轻量化网络-MobileNet系列
整理备忘
目录
1. MobileNetV1
1.1 论文
https://arxiv.org/abs/1704.04861

MobileNets基于流线型架构,使用深度可分离卷积来构建轻量级的深度神经网络。
1.2 网络结构
以深度可分离卷积为组件,构建的网络结构如下:

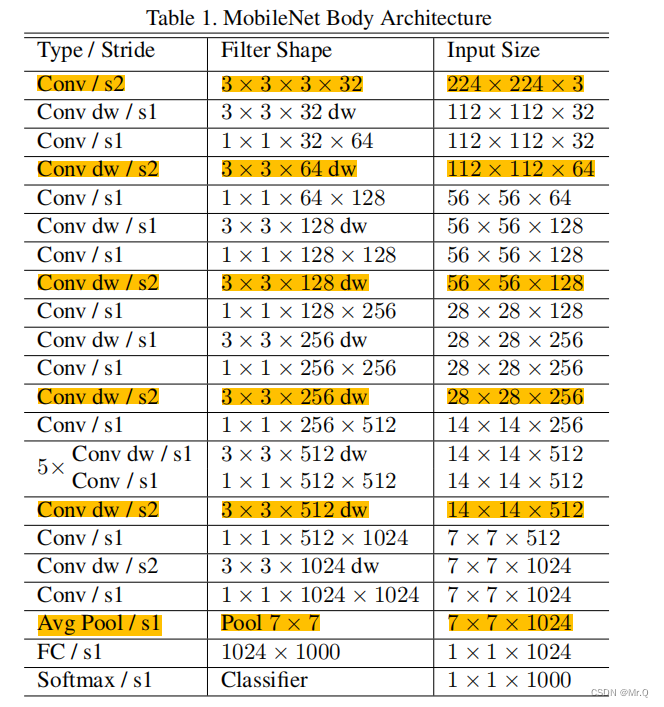
Figure3是深度可分离网络组件Conv dw,Table1是MobileNetV1网络结构。前五次通过Conv dw进行下采样,最后一次通过Avg Pool下采样变成1x1x1024,再接分类层,网络结构简单。
1.3 深度可分离卷积
?图片来源:轻量级神经网络“巡礼”(二)—— MobileNet,从V1到V3 - 知乎
普通卷积:使用大小为5x5x3的卷积,去和12x12x3特征图点乘求和,得到8x8的特征图,有256个卷积去卷积,就得到8x8x256的特征图:
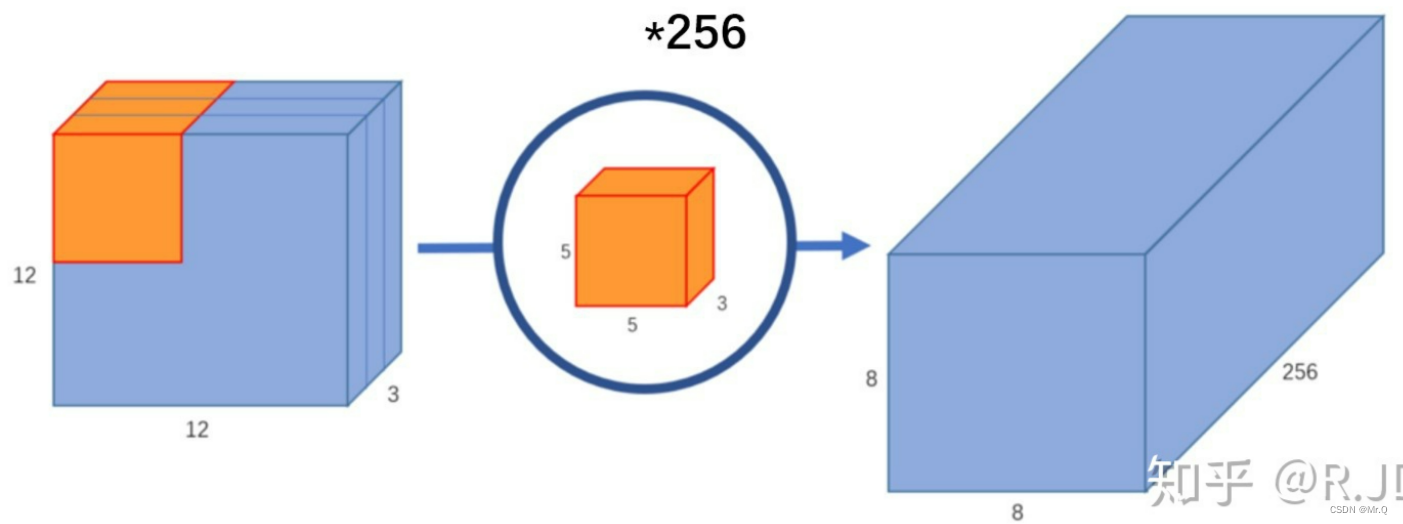
深度可分类卷积:将普通卷积(核大小5x5x3)拆分成深度卷积(核大小5x5x1),逐点卷积(核大小1x1x3),过程如下图。
(1)深度卷积,逐个通道去卷积,一个卷积(核大小5x5x1)去卷12x12x3,得到8x8x3特征图

(2)逐点卷积(就是1x1的卷积),逐个点去卷积,一个卷积(核大小1x1x3)去卷8x8x3,得到8x8x1特征图
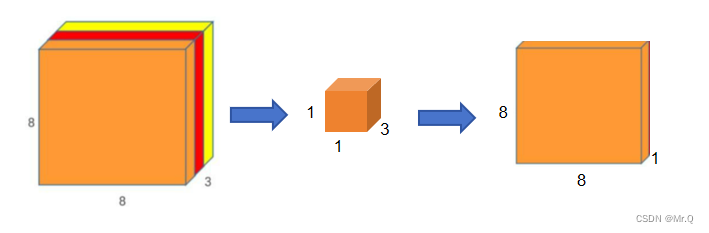
256个卷积去卷,就得到8x8x256特征图

?1.4 计算量下降了
(1)普通卷积的计算量:
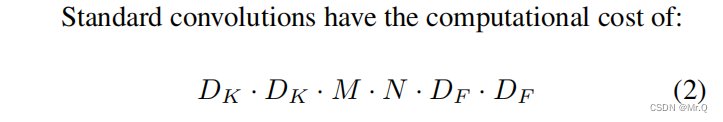
?D_k是卷积核大小,M,N分别是输入通道数,输出通道数;D_F是特征图大小。
(2)深度卷积的计算量:
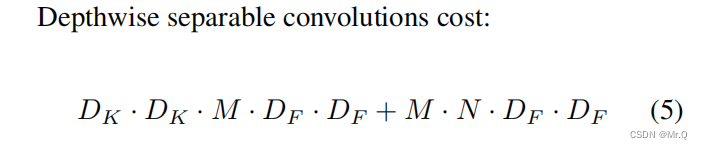
(3)两者比例,输出通道数N和卷积核大小D_k越大,深度可分离卷积计算量相对就越小:

卷积核大小是3x3,计算量下降到原来的1/9到1/8.?
将普通卷积换成深度可分离卷积后,实验效果,计算量下降了很多,但是精度没有下降多少。

1.5 参数量下降了
不仅计算量下降了很多,总参数数量也下降了。
(1)普通卷积:
对于一个普通的卷积层,假设输入通道数为M,输出通道数为N,卷积核大小为(D_K, D_K, M),那么参数数量可以为,一个卷积核的参数量是M*D_K*D_K,有N个卷积核:
(2)深度可分离卷积:
-
深度卷积:对每个输入通道进行单独的卷积(核大小是5x5x1),只有一个深度卷积核,所以
-
逐点卷积:在深度卷积之后,应用1×1的卷积(核大小是1x1xM)来组合输出通道,有N个逐点卷积核,所以参数数量为:
?深度可分离卷积,总参数量是:
2. MobileNetV2
(1)MobileNetV2引入了残差连接,有助于梯度的流动,提高了网络的训练效率;
(3)MobileNetV2通过调整超参数,如宽度乘数(Width Multiplier)和分辨率乘数(Resolution Multiplier),提供了更大的灵活性,可以根据应用场景进行调整。
2.1 论文
https://arxiv.org/abs/1801.04381

2.2 网络结构
(1)同样是5次下采样,最后是一次AvgPooling接分类层。
(2)不同的是组件不再是一种深度可分离卷积,而是水桶型结构:先1x1卷积通道升维,再深度卷积,再接1x1卷积(也就是逐点卷积)降维,这里与Resnet刚好相反(所以叫Inverted Residuals),ResNet 先降维(0.25倍)、卷积、再升维,是沙漏型结构。
(3)步长为1时,再接一个跳层连接。
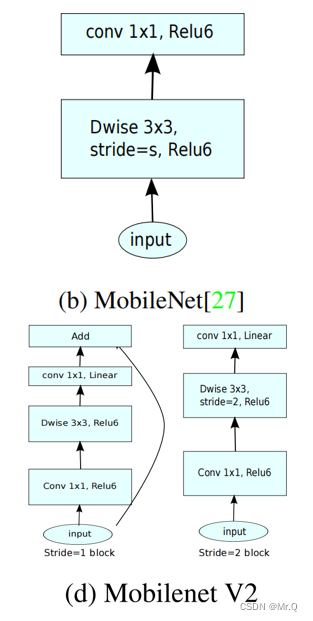

其中t是扩展通道的倍数。
为何要升维度呢?因为深度卷积没有升维度的能力,如果输入特征通道很少,则深度卷积只能在低维度上工作。所以先1x1卷积进行升维度。
2.3 效果
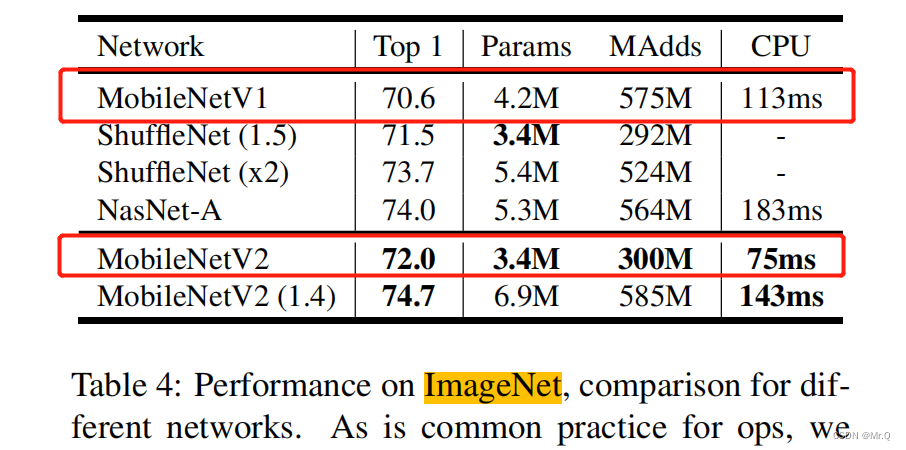
左图分类,右图分割任务。参数量更少,速度更快,准确率更高(实际哪个好要自己试)。?

3. MobileNetV3
3.1 论文
?Searching for MobileNetV3
https://arxiv.org/abs/1905.02244
(1)提出一种新的激活函数Hard Swish;
(2)引入了通道注意力机制(Channel Attention),以便网络能够更好地关注对特定任务重要的通道,从而提高了模型的性能。
(3)通过NAS,提供了两个不同的版本MobileNetV3,Large和Small,以适应不同的应用场景。MobileNetV3-Large在准确性上更为注重,而MobileNetV3-Small则更注重轻量化和快速推理。
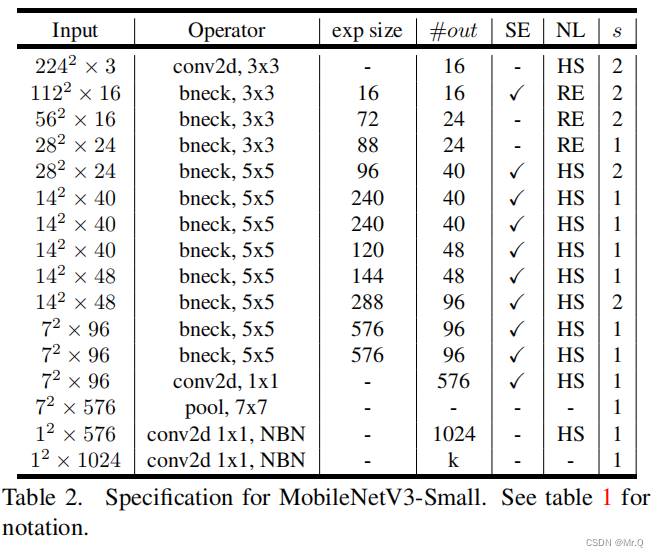
3.2 网络结构
去掉V2最后几层卷积(黄色区域),然后后面接一个Avg-pooling再接分类层。

其中网络组件搞得更加复杂,V2和V3对比。

网络结构:?

3.3 效果?
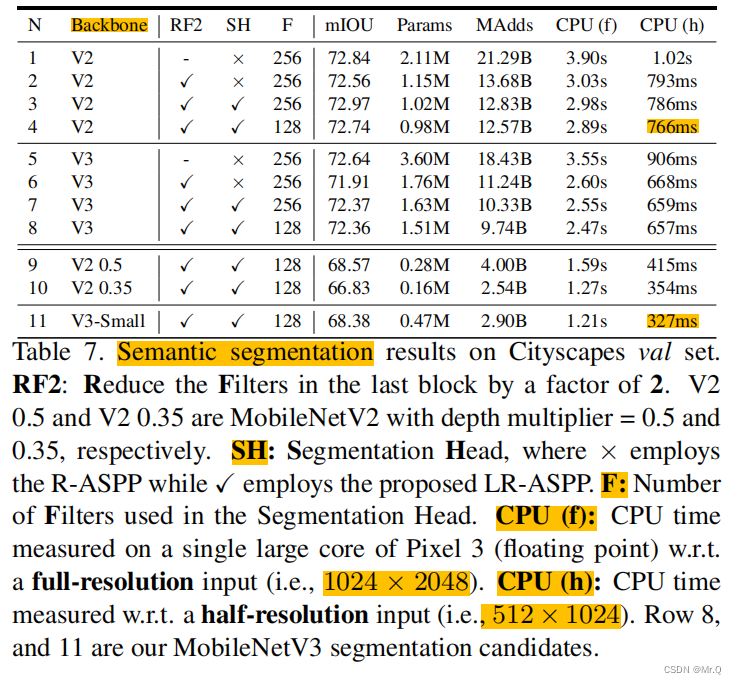
图像分割任务,V3-Small在cpu下,1024x2048图片用时1.21s,512x1024用时0.327s.
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 阿里云SLS日志服务之数据导入与加工处理
- vue知识-04
- C#中汉字转区位码
- 如何统计csv文件中对象的数量(基于pandas)
- OM6621选型指南详细对比应用蓝牙遥控智能穿戴游戏手柄
- 三、MySQL---练习(单表查询)
- 厂务设备设施中如何使用工具实现预测性维护(PdM)
- openmediavault debian linux安装配置企业私有网盘(三 )——raid5与btrfs文件系统无损原数据扩容
- 解决“DataFrame object has no attribute append“问题
- Java中的抽象类以及接口及应用