LLM推理部署(七):FireAttention——通过无损量化比vLLM快4倍
? ? ? ?Mixtral作为第一个在数万亿tokens上训练的OSS模型,最近在人工智能社区掀起了波澜,它支持“混合专家”(MoE),并且训练和推理速度非常快。
? ? ? ?Fireworks AI是第一个托管Mixtral的平台,在Mixtral公开发布之前就托管了。
? ? ? ?虽然最初的炒作已经平息,但有这样一个问题需要回答:
我们能为MoE模型开发出一种更高效的服务,而对质量的影响可以忽略不计吗?
? ? ? ?为了回答这个问题,作者提出了Fireworks LLM服务,其中基于FP16和FP8的FireAttention是核心部分。与其他OSS替代品相比,它具有4倍的加速。下面将介绍基于Mixtral模型的质量和性能研究。
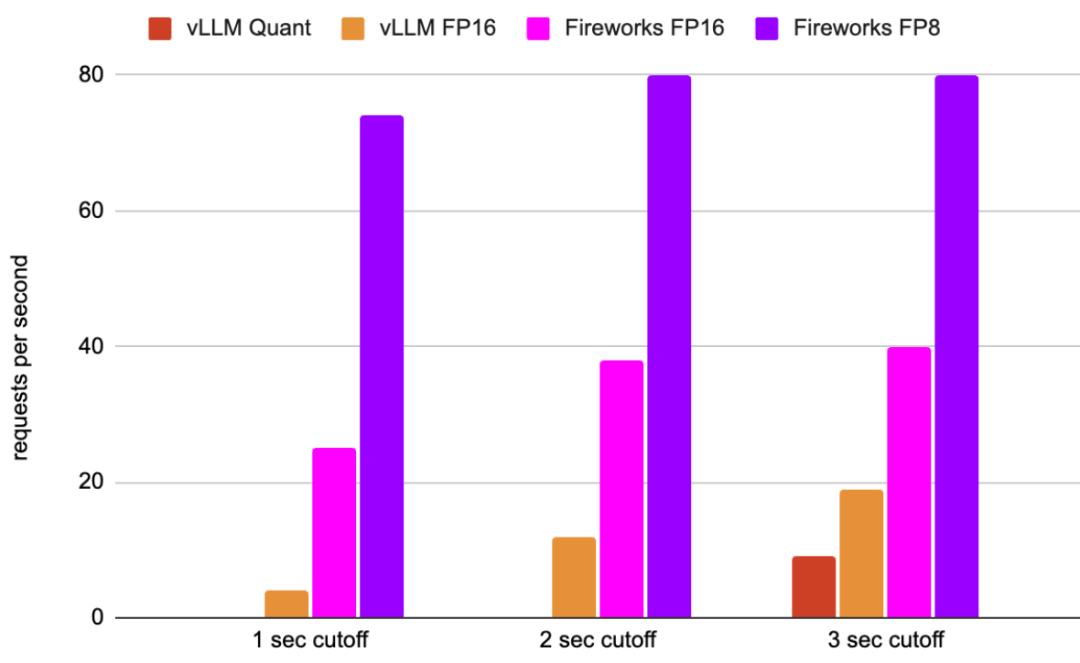
Mixtral在8个H100 GPU上以不同的请求延迟截止值每秒实现的请求数(越高越好)(有关详细信息,请参阅下面的性能分析)
一、实验设置
? ? ? ?由于LLM性能领域不存在“一刀切”的问题,因此在本文中,我们希望关注最典型的用例之一:提示长度=1K,生成的tokens数量=50。此设置涵盖了长提示、短生成的用例。作者认为,短提示和/或长生成需要完全不同的优化策略。
? ? ? 在衡量模型质量时,将重点关注语言理解。使用MMLU度量,它有足够的测试数据集示例(超过14K),Mixtral模型在该度量上表现相当好(70.6%的准确率),但不太好。
? ? ? ?生产环境通常具有“给定延迟预算的最佳吞吐量”要求。因此,作者将使用两个度量进行评估:一个是在给定数量的请求/秒(RPS)的前提下,评估tokens的生成延迟;第二个是给定RPS,评估总请求延迟。不同的服务设置可以将延迟从预填充转换为生成,反之亦然。通过测量这两个指标,我们可以清楚地看到整体情况。
二、FireAttention
? ? ? ?FireAttention是一个自定义的CUDA内核,针对多查询注意力模型进行了优化(Mixtral就是其中之一)。它还专门针对新硬件中的FP16和FP8支持进行了优化,尤其是H100。对于各种批处理大小和序列长度,它在生成过程中运行时接近硬件内存带宽限制。
? ? ? ?FireAttention集成到Fireworks专有的LLM服务堆栈中,该堆栈由CUDA内核组成,针对FP16和FP8进行了优化。
三、质量分析
? ? ? 以半精度运行模型会留下很多性能,因为与half/bfloat16类型相比,现代GPU的INT8/FP8类型有2倍FLOPs。此外,由于内存带宽是生成过程中的瓶颈,我们应该尝试收缩weights和K/V Cache。
? ? ?用于LLM的int量化方法有很多,根据Huggingface的推荐(https://huggingface.co/blog/mixtral),作者已经尝试了一些,而且还评估了FireAttention?FP8的性能。FireAttention?FP8为每个token分配3个专家(而不是默认的2个)。具体的推理细节,请参考:https://twitter.com/FireworksAI_HQ/status/1737232544687665500。
? ? ? ?作者使用标准的5-shot模板在基本Mixtral模型测量了MMLU度量。

GPTQ模型是从GPTQ 8位和GPTQ 4位检查点获得的。
LLM.int8()是通过传递load_in_8bit=True,dtype=float16从原始模型中获得的。
QLoRA 4 bit版本是通过将load_in_4bit=True、bnb_4bit_compute_dtype=float16传递给模型构造函数而获得的。
? ? ? 虽然LLM.int8()(以及在某种程度上QLoRA)与原始模型的质量相匹配,但上面提到的int量化方法都没有任何推理加速,尤其是在batch大小大于1的情况下运行时。具体分析,可以参考:https://huggingface.co/Qwen/Qwen-72B-Chat-Int8#%E6%8E%A8%E7%90%86%E9%80%9F%E5%BA%A6%E5%8F%8A%E6%98%BE%E5%AD%98%E4%BD%BF%E7%94%A8-inference-speed--gpu-memory-usage。
? ? ? ?其他方法,如SmoothQuant和AWQ,试图提高模型的性能,但仍然达不到要求,尤其是在生成过程中。int量化的基本问题仍然存在。问题是LLM激活不具有均匀分布,因此对int方法提出了挑战。
? ? ? ?另一方面,FP8提供了一个非常有前景的机会,因为它更灵活地适应利用硬件支持的非均匀分布。
? ? ? 浮点量化在LLM中的优越性在许多论文中都有介绍。下面是一些引文:
ZeroQuant FP(Wu,X.等人2023)值得注意的是,FP8的激活超过了INT8,尤其是在更大的模型中。此外,FP8和FP4的权重量化要么与它们的INT等价物竞争,要么超过它们。
Which GPU(s) to Get for Deep Learning(Dettmers T.2023)我们可以一点一点地看到,FP4数据类型比Int4数据类型保留了更多的信息,从而提高了4个任务的平均LLM零射击精度。
FP8 Quantization: The Power of the Exponent?(Kuzmin A,et al.2022)主要结论是,当对大量网络进行后训练量化时,FP8格式在准确性方面优于INT8,并且指数位数的选择是由网络中异常值的严重程度驱动的。
? ? ? ?尽管如此,在OSS LLM服务实现中,对FP8的实际支持仍然相当匮乏。
? ? ? ? 作者还运行了比较FP16和FP8的其他主要基准测试。以下是完整的列表:
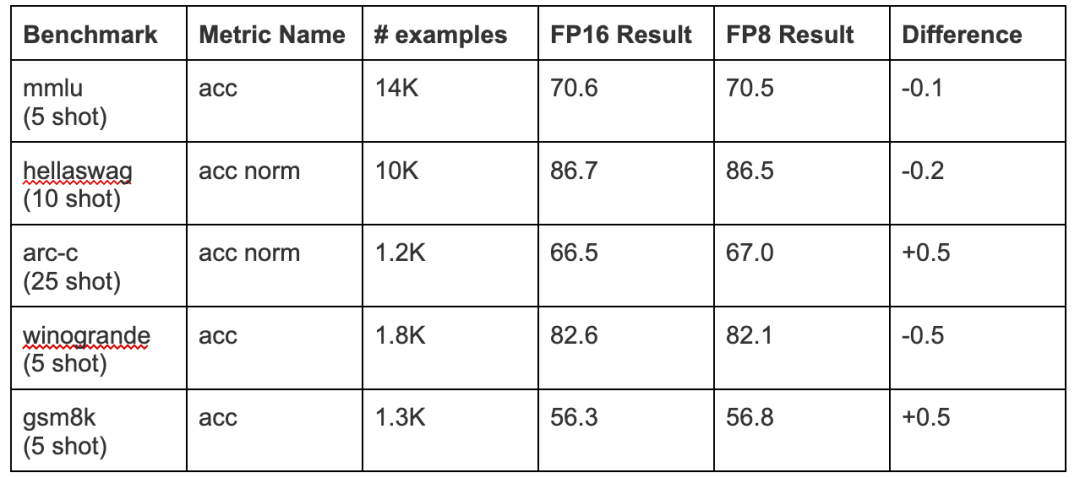
? ? ? ?由于示例数量较少,arc-c/winogrande/gsm8k基准测试结果的差异仅在~1%时有意义。
? ? ? ?基于这些结果,可以得出结论,Fireworks FP8的实现对基础模型质量的影响非常小,在具体的微调版本中可以忽略不计。
四、性能分析
? ? ? ?作者无法在OSS中的Mixtral中实现FP8(TensorRT LLM在选定的少数模型上支持Mixtral和单独的FP8,但FP8目前不能与Mixtral一起工作)。相反,将把Fireworks?FP16与Fireworks?FP8进行比较,并将与一个非常著名的用于FP16数字的OSS替代vLLM进行交叉检查。
? ? ? ?作者还在GPTQ Int8模式下运行vLLM。不幸的是,目前vLLM Int8量化无法在多gpu模式下工作,所以作者只使用了一个gpu。虽然在多gpu模式下运行时延迟应该会有所改善,但我们不希望它能超过vLLM FP16的数字。
? ? ? ?作者还在AWQ Int4模式下运行vLLM。不幸的是,即使是单个并发请求的总请求延迟也超过了3秒的截止时间。
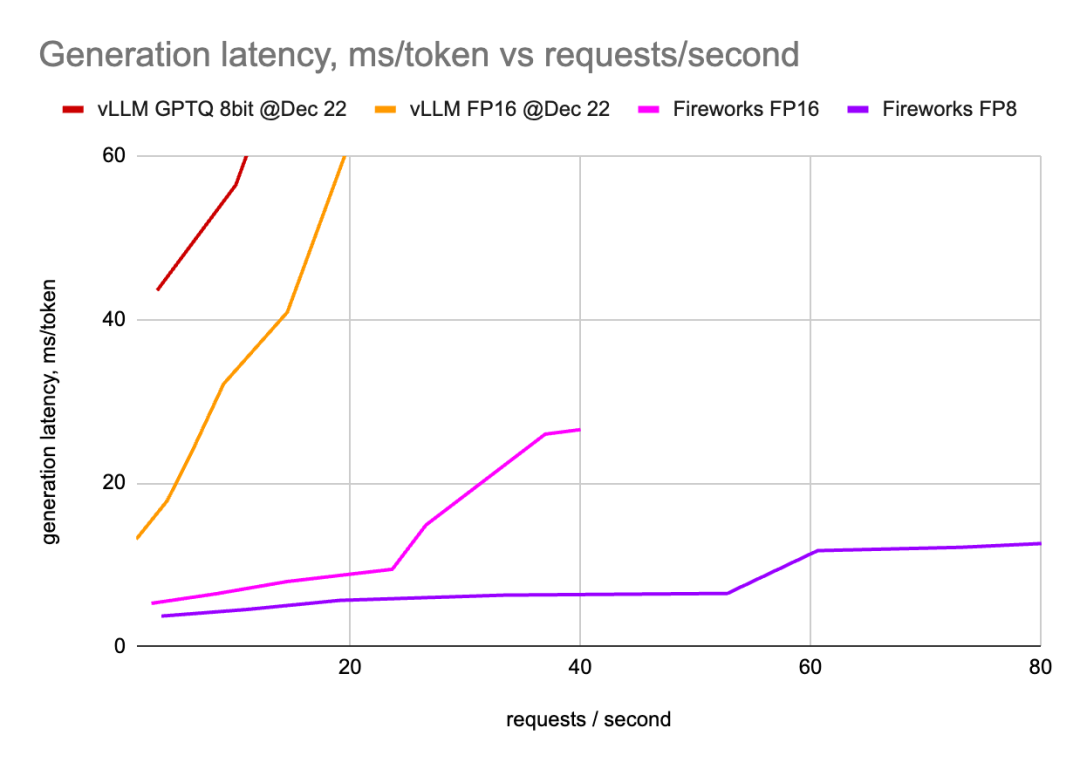
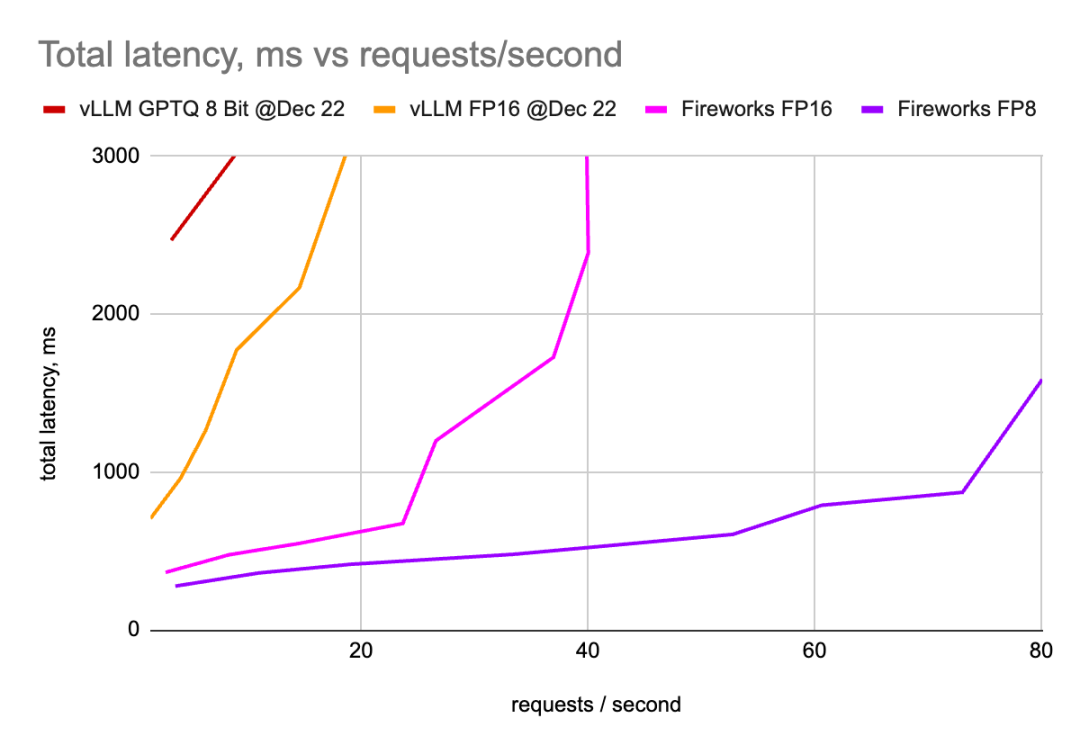
? ? ? ?作者已经在8个H100 GPU上部署了Mixtral模型,并测量了tokens生成延迟以及总请求延迟,同时改变了并发请求的数量。
? ? ? 作者已经在许多配置中部署了vLLM:2、4和8个GPU(超过张量并行),将得到的QPS分别乘以4、2和1,这些图形显示了给定QPS的最佳延迟值。
? ? ? ?作者已经使用许多不同的配置部署了Fireworks LLM服务,与vLLM类似,只显示了获胜配置的数字。
五、结论
-
Fireworks FP16 在Mixtral模型的性能优于vLLM;
-
与已经相当高效的Fireworks FP16相比,Fireworks FP8性能显著提升;
-
由于FP8将模型尺寸缩小了2倍,因此可以实现更高效的部署。与内存带宽和FLOP相结合,可以加快速度,使有效请求每秒提高2倍;
-
LLM性能不存在“一刀切”的问题。vLLM和Fireworks LLM服务的不同配置在不同的设置中显示了它们的优势。
? ? ? ?总体而言,Fireworks FireAttention FP8为LLM在精度/性能权衡曲线上的服务提供了最佳权衡。
PS:如果想获得SOTA LLM性能,包括基于FP8的FireAttention或者通过API端点访问,请查看Fireworks GenAI平台,链接:https://fireworks.ai/。
参考文献:
[1]?https://blog.fireworks.ai/fireattention-serving-open-source-models-4x-faster-than-vllm-by-quantizing-with-no-tradeoffs-a29a85ad28d0?gi=582bc74161a0&source=email-c63e4493b83d-1705085890948-digest.reader--a29a85ad28d0----8-98------------------2f6dc0a1_9ebb_4f10_ae02_b137b7296add-1
[2]?https://fireworks.ai/
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2-8 H. DS线性表—多项式相加
- 003-08-01【Spark-Error】Spark has no access to table, 灵隐寺旁许姓人家女儿大红用GPT 解决了spark 的这个问题.
- KLR技术支持工程师笔试题(包含Linux、计网知识)
- 4-文献阅读-A Data-driven Base Station Sleeping Strategy Based on Traffic Prediction
- 【NR技术】 NR多连接处理流程(Multi-Connectivity operation)
- 基于Java SSM框架实现摄影器材租赁系统项目【项目源码+论文说明】
- 利用地面控制点实现倾斜摄影三维模型数据的几何坐标纠正技术方法分析
- 162 SpringBoot高级原理
- 深入了解Java中的hashCode()方法
- Vue-Pinina基本教程