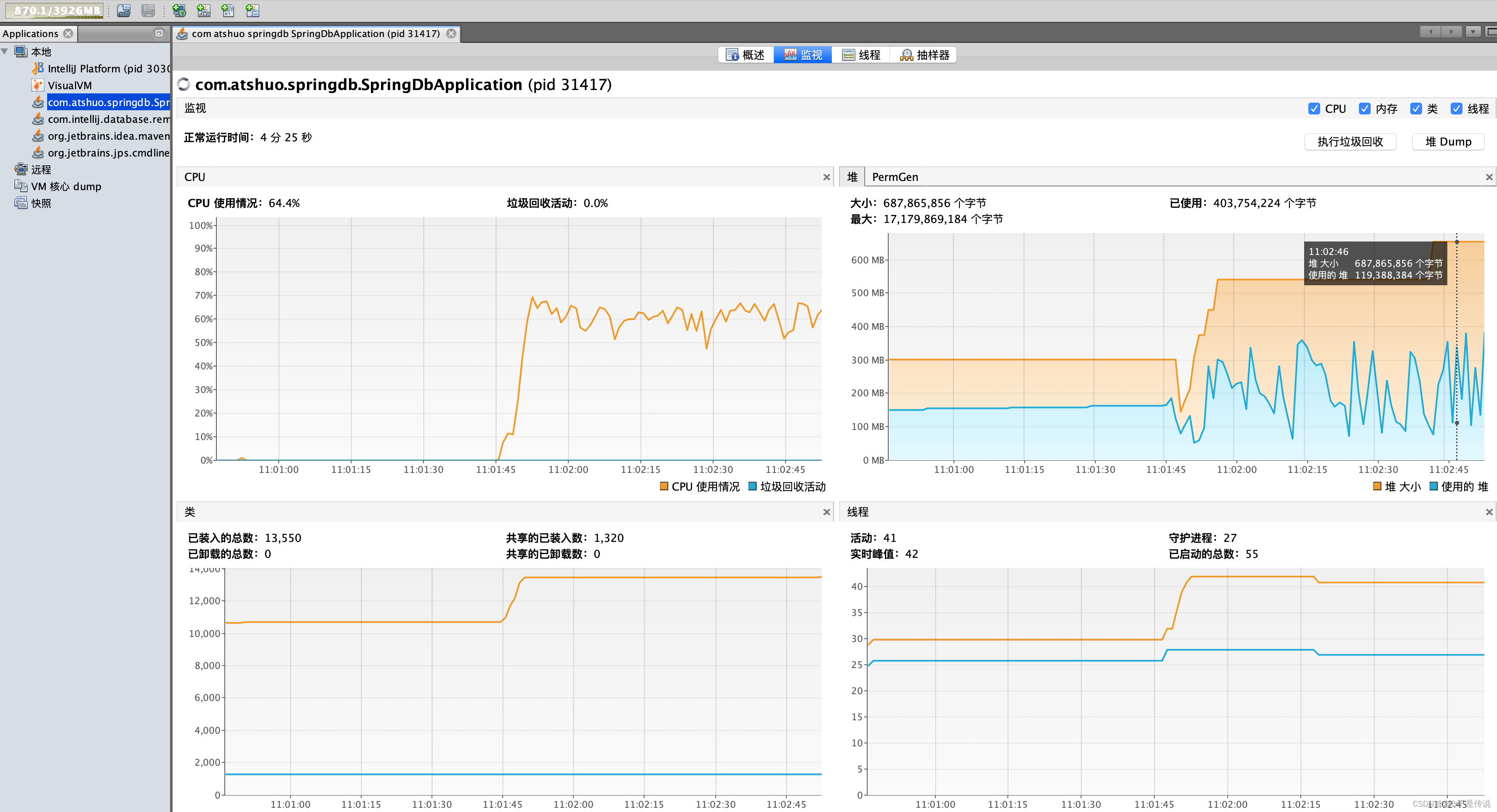
7,78.1M的文件,255999条数据,每行数据73列,解析完成并批量入库,共用时 153秒左右,大约2分半时间,处理完成后,堆内存占用恢复150M左右。


当执行Excel读取,EasyExcel将会在读取每一行时立即处理并且释放该行的内存,由于这种连续的内存回收,我们在记录内存使用情况时只会看到内存占用的小幅度波动。所以即使相同规模的Excel,使用EasyExcel在内存消耗上优势非常显著。
以上就是Apache POI和EasyExcel在处理大规模Excel文件时的内存使用示例,结合内存使用情况,我们可以明显看出在高数据量场合,使用EasyExcel并采取基于事件模式的方式可以达到更高的读取效率,并且有效地节省内存使用,处理百万,千万excel数据的导入导出的不二选择。
五、总结
总的来说,选择哪种方式依赖于具体的应用场景。如果内存不是问题,数据规模较小,但需要进行复杂的操作,Apache POI可能是更好的选择。相反,如果你处理的是大规模数据,或者你的服务器内存有限,EasyExcel会是更为高效的解决方案。希望通过这篇文章,你已经对Apache POI和EasyExcel有了更深入的理解,能够针对你的需求做出更加合理的选择。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- three.js实战模拟VR全景视图
- 司铭宇老师:房地产网络营销培训:房地产网络营销流程与营销策略:打造新时代购房盛宴
- CEC2017(Python):六种算法(RFO、DBO、HHO、SSA、DE、GWO)求解CEC2017(提供完整Python代码)
- Ubuntu之离线安装Gitlab,搭建私有代码仓库
- Spring 应用上下文探秘:生命周期解析与最佳实践
- python——数字精度控制
- WEB 3D技术 three.js 3D贺卡(1) 搭建基本项目环境
- Kafka-消费者-KafkaConsumer分析-PartitionAssignor
- gcc错误:gcc:尝试执行cc1错误:execvp:没有这样的文件或目录
- 删除排序链表中的重复元素