(2024,密集量子电路,量子 U-Net,幺正单采样)量子去噪扩散模型
Quantum Denoising Diffusion Models
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
近年来,像 DALLE、Craiyon 和 Stable Diffusion 这样的机器学习模型因其能够从简明的描述中生成高分辨率图像的能力而受到重视。与此同时,量子计算正取得显著进展,特别是在量子机器学习方面,它利用量子力学来满足传统机器学习算法日益增长的计算需求。本文探讨了量子机器学习与变分量子电路的整合,以增强基于扩散的图像生成模型的有效性。具体而言,我们解决了经典扩散模型的两个挑战:它们的采样速度较低和广泛的参数要求。我们引入了两个量子扩散模型,并使用MNIST digits、Fashion MNIST 和 CIFAR-10 对它们的性能进行了基准测试,与它们的经典对应物相比,我们的模型在 FID、SSIM 和 PSNR 等性能指标上表现优异,并且引入了一种一致性模型的幺正单采样架构(unitary single sampling architecture),将扩散过程合并为一个步骤,实现快速的单步图像生成。
2. 相关工作
2.1. 扩散模型
扩散模型最初由 [44] 提出,呈现了一种训练生成模型的独特方法。与 GANs 中的对抗性对峙不同[11],扩散模型侧重于将噪声稳定地转化为有意义的数据。虽然这种技术的最初阶段显示出有望的结果 [7],但随后出现了一些改进,如去噪扩散隐式模型(DDIM)[17, 33, 45]。与传统扩散模型不同,传统扩散模型以马尔可夫链的方式采样每个中间步骤,而 DDIM 在较早的阶段识别并去除噪声,绕过了某些采样迭代 [45]。在本文中,我们主要遵循 Ho 等人的方法 [17]。
2.2. 变分量子电路
量子机器学习(Quantum machine learning,QML)旨在利用量子计算的能力,满足传统机器学习算法日益增长的计算需求 [3, 10]。变分量子电路(Variational quantum circuits,VQC)是 QML 的基础,类似于经典神经网络的函数逼近器。这些电路利用量子力学的原理,如叠加、纠缠和干涉,来利用量子比特(qubits)上的参数化幺正量子门(unitary quantum gates) [1]。这些门的参数来自旋转角度,可通过传统机器学习方法进行训练。VQC 的架构包括三个组件。
- (编码)第一个组件将图像和引导数据嵌入到量子比特中。对于图像数据,我们采用幅度嵌入,该方法将 2^n 个特征(像素值)编码到 n 个量子比特中,将每个特征表示为量子态的归一化振幅 [32, 47]。对于标签嵌入,我们使用角度嵌入,它仅将 n 个特征编码到 n 个量子比特中,但使用更少的量子门 [55]。
- (特征学习)第二个组件由多个变分层组成,类似于经典网络中的隐藏层。遵循 Schuld 等人的方法 [43],我们设计我们的电路具有强烈纠缠的层。我们还应用数据重新上传,在变分层之间重新嵌入输入的部分,这有助于更复杂的特征学习 [38]。
- (获得输出分布)最后,我们通过测量量子系统来提取输出,导致叠加态塌缩(collapse)。鉴于 n 个量子比特,这使我们能够推导出输出状态的 2^n 联合概率。量子模拟器进一步支持提取电路的状态矢量,我们使用它来构建第 3.4 节中的组合幺正矩阵(combined unitary matrix)。
重要的是要强调,虽然 VQC 可以仅使用 log2 (N) 量子比特高效地处理高维输入 [28],但它们仍然在当前的有噪中间规模量子(Noisy Intermediate-Scale Quantum,NISQ)时代遇到问题,如高量子比特成本和错误率 [39]。然而,这些领域的预期进展对 QML 未来的关键作用充满了希望 [10, 39]。
2.3. 量子扩散模型
据我们所知,Dohun Kim 等人提出的 QDDPM 模型目前是唯一用于图像生成的量子扩散方法[20]。他们设计了一个单电路模型,其按时间步层分层,每次迭代采用独特的参数,并在所有迭代中保持一致的共享层。该模型在空间效率上表现出色,只需要 log2 (pixels) 量子比特,因此在图像生成中呈现对数空间复杂性。为了对抗梯度消失问题,他们限制了电路深度。对于纠缠,他们利用了特殊幺正(special unitary,SU)门,同时作用于两个量子比特。虽然 “SU(4)” 组提供了已知的例如微分的好处,但它们每个门的参数效率较低,因为它们每组使用 15 个参数。鉴于受限的电路深度,他们的模型生成的图像在某种程度上是可以识别的,但缺少原始图像的复杂性(参见图 1)。

3. 量子去噪扩散模型
3.1. 密集量子电路
在我们的工作中,我们采用了密集量子电路(或强纠缠电路)作为我们量子模型的基础组件。术语“密集” 指的是电路中量子比特之间的广泛纠缠。这个设计选择让人想起了经典深度学习中的命名法,其中术语 “密集” 或 “全连接” 描述了每个神经元与相邻层中的每个其他神经元相连接的层。
我们密集量子模型的架构如下。如第 2.2 节所述,由于幅度嵌入在空间效率上的优势,我们选择了幅度嵌入作为输入嵌入的方法。鉴于我们是在模拟器上进行训练,我们绕过了 [32] 中概述的初始预处理步骤,直接将归一化数据初始化到量子电路的状态。我们通过使用角度嵌入对归一化类别索引进行编码,以进行引导。这是通过添加一个额外的量子比特(辅助比特)并围绕 x 轴旋转一个角度,角度为:类别索引 × 2π / #类别(类别数)。我们的电路的变分组件由多个强纠缠层组成 [43],导致总共有 #层 × 3 × #量子比特 可训练参数。然后,我们计算量子子集的联合概率,测量输出在状态 |00 . . . 00? 到 |11 . . . 11? 的似然。如果我们的输出向量在大小上超过了输入向量,我们截断多余的部分,消除未使用的测得概率。为了将输出与输入数据的范围对齐,我们使用输入数据的欧几里得范数来缩放获得的概率。
3.2. 量子 U-Net
我们的量子 U-Net(QU-Net)灵感来自于经典 U-Net,特别是那些没有注意力层和上采样特征的U-Net(如图 2 所示)。
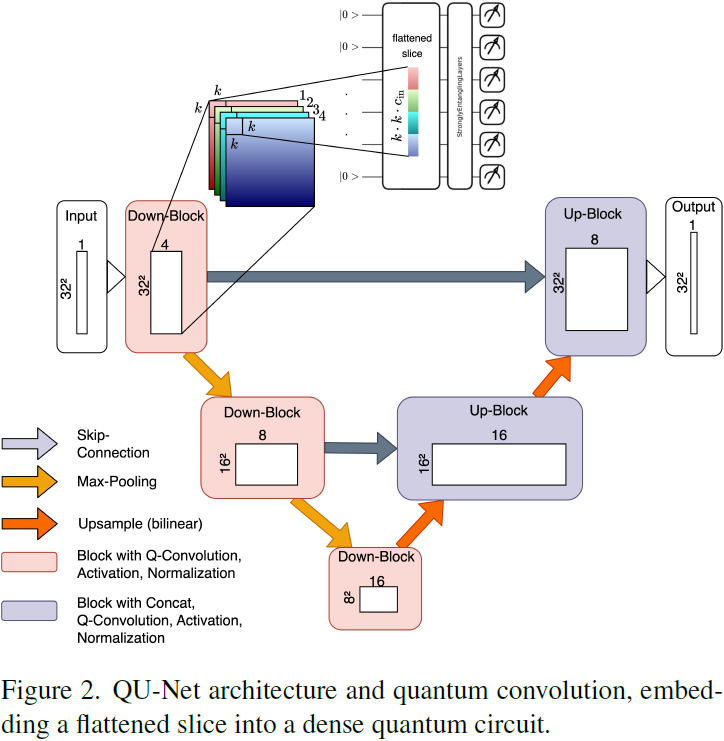
与众所周知的每个具有两个或更多经典卷积的块相反,我们每个块只包含一个量子卷积层,因为我们观察到使用更多卷积时执行时间较长。量子卷积是我们在量子机器学习中使用卷积灵活性的新颖方法,允许我们将形状为 c_in × k × k 的任何切片嵌入到一个密集的量子电路(第3.1节)中,具有
![]()
条线(图 2),并测量 c_out 个输出(其中 c 为输入和输出通道,k 为卷积核大小),因此与现有解决方案(如 Quanvolution [15] 和 Quantum CNNs [4, 35])不同。
3.3. 引导
扩散模型可以通过引导进行扩展,在训练和推断期间引入辅助数据。这个过程表示为 p_θ(x_(t?1) | x_t, c)(或 p_θ(?_(t?1) | x_t, c)),使用 c 作为引导数据 [34]。
对于我们的密集量子电路,归一化的类别标签被嵌入为辅助量子比特的旋转角度,确保了不同的量子状态表示。例如,标签 0 和 1 对应于角度 0 和 π。
相反,由于其架构的原因,U-Net 为标签实施了掩码编码。这个掩码定义为
![]()
通过巧妙地放置像素值条纹,微妙地改变输入图像,以促进标签识别。对于量子 U-Net,尽管在量子卷积中需要归一化的输入,但这种掩码技术仍然有效。然而,具有广泛类别变化的数据集可能需要其他策略。
3.4. 幺正单采样
量子门和电路的幺正性质使我们能够将扩散步骤中 U^τ 的迭代应用合并为一个幺正矩阵 U(图3)。这使我们能够使用电路 U 的单样本创建合成图像,弥合了量子扩散模型和经典一致性模型 [46] 之间的差距。此外,这种方法可能比执行经典扩散模型的多次迭代或甚至比逐个执行每个门的速度更快,具体取决于转换过程和量子硬件。

训练单一采样模型要求使用一种替代的损失计算方法。与典型的测量概率不同,我们对电路后(post-circuit)的量子态感兴趣。目前直接在量子计算机上进行训练是不可行的,因为用于状态重构的量子态层析成像(tomography)随系统规模呈指数级增长 [5]。因此,我们使用一个无噪声的量子模拟器。通过比较电路后的状态
![]()
和较少噪声的图像 |x_t? ,两者都表示为长度为 2n 的复向量,使用诸如平均绝对误差(MAE)之类的指标来评估损失。
为了进行高效的采样,我们使用串联电路 U^n 中的训练参数。或者,我们可以从 U^n 的矩阵形式确定一个单一的 U_diffusion 矩阵。预先计算这个矩阵可以实现更流畅的采样 [46]。
4. 实验设置
4.1. 数据集
MNIST digits [6], Fashion MNIST [54], and a grayscale version of CIFAR-10 [22].
4.2. 指标
Fr′echet Inception Distance (FID) [16, 27], the Structural Similarity Index Measure (SSIM) [53], and the Peak Signal-to-Noise Ratio (PSNR).

4.3. 基线
Deep Convolutional Networks (DCNs), UNets, and Quantum Denoising Diffusion Probabilistic Models (QDDPM).
4.3. 模型训练和评估
我们使用 PennyLane 框架 [2] 构建我们的量子模型。为了训练我们的量子模型,我们使用PennyLane 的 PyTorch 集成,它便于对于旋转角度的梯度进行经典反向传播。在实际的量子硬件上,参数偏移微分通过使用扰动参数重新评估电路来计算梯度 [31, 42]。为了增强收敛性并稳定训练,参数重新映射将值限制在范围 [?π, π] 或 [0, 2π] 内 [24]。我们使用了经典优化算法 Adam [21],最小化由噪声增强的训练数据集产生的生成图像 p_θ(x_t) = ^x_(t?1) 与 x_(t?1) 之间的均方误差(MSE)。值得注意的是,对于幺正单采样模型,我们采用平均绝对误差(MAE),因为它对于复杂张量具有原生的 PyTorch 实现。所有运行都在相同的硬件上进行,使用 Intel Core ? i9-9900 CPU 和 64 GB RAM。在我们的两个初步研究中(第 8 节),我们探讨了模型超参数和指标之间的关系。此外,我们进行了一个关注学习率和批大小的超参数搜索。每个模型的详细超参数设置可在第 10 节中找到。关于我们的图像修补任务 [29, 37],我们评估了没有专门针对此目的进行训练的模型,使用 MSE 来评估图像的保真度。当掩蔽隐藏了重要特征时,面临一些挑战:未引导的模型主要依赖于现有像素,而引导的模型受益于标签指导。?
5. 实验


我们使用均方误差(MSE)来评估具有约 1000 个参数的模型的修补能力,测试在多种情景下使用各种掩蔽和噪声条件,如图 5 所示。值得注意的是,密集量子电路生成了在保持高整体质量的同时产生视觉上一致的样本,只有一些小的伪影。尽管在 FID 得分上表现更好,但深度 QU-Net 相比其较浅的对应物表现较差。?


在检查样本(图 7)时,密集量子电路生成了具有明显噪声的清晰图像,而经典 U-Net 生成了噪声较少但辨识度较低的形状。量子模型在 SSIM 上获得了更高的分数,侧重于总体结构,而 FID 对噪声敏感,提供了不一致的结果,因此在小型密集量子电路和 U-Net 之间的性能比较中得出了不确定的结论。PSNR 分数反映了 SSIM 的结果,但也突显了量子 U-Net 的较低性能,尤其是较小的 QU-Net 在图像边缘处受到了明显的伪影影响。有关密集量子电路存在的问题的潜在解决方案的讨论可在第 7 节中找到。?

6. 幺正单采样
7. 结论
在我们的研究中,我们探索了量子去噪扩散模型,引入了 Q-Dense 和 QU-Net 架构。此外,我们引入了一个称为幺正单采样的量子一致性模型,它将扩散过程整合成一个幺正矩阵,实现了一步图像生成。我们使用 MNIST digits、Fashion MNIST 和 CIFAR10 等数据集,在无引导、有引导和图像修补任务上对我们的模型进行了基准测试,采用了 FID、SSIM 和 PSNR 等度量标准。我们在质量上与最先进量子网络、经典深度卷积网络和 U-Net 进行了比较。
我们的结果表明,我们的模型远远超过了 Dohun Kim 等人提出的唯一其他量子去噪模型 [20]。此外,我们的量子模型性能超过了大小相似的经典模型,并与两倍大小的模型相匹敌。然而,在修补任务中,经典模型仍然具有优势。我们展示了第一个可行的幺正单采样模型的一步生成能力,既在量子模拟器上,也在 IBMQ 硬件上。
在未来的研究中,我们的目标是通过使用缓存矩阵来简化模拟,从而提高变分量子电路的效率,实现更快的 GPU 并行执行。采用 16 位浮点精度可以显著减少 RAM 使用 [14, 51],考虑到在经典机器学习中已经取得的成功和 FP16 的 GPU 广泛支持。我们还热衷于探索扩散修补 [30],该方法利用像素邻域作为通道,这种方法可能会显著提高执行速度,特别是在 RGB 图像中。对比经典模型,对最佳数据嵌入方法(第 3.3 节)进行更深入的探讨可能会为量子知识表示提供深刻见解。此外,通过使用定制的纠缠电路来改进密集量子电路,可能会提供更优越的空间局部性。最后,在我们的模型中引入经典组件进行后处理可能是规避量子状态规范化约束并增强整体性能的途径。?
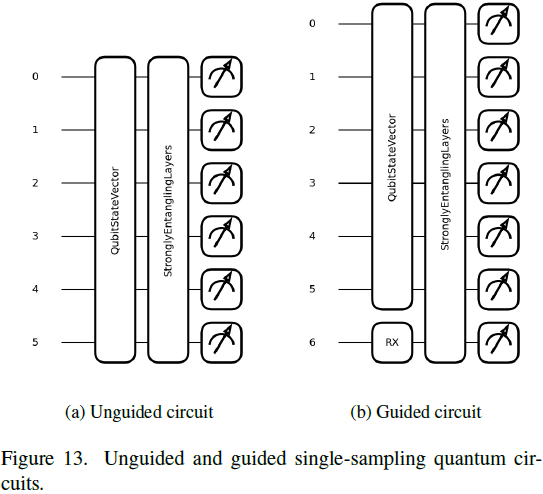
9. 量子架构
在这项工作中,我们介绍了两种用于去噪扩散模型的量子架构。如图 13 所示,每种架构都有引导和无引导的变体。所有引导变体都利用了一个额外的量子比特,称为 “辅助比特”,这是标签的嵌入。图 13b 详细说明了如何使用 R_X 旋转(角度嵌入)嵌入标签,以及随后的变分层如何延伸到辅助量子比特。两种变体都使用强纠缠层作为变分层。
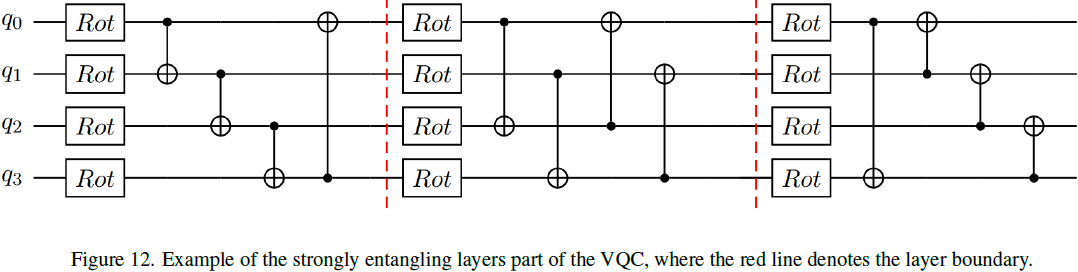
在图 12 中,我们描绘了多个强纠缠层的示例,每个可训练参数 θ^j_i 都与第 i 个量子比特和第 j 个旋转门相关联,其中 j 的范围是 {0, 1, 2}。为了清晰起见,在图形表示中省略了表示层的索引。强纠缠的 CNOT 门以位置 (i+L) mod n 为目标,其中 L 是层号。该方案确保了在第一层(L = 1)中的循环纠缠,控制比特和目标比特相邻,除了完成循环的最后一个 CNOT 门。在第二层(L = 2)中,控制比特和目标比特相隔一个比特。例如,在这一层中,第一个量子比特(i = 0)的目标比特是第三个量子比特(i = 2)。?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!