[labelme]labelme如何将标注的json格式转成png的mask文件掩码文件
labelme工具不仅仅具有标注功能,而且可以将json文件转化为png的分割训练文件,如果您是一个类别则可以直接用labelme_json_to_dataset进行转换最后提取对应的掩码文件即可进行语义分割训练。如果您是>=2个类别则不推荐使用labelme工具进行转换,官方已经提示使用labelme_json_to_dataset进行超过2个类别转换可能会导致颜色映射错误,从而导致转换Png混乱,进一步导致训练的模型识别能力很差或者根本不能识别。官方的labelme_json_todatase工具转换要求json绝对路径不能包含中文路径或者空格,否则需要更改代码才能正常转换。这里不做讲解怎么改代码,下面我们将带大家怎么转换。转换前需要注意几点:
第一:必须切换到labelme对应安装环境中,否则无法使用labelme_json_to_dataset工具
第二:json绝对路径不能包含中文路径或者空格,否则无法转换
第三:官方的labelme_json_to_dataset只能转换单个json文件不支持文件夹批量转换,如果想批量转换需要更改代码或者写个bat脚本进行批量转换
第四:转换的Json文件中包含图片base64编码信息或者json和图片要在一起放着。如果只有一个对应json文件,没有对应图片且同时json里面没有存储base64的图片信息也会导致无法转换。
好了下面开始操作:?
第一步,打开我们对应的labelme环境,比如我的labelme是安装在anaconda3的base环境中,我们在任务栏搜索anconda打开prompt

打开后进入prompt环境

可以看到cmd上面右侧多了个base,表示我们正在anaconda3的base环境中,如果您是在其他虚拟环境中,比如py38环境,则可以通过输入conda activate py38进行切换到指定环境
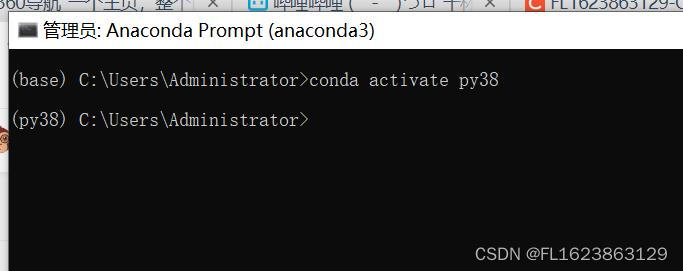
您可以看到右侧环境名字由base变成py38,如果您是其他名称虚拟环境可以依此类推操作
之后我们切换到json所在目录
比如我在桌面路径有个文件夹里面放的是标注文件C:\Users\Administrator\Desktop\labelme-dogcat-test
则可以输入
cd /d?C:\Users\Administrator\Desktop\labelme-dogcat-test进行切换,注意/d是必须存在的,否则无法切换目录

随后我们开始转换,输入labelme_json_to_dataset json文件名即可转换

之后我们进去json所在文件夹查看转换结果
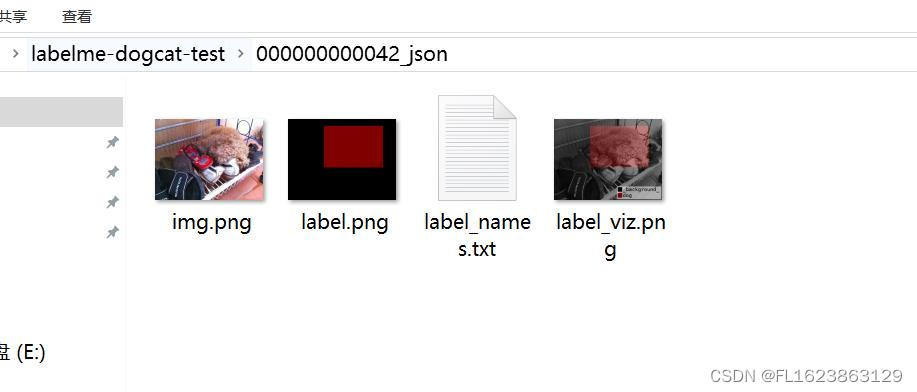
可以看到已经转换完成。如果想批量转换则需要自己写代码或者脚本进行转换。 这里我提供一个脚本
import os
import sys
import subprocess
'''
本脚本可以批量将labelme标注的json文件转成模型训练的掩码文件
'''
def convert_file(json_file):
p = subprocess.Popen(["labelme_json_to_dataset", json_file], shell=False, stdout=subprocess.PIPE)
p.communicate()
def convert_dir(dir):
count = 0
for file in os.listdir(dir):
if not file.endswith(".json"):
continue
json_file = os.path.join(dir, file)
convert_file(json_file)
count += 1
print("convert over, {} file(s) converted!".format(count))
if __name__ == '__main__':
arg = sys.argv
if len(arg) == 2:
convert_dir(arg[1])
else:
print(r"command error,you should input command like:python json_convert.py D:\json")将其保存为json_convert.py,然后切换到这个脚本路径,执行
python??json_convert.py 文件夹路径比如我的json文件都放在桌面文件夹C:\Users\Administrator\Desktop\labelme-dogcat-test
则输入
python??json_convert.py?C:\Users\Administrator\Desktop\labelme-dogcat-test
如果您觉得上面文章太长看的头疼,请观看视频演示教程:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 第11章 GUI Page462~476 步骤二十三 步骤二十四 Undo/Redo ①为Undo/Redo做准备工作,弹出日志窗口
- python第4天之列表推导式、组包拆包、多个返回值、嵌套调用、递归调用、全局变量、局部变量、引用
- 字符统计[c]
- python3 统计redis中每个DB占用的内存大小
- 面试了上百位性能测试后,我发现了一个令人不安的事实
- go从0到1项目实战体系十九:配置文件
- Oracle中带条件插入数据的使用方法
- Halcon 灰度区域的面积和中心area_center_gray
- text preprocessing
- 目标检测开源数据集——海底垃圾识别