Tensorflow 入门基础——向LLM靠近一小步
进入tensflow的系统学习,向LLM靠拢。
目录
1. tensflow的数据类型
1.1 数值类型
数值类型的张量是tensorflow主要的数据载体,根据维度数来区分,可分为:
- 标量Scalar:单个实数,如1,2,3,4等,维度数为0,shape为[]
- 向量Vector:n个实数的有序集合,如[1,2,5,62,21]等,维度为1,长度不定,shape为[n]
- 矩阵Matrix:n行m列实数的有序集合,如[[1,23],[2,32],[5,23]]的矩阵,维度数为2,每个维度上长度不定,shape为[n,m]
- 张量Tensor:所有维度数dim >2的数据统称为张量。张量的每个维度也作为轴Axis,一般维度代表了具体的业务含义,例如shape的张量[2,32,32,3]的张量共有4维,如果表图片数据,每个维度分别代表图片数量、图片高度、图片宽度、图片通道数,其中2代表了2张图片,32代表了高,宽均为32,3代表了RGB的3个通道。
在tensorflow中,一般将标量、向量、矩阵也都统称为张量,不作区分需要根据张量的维度数和形状自行判断。
- 创建一个标量,并查看数据类型
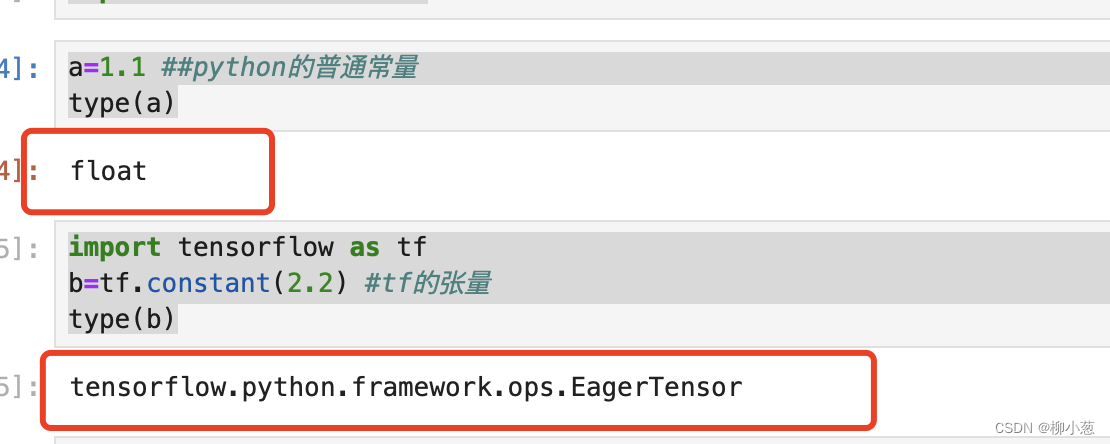
a=1.1 ##python的普通常量
type(a)
import tensorflow as tf
b=tf.constant(2.2) #tf的张量
type(b)
结果:(张量只能通过tf的函数去创建,不能使用python的普通语法创建)
2. 创建一个向量并展示向量信息
c=tf.constant([1,23,4,5,56])
c
结果:(id是tensorflow中内部索引的对象编号,shape表示张量的形状,dtype代表张量数职的精度值,张量numpy()方法可以返回Numpy.array类型的数据,方便到处数据到系统其他模块)

#将数据导出为numpy的array类型
c.numpy()

3. 与标量不同,向量的定义碧玺通过list传给tf.constant() 函数,例如创建一个和多个元素的向量:
##将一个元素的list转换为张量
d=tf.constant([1.2])

##多个元素的list转换为张量
e=tf.constant([1.2,13,14,151,15,15])

4. 创建矩阵张量原理同list
#创建矩阵张量
f=tf.constant([[1,2,3,4],[5,6,7,8]])
f

1.2 字符串类型
TF除了支持数值类型的张量之外,还支持字符串类型的数据,例如在表示图片数据时,可以先记录图片的路径字符串,再通过预处理函数根据路径读取图片张量。
- 创建字符串张量
a=tf.constant('hello,DEEP learning!')
a

- tf还提供了一些2字符串类型的工具函数,如小写化lower()、拼接join()、长度length()、切分split()等。
tf.strings.lower(a) #小写化字符串

但是在tf中最常用的还是数字类型的数据,因此字符类型的数据的函数不做过多赘述。
1.3 布尔类型的数据
为了方便表达比较运算操作的结果,tf还支持布尔类型的张量,布尔类型张量只需要传入python语言的布尔类型数据,转换成为内部布尔类型即可。
- 创建布尔类型的张量
a=tf.constant(True)
a

2. 创建布尔类型的向量
b=tf.constant([True,False])
b

3. tf的布尔类型和python的布尔类型并不等价,不能通用
a=tf.constant(True)
a is True

2. 数值精度
对于数值类型的张量,可以保存为不同字节长度的精度,如浮点数3.14即可以保存为16位(bit)长度,也可以保存为32位甚至64位的精度。位越长,精度越高,同时占用的空间也就越大,常用的精度类型有tf.int16、tf.int32、tf.int64、tf.int64、tf.float16、tf.float32、tf.float64等,其中tf.float64即为tf.double。
tf.constant(123456789,dtype=tf.int16)
tf.constant(123456789,dtype=tf.int32)
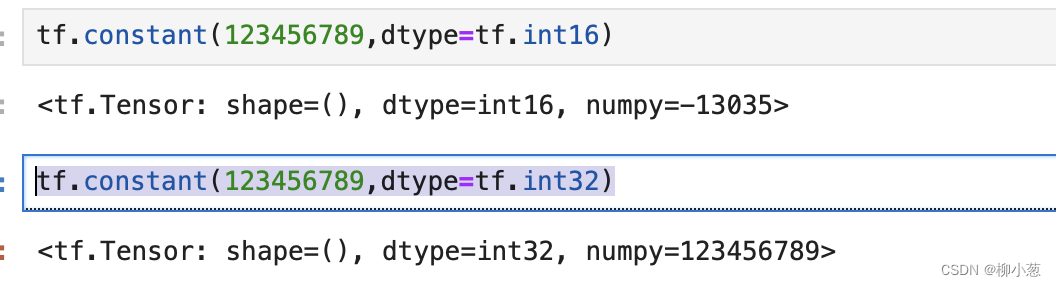
可以看到,保存精度过低,数据123456789发生了溢出,得到了错位的结果,一般使用tf.int32、tf.int64精度,对于浮点数,高精度的张量可以表示更精准的数据,例如:采用tf.float32精度2保存’pai’ 时,实际保存为的数据位3.1415927.
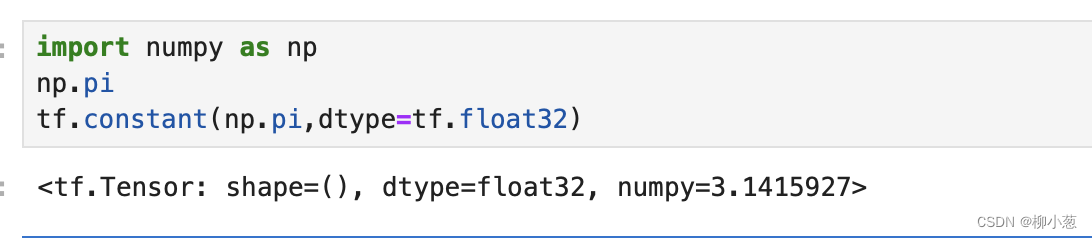
import numpy as np
np.pi
tf.constant(np.pi,dtype=tf.float32)
如果采用tf.float64精度保存,则能够获得更高的精度,实现如下:
tf.constant(np.pi,dtype=tf.float64)

3. 类型转换
系统的每个模块使用数据类型,数值类型可能各不相同,对于不符合要要求的张量的类型及精度,需要通过tf.cast函数进行转换,例如:
a=tf.constant(np.pi,dtype=tf.float16)
tf.cast(a,tf.double)

进行类型转换时,需要保证转换操作的合法性,例如将高精度的张量转换为低精度的张量时,可能发生数据溢出隐患:
a=tf.constant(123456789,dtype=tf.int32)
tf.cast(a,tf.int16)

布尔类型与整型之间互信转型是合法的,是比较常见的操作:
a=tf.constant([True,False])
tf.cast(a,tf.int32)

一般末日0表示false,1表示True,在tf中,将非0数字,都视为True,例如:
a=tf.constant([-1,0,1,2])
tf.cast(a,tf.bool)

3.1 待优化的张量
为了区分需要计算梯度信息的张量与不需要计算梯度信息的张量,TF增加了一种专门的数据类型来支持梯度信息的记录:tf.Variable。tf.Variable类型在普通的张量类型的基础上增加了name、trainable等属性来支持计算图的构建。由于梯度运算会消耗大量的计算资源,而且会自动更新相关参数,对于不需要优化的张量,如何神经网络的输入X,不需要通过tf.Variable封装;相反,对于需要计算梯度优化的张量,如神经网络层的W和b,需要通过tf.Variable包裹以便TF跟踪梯度信息。
例如tf.Variable() 函数可以将普通张量转换为待优化的张量:
d=tf.constant([-1,0,1,2])#创建tf张量
b=tf.Variable(d)#转换为variable类型

其中name和trainable是variable特有的属性,name属性用于命名计算图中的变量,这趟命名体系是TF内部维护的,一般不需要用户关注name属性,trainable属性表示当前张量是否被优化,创建variable对象时是默认启用优化标志,可以设置trainable=false来设置张量不需要优化。
除了通过普通的方式创建variable,就可以之间创建,例如:
a=tf.Variable([1,2],[3,4])#直接创建variable张量
a

4 创建张量
创建tf中,可以通过多种方式创建张量,如从python列表对象创建,从numpy数组创建,或者创建采样自某种已知分布的张量等。
4.1 从数组、列表对象创建
Numpy array 数据和python list 列表是python程序中间非常重要的数据载体,很多数据通过python语言将数据加载至array 或者 list,再转化为Tensor类型,通过TF运算处理后导入到array或者list。方便其他模块调用。
通过tf.convert_to_tensor函数可以创建新Tensor,并保存在python list 对象或者numpy array 对象中的数据导入到Tensor:
tf.convert_to_tensor([1,2.])

import numpy as np
tf.convert_to_tensor(np.array([[1,2],[3,4]]))

注意,numpy 浮点数数组默认使用64位精度保存数组,转换到tensor类型时精度位tf.float64,可以在需要时将其转换为tf.float32类型。
实际上,tf.constant() 和tf.convert_to_tensor() 都能够自动地把numpy 数组或者python列表数据类型转化为Tensor类型。
4.2 创建全0或者1张量
将张量创建为全0或者全1数据是非常常见的张量初始化手段。考虑线性变换y=wx+b,将权值权值矩阵w初始化为全1矩阵,偏置b初始化为全0的向量,此时线性变化层输出y=x,因此是一种比较好的层初始化状态,通过tf.zero() 和 tf.ones() 即可创建任意形状,且内容全0或者全1的张量。创建全0和1的标量:
tf.zeros([]) #创建全0的标量
tf.ones([]) #创建全1的标量

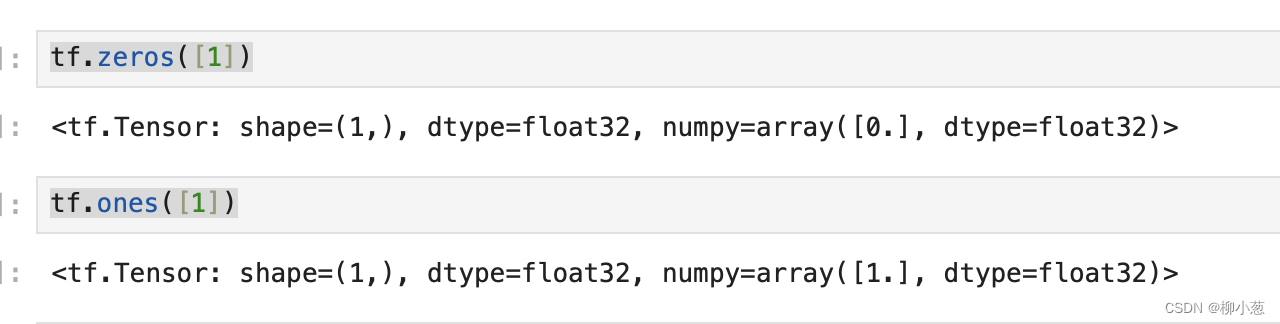
创建全0和全1的向量:
tf.zeros([1]) #创建全0的向量
tf.ones([1]) #创建全1的向量
通过tf.zeros_like,tf.ones_like 可以方便地新建与某个张量shape 一致,且内容为全0或全1的张量。例如创建一张张量A形状一样的全0张量:
a=tf.ones([2,3])
tf.zeros_like(a)

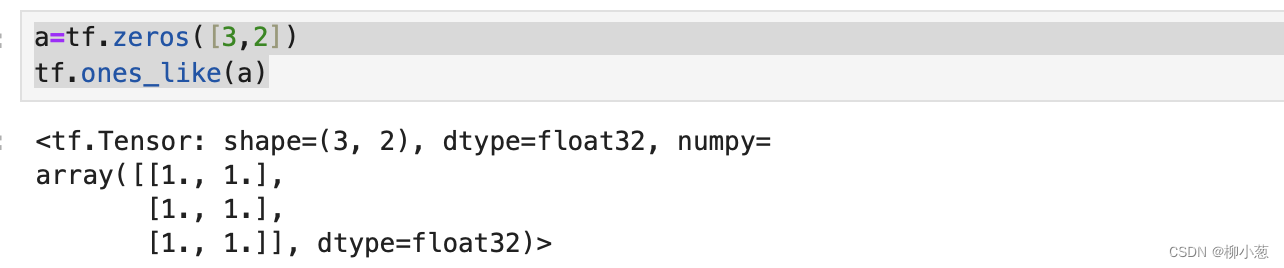
a=tf.zeros([3,2])
tf.ones_like(a)
tf. *_like 是一系列的便捷函数,可以通过tf.zero(a.shape)等方式实现。
4.3 创建自定义数值张量
除了初始化为全0,或者全1的张量之外,有时也需要全部初始化为某个自定义数值的张量,例如将张量的数值全量初始化为-1等。
通过tf.fill(shape,value),可以创建全自定义数值value的张量,形状有shape参数制定。例如:
- 创建所有元素为-1的标量:
tf.fill([],-1) #创建-1的标量

- 创建所有元素为-1的向量
tf.fill([1],-1)#创建-1的向量

- 创建所有元素为99的向量
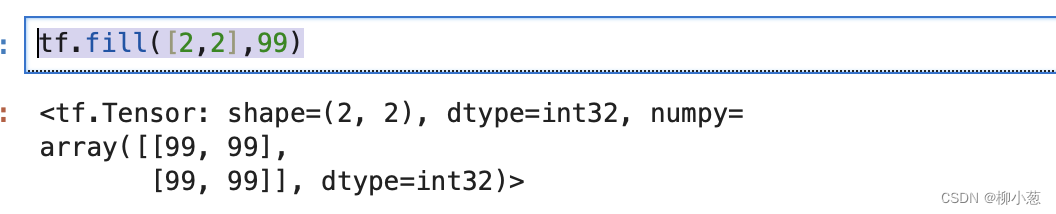
tf.fill([2,2],99)#创建2行2列,元素全为99的矩阵
5. 创建已知分布的张量(正态和均匀分布)
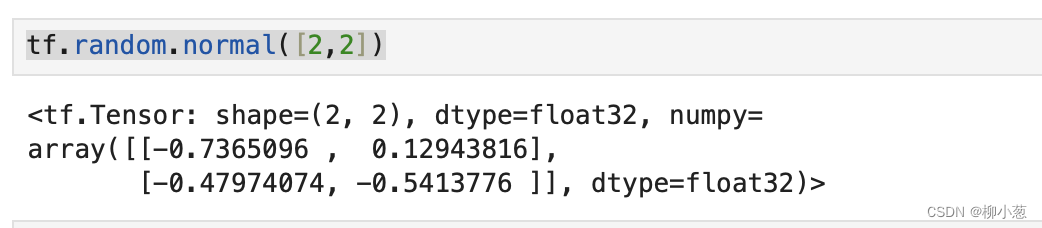
正态分布和均匀分布是常见的分布之一,通过tf.random.normal(shape,mean=0.0,stddev=1.0) 可以创建形状为shape,均值mean,标准差为stddev的正态分布N(mean,stddev^3)。例如,创建均值为0,标准差1的正态分布:
tf.random.normal([2,2])
创建均值为1,标准差为2的正态分布:
tf.random.normal([2,2],mean=1,stddev=2)

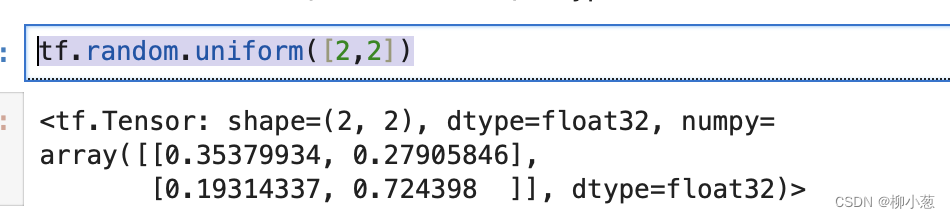
通过tf.random.uniform(shape,minval=0,maxval=none,dtype=tf.float32)可以创建采样自[minval,maxval]区间的均匀分布的张量。例如:
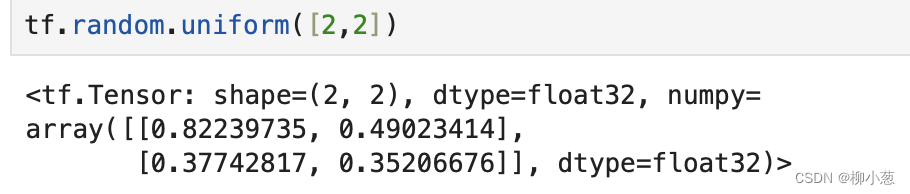
tf.random.uniform([2,2])#创建采样自区间[0,1],shape=[2,2]的矩阵:
创建采样区间在[0.10],shape为[2,2]的矩阵:
tf.random.uniform([2,2])
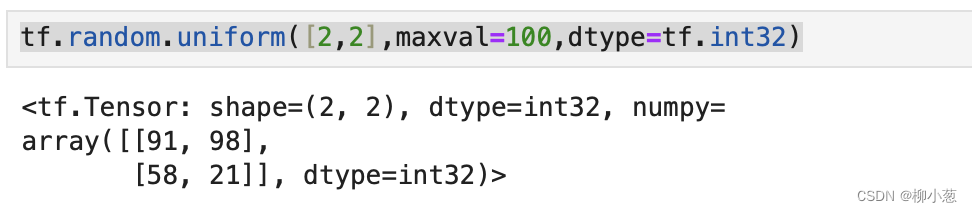
如果需要均匀采样整型类型的数据,就必须指定采样区间最大值maxval参数,同时指定数据类型为tf.int*类型:
tf.random.uniform([2,2],maxval=100,dtype=tf.int32)#创建采样自[0.100]均匀缝补的整形矩阵
6 创建序列
如果需要快速创建序列,可以使用range( x,delta=1)函数,创建[0,x),步长为delta的整型序列
tf.range(10)#创建步长为1,0-10的数据序列

tf.range(10,delta=2)#创建步长为2,0-10的数据序列

创建[2,10),步长为2的序列:
tf.range(2,10,delta=2)

参考资料
- TensorFlow深度学习
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!