text preprocessing
前言
一般情况下,文本分类的主要流程如下:
采用与处理的原因:
解决特征空间高维性、特征分布稀疏和语义相关性
1、文本预处理 text preprocessing
文本要转化成计算机可以处理的数据结构,就需要将文本切分成构成文本的语义单元。
这些语义单元可以是句子、短语、词语或单个的字。通常无论对于中文还是英文文本,统一将最小语义单元称为“词组”。
1.1英文文本预处理
英文文本的处理相对简单,因为单词之间有空格或标点符号隔开。
大致分为以下几点:
1)英文缩写替换
2)转换为小写字母
3)删除标点符号、数字及其它特殊字符
4)分词
如果文本中单词和标点符号或者其它字符是以空格隔开的,例如"a little of both .“,那么可以直接使用split()方法;如果文本中单词和标点符号没有用空格隔开,例如"a little of both.”,可以使用nltk库中的word_tokenize()方法。
5)拼写检查
如果确信分析的文本没有拼写错误,可以略去此步。拼写检查,一般用pyenchant类库完成。
6)词干提取和词形还原
两者其实有共同点,即都是要找到词的原始形式。
词干提取(stemming)会激进一点,它在寻找词干的时候可以会得到不是词的词干。比如"imaging"的词干可能得到的是"imag", 并不是一个词。
而词形还原则保守一些,它一般只对能够还原成一个正确的词的词进行处理。
7)删除停用词
停用词对文本分类没什么影响,比如’a’,‘is’,‘of’
1.2 中文文本预处理
和英文文本处理分类相比,中文文本预处理是更为重要和关键,相对于英文来说,中文的文本处理相对复杂。
中文的字与字之间没有间隔,并且单个汉字具有的意义弱于词组。一般认为中文词语为最小的语义单元,词语可以由一个或多个汉字组成。
所以中文文本处理的第一步就是分词。
中文文本处理中主要包括文本分词和去停用词两个阶段。
1)删除标点符号、数字及其它特殊字符
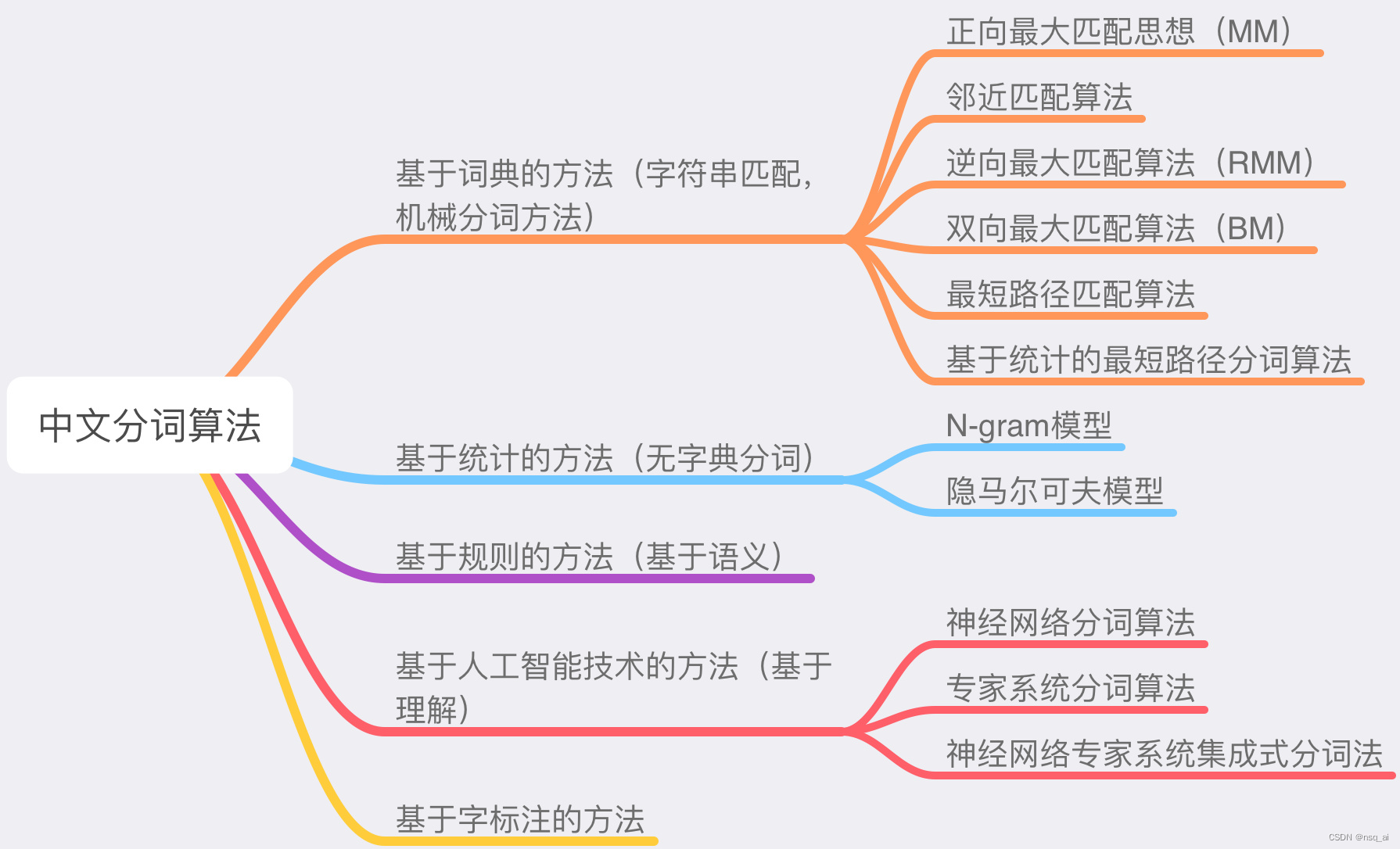
2)目前常用的中文分词算法可分为三大类:基于词典的分词方法、基于理解的分词方法和基于统计的分词方法。
基于词典的中文分词(字符串匹配)
核心是首先建立统一的词典表,当需要对一个句子进行分词时,首先将句子拆分成多个部分,将每一个部分与字典一一对应,如果该词语在词典中,分词成功,否则继续拆分匹配直到成功。字典,切分规则和匹配顺序是核心。
基于统计的中文分词方法
统计学认为分词是一个概率最大化问题,即拆分句子,基于语料库,统计相邻的字组成的词语出现的概率,相邻的词出现的次数多,就出现的概率大,按照概率值进行分词,所以一个完整的语料库很重要。
基于理解的分词方法
基于理解的分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。
它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。
这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。
3)去停用词
在自然语言中,很多字词是没有实际意义的,比如:【的】【了】【得】等,因此要将其剔除。”
停用词(Stop Word)是一类既普遍存在又不具有明显的意义的词,在英文中例如:“the”、“of”、“for”、“with”、“to”等,在中文中例如:“啊”、“了”、“并且”、“因此”等。
停用词去除组件的任务比较简单,只需从停用词表中剔除定义为停用词的常用词就可以了。
参考链接:
1、https://blog.csdn.net/a1097304791/article/details/121472163
2、https://blog.csdn.net/weixin_44766179/article/details/89855100
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!