探索InnoDB的自适应哈希索引
🌈🌈🌈🌈🌈🌈🌈🌈
欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术 的推送
发送 资料 可领取 深入理解 Redis 系列文章结合电商场景讲解 Redis 使用场景、中间件系列笔记和编程高频电子书!
文章导读地址:点击查看文章导读!
🍁🍁🍁🍁🍁🍁🍁🍁
探索InnoDB的自适应哈希索引

在学习 MySQL 的时候,学的最多的也就是 B+ 树索引,但是其实还有一种索引:哈希索引,很容易在学习的过程中忽略了
之前面试的时候,就碰到一个面试官,提问哈希索引相关的知识,但是学习的时候给忽略了,也就回答的不太好,这里整理一下哈希索引的相关内容,可以全面了解一下哈希索引到底是什么东西!
如何创建哈希索引?
这里都以 InnoDB 存储引擎为例
如果我们创建一张表,为某些字段添加索引时指定 HASH 索引,如下:

但是当创建完之后,发现最后还是使用了 BTREE 索引
经过实践验证,发现我们是 无法手动创建 HASH 索引的
那么哈希索引是什么时候创建的呢?
InnoDB 中的哈希索引其实也就是 自适应哈希索引(Adaptive Hash Index)
InnoDB 会自动检测某些索引值是否使用的非常频繁
通过自动创建 自适应哈希索引 来提高查对热点数据的访问速度,特别是在频繁执行等值查询的情况下
怎么建立哈希索引的呢?
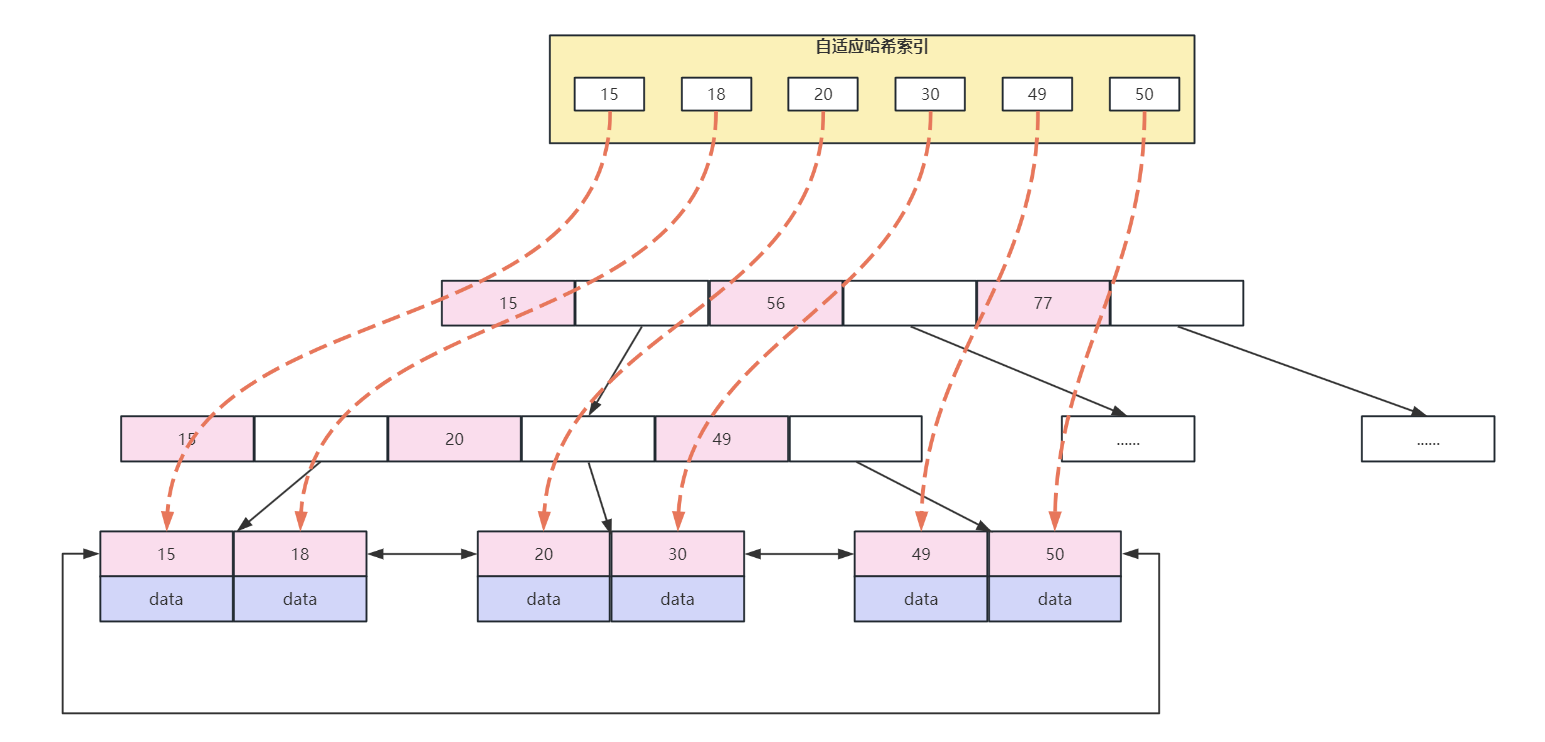
如果 InnoDB 发现某些数据页被频繁命中的时候,就会在自己的 Buffer Pool 中开辟一块区域创建 自适应哈希索引,以提高查询速度
通过建立自适应哈希索引,可以缩短通过索引寻找数据的 路径
自适应哈希索引相关参数
innodb_adaptive_hash_index
通过该参数设置自适应哈希索引是否启用,默认启用
set persist innodb_adaptive_hash_index = on;
set persist innodb_adaptive_hash_index = off;
innodb_adaptive_flushing
该参数是用来控制刷新脏页,默认启用
当 启用 时,InnoDB 会根据系统的负荷以及脏页的数量动态调整脏页的刷新策略,可以在保证数据持久性的同时,减少不必要的磁盘 IO,提升数据库性能
当 关闭 时,InnoDB 会采用固定的刷新策略,即定期将脏页刷到磁盘中,这种策略可能在系统空闲时造成不必要的磁盘 IO
innodb_adaptive_flushing_lwm
该参数用来设置 redo log flush 的低水位线(low watermark),用于控制自适应刷新的脏页数量(自适应刷新指根据系统负荷和脏页的数量来调整脏页的刷新策略)
通过这个参数设置一个阈值,当脏页数量小于阈值时,InnoDB 会减少刷新频率
如果 innodb_adaptive_flushing_lwm 设置为 10,这个 10 表示脏页数量与 InnoDB 缓冲池大小的比例,即如果当脏页数量低于缓冲池大小的 10% 时,InnoDB 会减少刷新脏页的频率,最小为 0,最大为 70
官方介绍
自适应哈希索引使得 InnoDB 在恰当的工作负载以及充足的 Buffer Pool 内存系统中,可以表现得更加像一个 内存数据库,并且无需牺牲事务特性以及可靠性
基于观察到的搜索模式,哈希索引是使用索引 key 的前缀来构建的,前缀可以是任意长度,并且可能只有 B 树中的某些值才出现在哈希索引中,哈希索引是根据需要为 需要经常访问的索引页 构建的
如果表几乎完全适合内存,则哈希索引可以通过直接查找元素、将索引值转换为指针来提升查询速度,InnoDB 有一个监视索引搜索的机制,如果 InnoDB 注意到通过哈希索引查询可以变得更快,它就会自动创建
对于有些情况来说,哈希索引带来的加速远远超过监视索引和维护哈希索引的代价,在繁重的工作负载下,自适应哈希索引的访问有时会成为争用的根源,如很多并联操作,Like 和 % 运算符也往往不会从哈希索引中受益,对于无法受益的情况下,可以关闭自适应哈希索引,以免带来不必要的性能开销,请考虑在启用和禁用它的情况下运行基准测试
自适应哈希索引的特性是 分区,每一个索引绑定到特定的分区,每个分区都由单独的锁存器保护,分区由innodb_adaptive_hash_index_parts 控制,默认为 8,最大为 512
可以通过 SHOW ENGINE INNODB STATUS 来查看输出的 SEMAPHORES 来查看监视的自适应哈希索引的使用和征用,如果有大量线程在等待 btr0sea.c 中创建的 rw-latches,可以考虑增加自适应哈希索引分区的数量或者禁用自适应哈希索引
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 通过栈将中缀表达式转换为等价的后缀表达式
- Spring AOP 源码分析
- OpenCV-Python(22):直方图反向投影
- 为什么需要使用TC油封?
- npm run dev,vite 配置 ip 访问
- Ansible
- 统一门户开发框架之高效内容管理:小程序技术
- 【cesium-5】鼠标交互与数据查询
- 【运维日常】nginx 413 Request Entity Too Large
- Vulnhub-HACKSUDO: PROXIMACENTAURI渗透