书生·浦语大模型全链路开源体系
发布时间:2024年01月05日
internLM介绍
书生·浦语大模型系列
- 轻量级:InternLM-7B 社区低成本可用最佳模型规模
- 70亿模型参数,小巧轻便,便于部署
- 10000亿训练token数据,信息全面,能力多维
- 具备长语境能力,支持8k语境窗口长度
- 具备通用工具调用能力,支持多种工具调用模板
- 中量级:InternLM-20B 商业场景可开发定制高精度较小模型规模
- 200亿参数量,在模型能力与推理代价间取得平衡
- 采用深而窄的结构,降低推理计算量但提高了推理能力
- 4k训练语境长度,推理时可外推至16k
全面领先相近量级的开源模型(包括Llama-33B、Llama2-13B以及国内主流的7B, 13B开源模型)
以不足三分之一的参数量,达到Llama2-70B水平学科 - 重量级:InternLM-123B 通用大语言模型能力全面覆盖干亿模型规模
- 1230亿模型参数,强大的性能
- 具备极强的推理能力、全面的知识覆盖面、超强理解能力与对话能力
- 准确的API调用能力,可实现各类Agent
从模型到应用

书生·浦语大模型全链路开源体系
概览
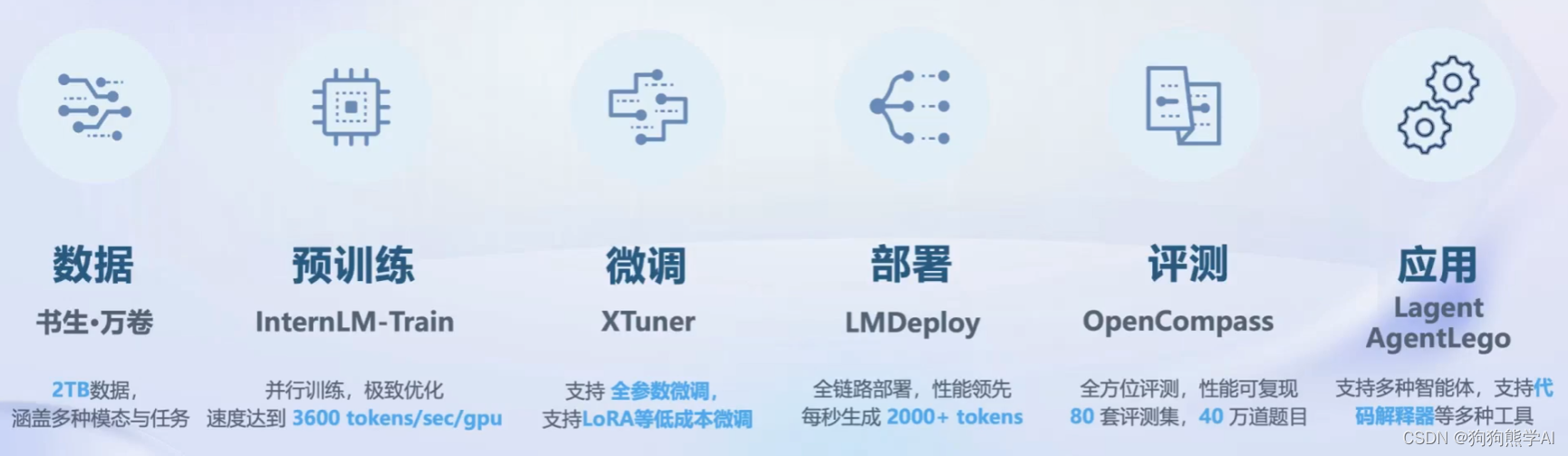
数据
书生·万卷 1.0 (截止2023年8月14日,总数据量为2TB)
- 文本数据:50亿个文档,数据量超1TB。
- 图像-文本数据:超2200万个文件,数据量超140GB。
- 视频数据:超1000个文件,数据量超900GB。
其特点如下:
- 多模态融合:万卷包含文本、图像和视频等多模态数据,涵盖科技、文学、媒体、教育和法律等
多个领域。该数据集对模型的知识内容、逻辑推理和泛化能力的提升有显著效果。 - 精细化处理:万卷经过语言筛选、文本提取、格式标准化、数据过滤和清洗(基于规则和模型)、多尺度去重和数据质量评估等精细数据处理环节,能够很好地适应后续模型训练的要求。
- 价值观对齐:在万卷的构建过程中,研究人员注重将数据内容与主流中国价值观进行对齐,并通
过算法和人工评估的结合提高语料库的纯净度。

预训练

微调
大语言模型的下游应用中,增量续训和有监督微调是经常会用到两种方式。
- 增量续训:使用场景:让基座模型学习到一些新知识,如某个垂类领域知识训练数据:文章、书籍、代码等
- 有监督微调:使用场景:让模型学会理解和遵循各种指令,或者注入少量领域知识训练数据:高
质量的对话、问答数据。

评测




部署


智能体
大语言模型的局限性:
- 最新信息和知识的获取
- 回复的可靠性
- 数学计算
- 工具使用和交互
一个解决办法:智能体



补充资料
文章来源:https://blog.csdn.net/m0_55764641/article/details/135373657
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux下文件的创建写入读取编程
- 初识Java 18-6 泛型
- threejs官方demo解析(一)
- mpp_enc_cfg.conf解析
- 力扣(leetcode)第290题单词规律(Python)
- ECharts与Excel的火花
- 洛谷 NOIP2014普及组 比例简化 + 洛谷 NOIP2015普及组 扫雷游戏
- MySQL-索引
- 电视盒子什么品牌好?实体店主总结线下热销网络电视盒子排行榜
- 【C++】__declspec含义