快速排序的背后——深入理解时间复杂度
时间复杂度的概念衡量算法性能的重要标准,是算法设计和性能优化中的关键概念,对于编写高效、稳定和可扩展的程序至关重要。但是,初学者对于如何理解和应用时间复杂度则显得较为困难,本文以快速排序为例进一步加深对时间复杂度的理解。
1 回顾
本文侧重于时间复杂度的计算,关于时间复杂度的概念可参考二分查找——算法基础。
首先,我们回顾一下快速排序:
def quicksort(arr):
if len(arr) < 2:
return arr
else:
pivot = arr[0]
less = [i for i in arr[1:] if i < pivot]
greater = [i for i in arr[1:] if i > pivot]
return quicksort(less) + [pivot] + quicksort(greater)
在之前的文章中谈过,大O表示法在表示时间复杂度的时候考虑的是最遭的情况,但是由于快速排序的特殊性,需要特别强调平均情况下的时间复杂度。
1 最遭的情况
当我们每次选定的基准值都是无序列表中的最小或最大值的时候,这个时候该算法的时间复杂度与选择排序无差异为
O
(
n
2
)
O_(n^2)
O(?n2),因为每次进行子集的划分都要对列表内的各个元素操作一次,而像这样的操作要执行n次(调用栈高度为n)。

2 一般情况
但是,当每次选择到的pivot都是集合中大小居中的元素,这个时候操作的子集数为
l
o
g
2
n
log_{2}n
log2?n:
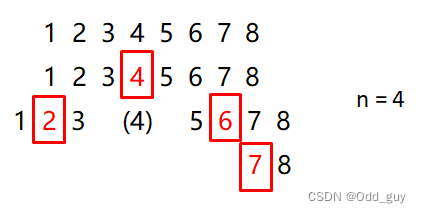
而用户给函数提供的列表多是无序的,所以可以以平均情况下的时间复杂度来表示快速排序的性能,即平均下来,调用栈的高度为
l
o
g
2
n
log_{2}n
log2?n,而每次对站内存储的列表元素都要进行对比,所以操作次数为
n
n
n,所以时间复杂度为:
O
n
l
o
g
2
n
→
n
?
l
o
g
2
n
O_{nlog_{2}n}\to n\cdot log_{2}n
Onlog2?n?→n?log2?n
END
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- simulink代码生成(八)——应用串口输入的16进制数
- Linux pwd命令教程:如何查看当前工作目录(附实例教程和注意事项)
- 2023-12-20 二叉搜索树的最近公共祖先和二叉搜索树中的插入操作和删除二叉搜索树中的节点
- Master主定理求递归算法的时间复杂度
- 进销存如何和收银系统结合
- 竞赛保研 大数据商城人流数据分析与可视化 - python 大数据分析
- 记一次docker的overlay2目录占用大量磁盘空间
- MySQL中的JSON数据类型计数及多张表COUNT的数据相加
- ERR_PACKAGE_PATH_NOT_EXPORTED]: No “exports“ main defined
- TIGRE: a MATLAB-GPU toolbox for CBCT image reconstruction