李沐-《动手学深度学习》-- 01-预备知识
一、线性代数知识
1. 矩阵计算
a. 矩阵求导
? 当y和x分别为标量和向量时候,进行求导得到的矩阵形状,矩阵求导就是矩阵A中的每一个元素对矩阵B中的每一个元素求导
? 梯度指向的是值变化最大的方向

? 分子布局和分母布局:

b. 常识
- axis = 1 代表行 axis = 0 代表列
- nn.model.eval() 将模型设置为评估模式,只输入数据然后得出结果而不会做反向传播
- xxx_下划线在后面的函数代表替换函数,不是返回一个值,而是直接替换
- 介绍:Pytorch 中的 model.apply(fn) 会递归地将函数 fn 应用到父模块的每个子模块以及model这个父模块自身。通常用于初始化模型的参数。
- torch.stack函数,对张量进行堆叠升维度
- **python.zip(x,x)**函数:参数是两个可以迭代的变量,返回两个变量对应的一个元组
二、感知机
1. 概念
? 感知机是一个二分类模型,是最早的AI模型之一;他的求解算法等价于使用批量大小为1的梯度下降;他不能拟合XOR函数,导致第一次AI寒冬。目的是拟合一条线将数据集分成两部分,如果不能找到一条线将数据集分成两部分,则无法用一层感知机做到
2. 多层感知机
? 如果需要拟合复杂的模型,则需要连接多层的神经网络。使用hidden layer和激活函数来得到非线性模型
a. 激活函数
? 多个神经网络层连接时,两个层之间需要激活函数,如果没有激活函数,则会变成单层的感知机。
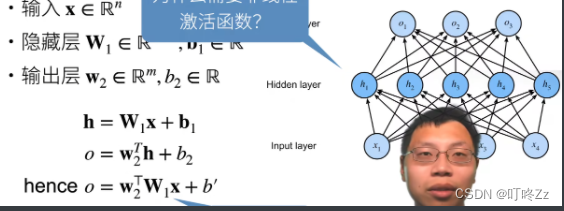
? 种类: sigmoid,Tanh,ReLU,softmax(多类)
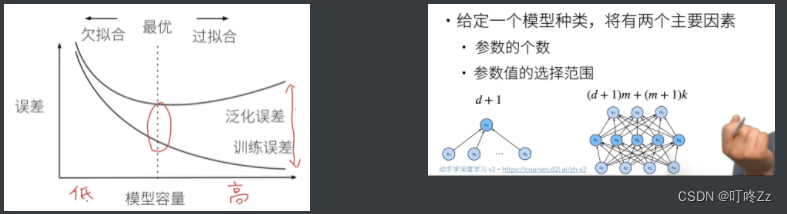
3. 模型选择&过拟合欠拟合(p11)
a.训练误差和泛化误差
- 训练误差:模型在训练数据上的误差
- 泛化误差:模型在新数据上的误差
- **参数&超参数:**区别两个最大的特点就是数据是否通过数据来进行调整,例如学习率就是人为设置的,而w&b是数据进行驱动的数据
- **验证集&训练集&测试集:**如果需要选择使用哪一组参数合适的时候,可以用到验证集;
b. 估计模型容量
?
4 .防止过拟合和欠拟合
1. 权重衰退(weight decay)
权重衰退最常见处理过拟合的方法

(不常用的方法)
最常用的方法:

2 . Dropout(暂退法)

在dropout当中,有一些输入是需要等于0暂时舍去的,还有一些是需要放大,然后使最后的期望不变
**注意:**dropout是在做模型推理的时候使我们的模型复杂度变低,但是在使用做预测或者测试时候是没有使用dropout的
a.技巧
我们可以将暂退法应用于每个隐藏层的输出(在激活函数之后), 并且可以为每一层分别设置暂退概率: 常见的技巧是在靠近输入层的地方设置较低的暂退概率。
5 . 模型初始化和激活函数
**目标:**让梯度值在合理的范围内
方法:
- 将乘法变加法 ResNet, LSTM
- 归一化 :梯度归一化 梯度裁剪
- 合理的权重初始化和激活函数
三、Pytorch神经网络
1 . 卷积层
a . 卷积层作用
- 卷积层将输入和核矩阵进行交叉相关运算,加上偏移后得到输出
- 核矩阵和偏移是可学习的参数
- 核矩阵的大小是超参数
b . 学习卷积核参数
如果我们想达到某种效果(边缘检测,模糊),但是不知道怎么设置kernel参数时,可以从数据中使用梯度下降学习卷积核的参数。(需要提前给出 Y的正确值,然后一直梯度下降)
c . 二维卷积层

d . 1 x 1 卷积
? 卷积使用了最小窗口,失去了卷积层特有的识别相邻元素相互作用的能力,使之作用在通道上。
- 1×1卷积层通常用于调整网络层的通道数量和控制模型复杂性。
e . 池化层(pooling)
- 对于给定输入元素,最大汇聚层会输出该窗口内的最大值,平均汇聚层会输出该窗口内的平均值。
- 汇聚层的主要优点之一是减轻卷积层对位置的过度敏感。
- 我们可以指定汇聚层的填充和步幅。使用最大汇聚层以及大于1的步幅,可减少空间维度(如高度和宽度)。
- 汇聚层的输出通道数与输入通道数相同。且一般放在卷积层的最后
四 .经典CNN网络
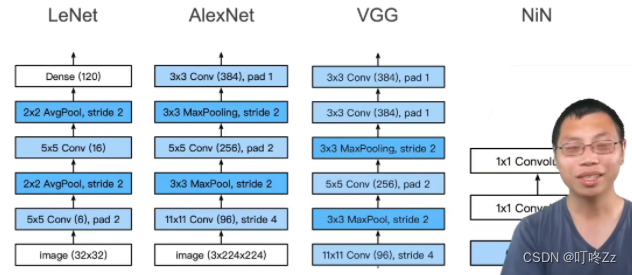
1 .LeNet 神经网络
在这里插入图片描述
a .总结
- 卷积神经网络(CNN)是一类使用卷积层的网络。
- 在卷积神经网络中,我们组合使用卷积层、非线性激活函数和汇聚层。
- 为了构造高性能的卷积神经网络,我们通常对卷积层进行排列,逐渐降低其表示的空间分辨率,同时增加通道数。
- 在传统的卷积神经网络中,卷积块编码得到的表征在输出之前需由一个或多个全连接层进行处理。
- LeNet是最早发布的卷积神经网络之一。
2 . AlexNet
a. 框架
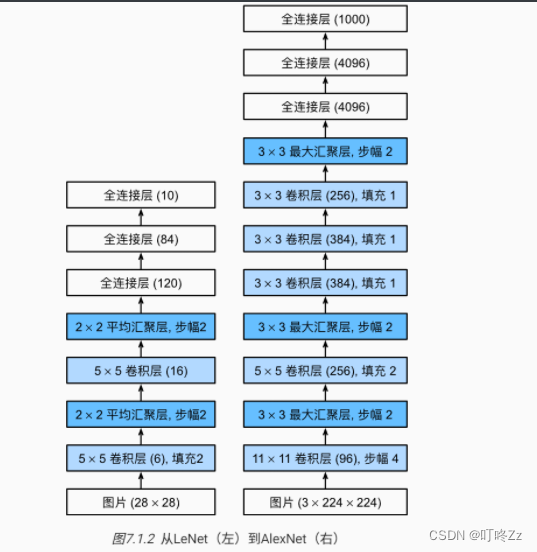
b . 总结
?

3 . VGG块
? 将AlexNet的中间的卷积层抽出来,然后复制几份替代掉了AlexNet的前面几层不规则的卷积层,可以称为更大更深的AlexNet网络

a . 总结
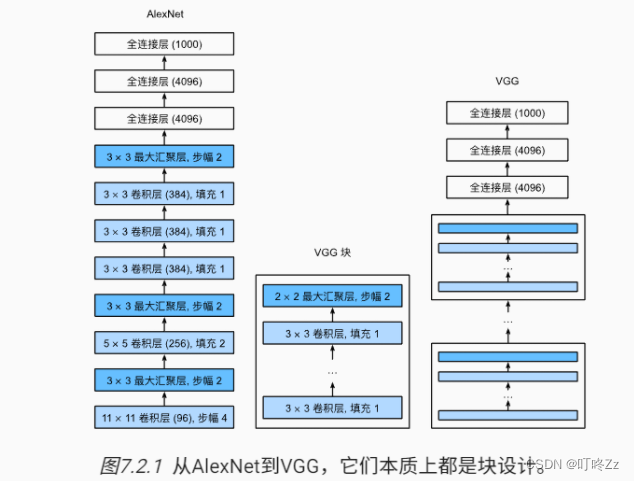
4 . NiN块
? 实质:将最后的全连接层用1*1的卷积来替换
a . 与前三个的区别:
? 
5 . GoogLeNet
? 和vgg一样有5个block,这里用的是Inception
a . Inception
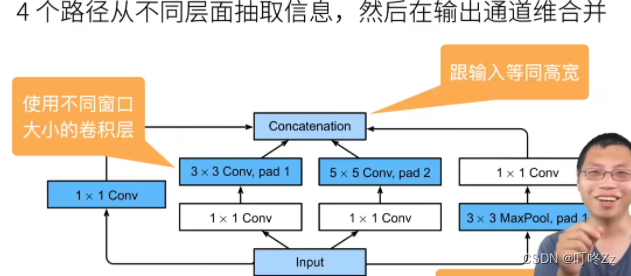
Inception 变种

b . stage 1&2与AlexNet区别
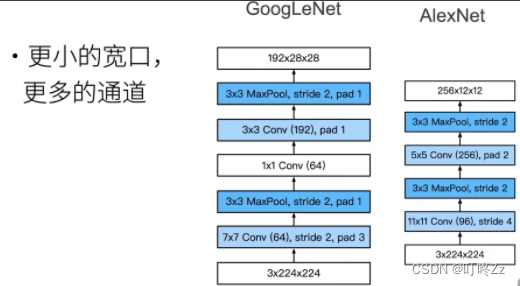
c . stage 3

d , stage 4 & 5
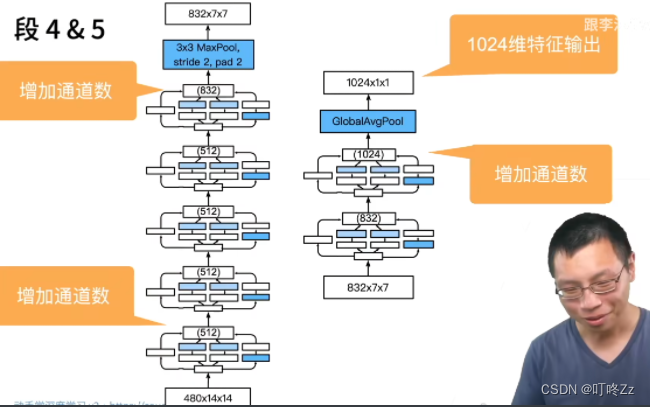
e . 总结

6 . 批量归一化(batch normalization)
a . 思想
方差和均值在不同层之间会变化,批量归一化就是在每一层的输出作为下一层输入时候进行归一化,使值固定在一个范围内,然后相对比较稳定
b . 总结
- 在模型训练过程中,批量规范化利用小批量的均值和标准差,不断调整神经网络的中间输出,使整个神经网络各层的中间输出值更加稳定。
- 可以加速收敛速度,但一般不改变模型精度
- 批量规范化在全连接层和卷积层的使用略有不同。
- 批量规范化层和暂退层一样,在训练模式和预测模式下计算不同。
- 批量规范化有许多有益的副作用,主要是正则化。另一方面,”减少内部协变量偏移“的原始动机似乎不是一个有效的解释。
7 . ResNet
a. 思想
? 一味的增加模型复杂度不一定能减少到最优解的距离,可能新加的层学习的方向偏了。所以ResNet想办法是每一次更复杂的模型是会包含原来的小模型作为子模型,所以至少不会变差,使得可以训练更深的网络
b . residual block(残差块)
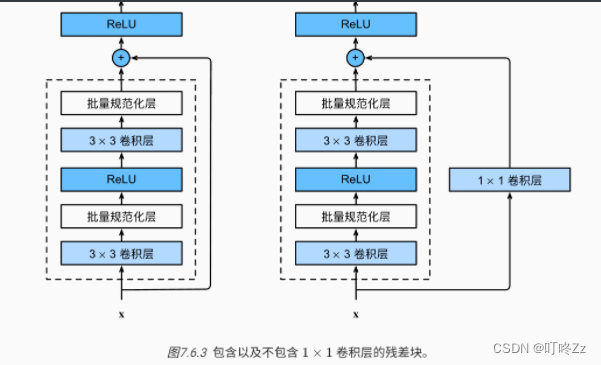
c . 处理梯度消失
? 1000层的ResNet怎么处理梯度消失,将层与层之间的梯度的乘法变成梯度之间的加法
d . bottleneck(瓶颈)

如果处理更深的网络,则处理的通道数会增加,然后这里先用一维卷积降低通道数,然后继续卷积提取特征,最后再通过一维卷积升通道数,这样降低了运算的复杂度
8 . 数据增强
? 将原始的数据进行变换(截取部分图片,对图片进行颜色变换等方法),得到了更多的样本,可以在更多的场景下识别目标
a . 常见的方法
- 上下翻转
- 切割
- 改变颜色
9 . 微调
在自己的模型训练开始时候,参数的初始化不是随机的初始化,而是调用的源数据集(更大的数据集)训练好了的参数
- 可以使用更小的学习率
- 更少的数据迭代
- 源数据集远复杂与目标数据集,微调效果更好
- 预训练模型质量很重要
- 微调通常速度更快,精度更高
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ArkTS语言基础入门学习-鸿蒙开发
- Angular系列教程之父子组件通信详解
- 动手学深度学习5 矩阵计算
- 【leetcode】下一个排列 双指针算法
- 如何解决找不到mfc100u.dll无法运行程序问题,分享四种靠谱的方法
- 代码随想Day55 | 392.判断子序列、115.不同的子序列
- 【Java】接口和抽象类有什么共同点和区别?
- MyBatis中的MapperScan的作用是干什么的?
- 深入Redis过程-持久化
- 中仕教育:选调生和考研可以一起准备吗?