【具身智能评估3】具身视觉语言规划(EVLP)度量标准汇总
参考论文:Core Challenges in Embodied Vision-Language Planning
论文作者:Jonathan Francis, Nariaki Kitamura, Felix Labelle, Xiaopeng Lu, Ingrid Navarro, Jean Oh
论文原文:https://arxiv.org/abs/2106.13948
论文出处:Journal of Artificial Intelligence Research 74 (2022) 459-515
论文被引:27(11/19/2023)
目前在 EVLP 中使用的度量标准可分为五类,分别从不同角度测量智能体性能:
- (i)成功率(success)
- (ii)距离(distance)
- (iii)路径-路径相似性(path-path similarity)
- (iv)基于指令的度量标准(instruction-based metrics)
- (v)物体选择度量标准(object selection metrics)
1. Success
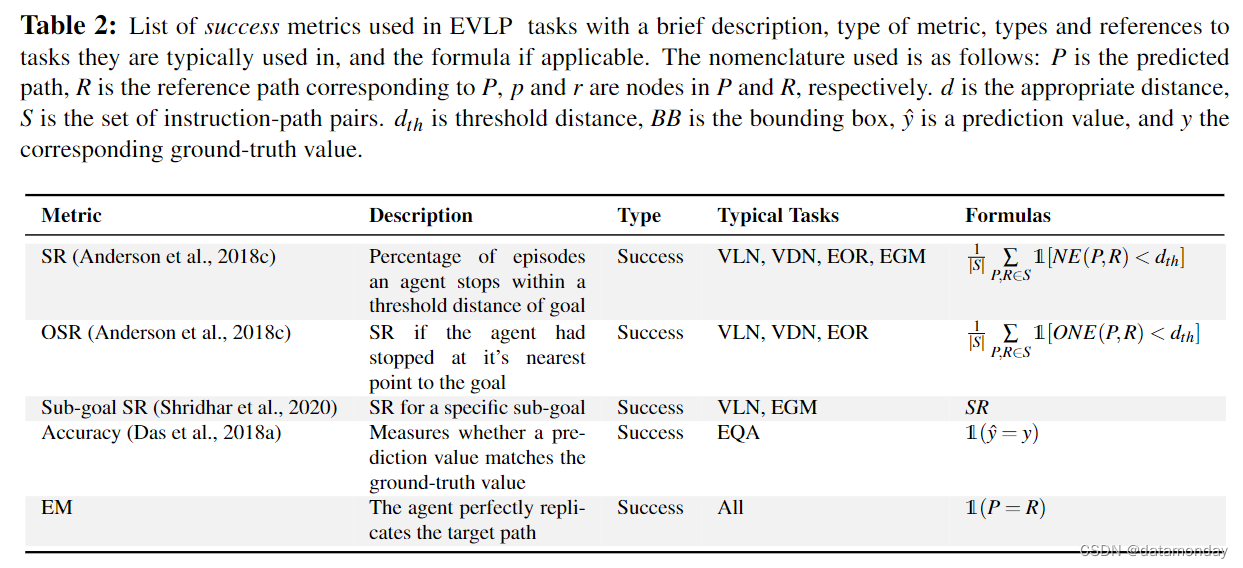
评估智能体是否成功完成任务的指标在所有 EVLP 任务中都有不同形式的应用。VLN 和 VDN 等指令遵循任务通常将成功率 (Success Rate,SR)定义为智能体距离目标 d t h d _{th} dth? 在阈值距离范围内的比例。不同数据集的距离 d t h d _{th} dth? 各不相同,
- R2R 的 d t h d _{th} dth? = 3m(Chang et al.,2017)
- Lani 的 d t h d _{th} dth? = 0.47m(Misra et al.,2018)
这种测量方法有一些弱点,特别是对于离散化的状态-动作空间(state-action spaces),它相当依赖于所述离散化的粒度(Thomason et al.,2019a;Krantz et al.,2020)。此外, d t h d _{th} dth? 的变化也会影响 SR,这可能会产生误导性结果,正确的执行可能会被认为是错误的(Blukis et al.,2019)。
EQA 没有目标位置的概念;相反,成功与否是根据输出空间的准确性来衡量的,即问题解答的准确性(Das et al.,2018a;Gordon et al.,2018)。其他可以使用的常用分类指标包括(Valuations,2015):
- 精度
- 召回率
- F 分数
这些指标中的任一指标的每类性能也可用于衡量模型是否通过输出常见回复来提高准确率,而这是以牺牲少数类别的性能为代价的。
在大多数情况下,只有当智能体接近最终目的地,回答问题或满足操作指令后,任务才被视为 “complete”。不过,某些数据集,如 ALFRED(Shridhar et al.,2020),Lani(Misra et al.,2018)和 CerealBar(Suhr et al.,2019)也会报告子目标完成情况。例如,增加子目标评分有助于利用子任务的模块性和层次性(Shridhar et al.,2020;Jansen,2020),或缓解成功度量的问题,例如任务早期的失败会影响后面的步骤(Suhr et al.,2019),从而难以评估每个时间步的智能体能力。为了解决这个问题,CerealBar 将轨迹 T 评估为 |T | - 1 个子路径,每个子路径都比下一个短:取这些运行的平均成功率,衡量模型从错误中恢复的能力。子目标评分的另一个好处是,可以更容易地找出具体的智能体错误并进行分类。
2. Distance
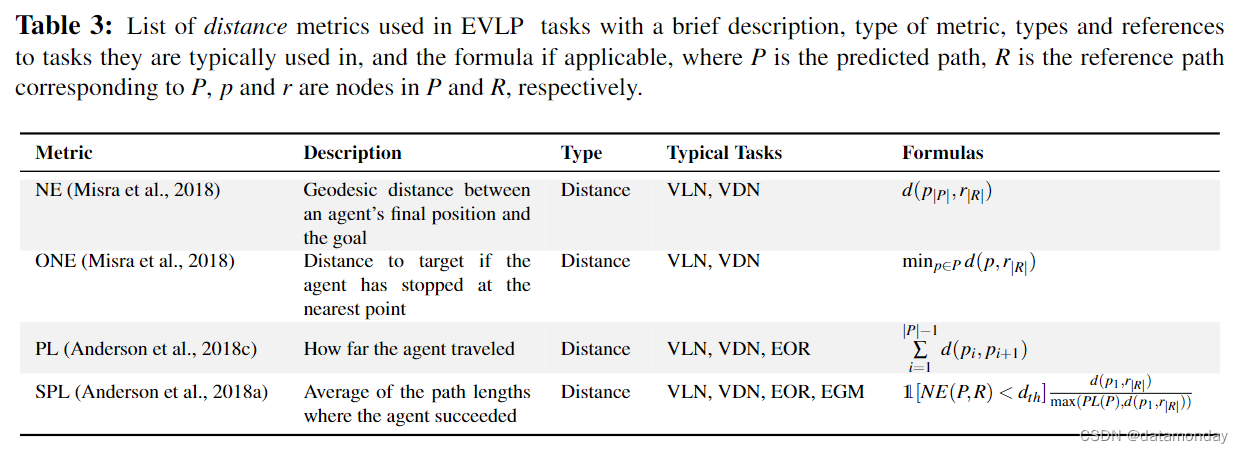
虽然成功率是一种直观的衡量标准,但它所提供的关于智能体在空间中行进效率的信息非常有限。在导航和操作任务中,距离度量可以量化这类信息。这方面的两个有用指标:
- 导航/位移误差(Navigation Error,NE):衡量的是智能体在距离目标位置多远时选择停止,从而提供智能体无法到达目标位置的程度信息。为了进一步分析智能体是否学会了有效地停止,NE 通常与 Oracle 导航误差(Oracle Navigation Error,ONE)相结合。
- ONE:测量的是沿智能体轨迹到目标位置最近点的距离。
- NE和ONE测量值的显著差异可能表明在停止方面存在问题。
- 导航/位移所需的总行程/运动,即路径长度(Path Length,PL):NE 和 ONE 测量方法假定任务有一个指定的目标或目标位置。就 VLN 和 VDN 而言,这是一个合理的假设。然而,对于 EQA,甚至是 EGM 来说,情况未必如此。例如,在 EQA 中,某些问题(如有关物体状态的问题)的答案可能来自房间的不同点。与其评估离目标的距离,不如考察所走路径的长度(PL)。在现实世界中,最大限度地缩短路径长度是一个重要的考虑因素。为了只考虑成功的路径,可以通过归一化反路径长度(SR weighted by normalized inverse Path Length,SPL)计算加权 SR。
从本质上讲,距离不仅可用于推导 VLN 和 VDN 的成功指标,还可用于量化智能体路径的误差和效率。就导航而言,这衡量的是导航员偏离目标的程度。这为评估和比较模型性能增加了一个维度。
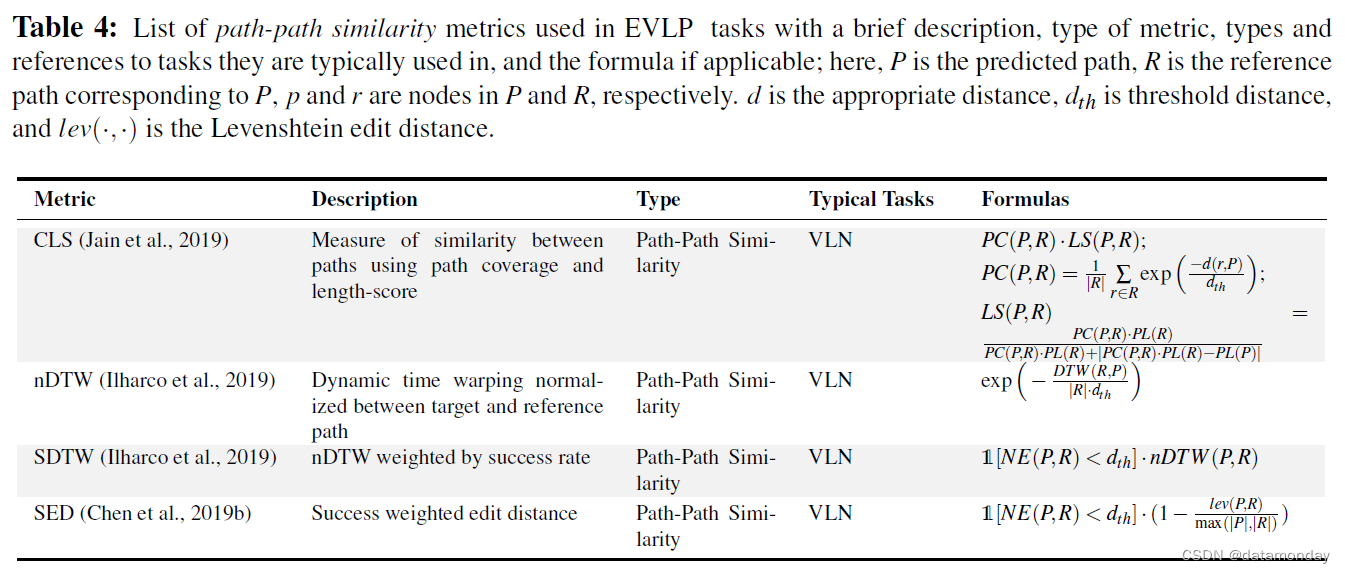
3. Path-Path Similarity
距离度量无法捕捉到智能体是否遵循了真实路径(ground-truth path)。对于 VLN 和 VDN 等遵循指令的任务,用户会指定一条带有指令的路径,我们可能希望明确遵循这些指令,而不是寻找最短路径。Jain et al.(2019)讨论了路径相似度度量的必要条件:
- 度量标准应衡量所走路径与参考路径之间的保真度(fidelity),而不仅仅是目标。
- 错误不应该是硬性惩罚,度量标准应该偏向于偏离并遵循真实路径(ground-truth path)的路径,而不是完全缩短真实路径的路径。
- 最大值应该是唯一的,只有在完全匹配的情况下才会出现。
- 数据集的基本规模不应影响输出的价值。
- 指标应允许快速自动性能评估。
我们相信,这些需求可以更广泛地应用于任何指令跟随任务。早期衡量路径跟随的指标之一是编辑距离(Chen et al.,2019b)。
- 编辑距离(Edit Distance,ED)衡量的是匹配两个图形所需的变化次数。ED 不符合标准 #2,因为它只根据绝对偏差进行惩罚。
- Jain et al.(2019)引入了覆盖率加权长度得分(Coverage weighted by Length Score,CLS),这是一种满足上述所有 5 条标准的度量方法。CLS 由路径覆盖率(目标路径与参考路径之间平均每点重叠程度的度量)与长度得分的乘积得出,长度得分会对比参考路径短和比参考路径长的路径进行惩罚。Jain et al.(2019)将其作为基于 RL 的智能体的目标,验证了它的实用性。
Ilharco et al.(2019)在此基础上提出了两种测量方法:
- 归一化动态时间规整(normalized Dynamic Time Warping,nDTW):是一种相似性函数,用于识别参考路径和查询路径中元素的最优规整。
- 成功加权归一化动态时间规整(Success weighted by normalized Dynamic Time Warping,SDTW):将 nDTW 限制为成功的轮数(episodes)。
这些度量指标具有许多理想的特性:它们尊重上述理想条件,可有效用作基于 RL 的智能体的奖励信号,并可与人类判断进行比较。与 CLS、SPL、SR 等替代方案相比,这些特性使它们始终更受青睐。
4. Instruction-based
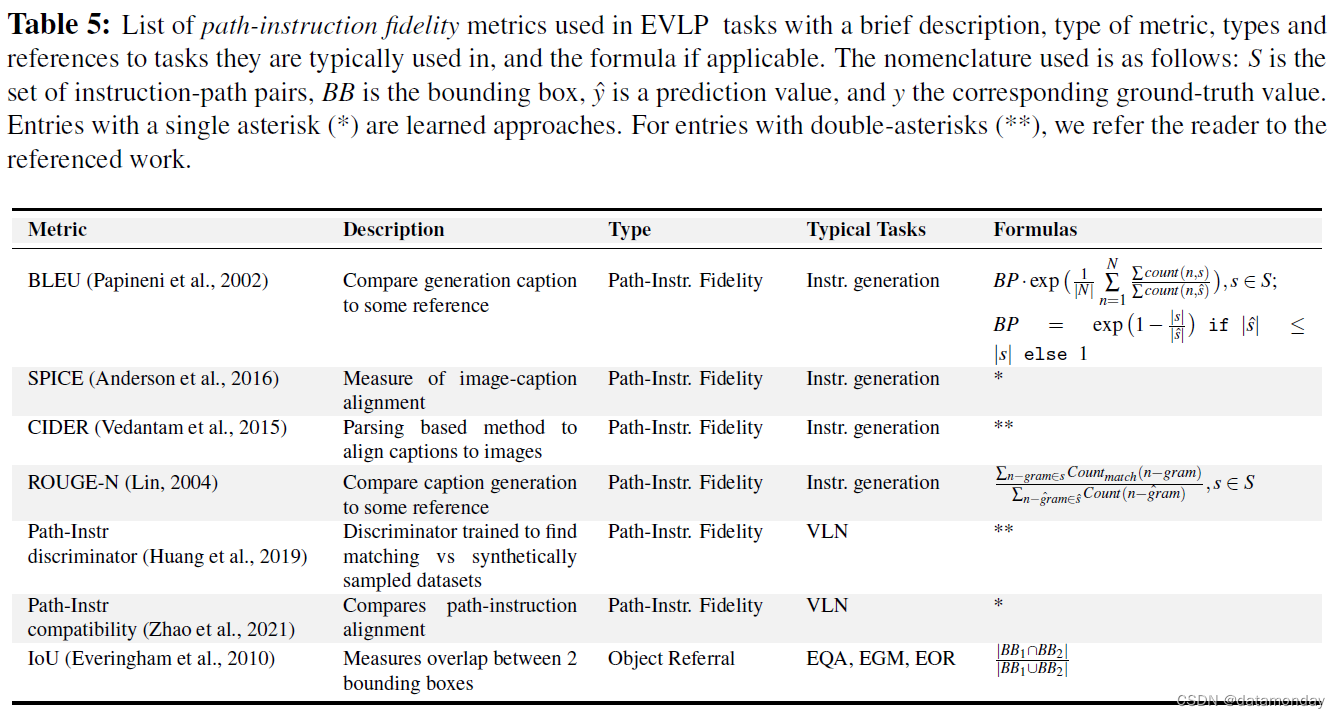
不同的方法可用于衡量图像和文本形式的路径之间的对齐:
- 语义命题图像描述评估(Semantic Propositional Image Caption Evaluation,SPICE):(Anderson et al.,2016)
- 基于共识的图像描述评估(Consensus-based Image Description Evaluation,CIDEr):(Vedantam et al.,2015)
虽然这些方法最初用于 VQA,但最近也被改用于 VLN(Zhao et al.,2021)。
对齐度量也可作为训练的一部分。
- 某些方法(Fried et al.,2018b;Tan et al.,2019)会生成合成指令,以增加不同质量的可用数据。
- Huang et al.(2019)训练了一个对齐模型,其中使用 BiLSTM 对指令和路径进行编码,并输入二分类分类器。正输出分配给匹配的路径指令对,负输出分配给不匹配的指令路径对。然后,二分类分类器器被用作对路径进行排序的评分函数。得分低的路径将从训练中删除,从而在减少总数据集大小的同时,显著提高性能。
5. Object Referral
EGM 和 EOR 需要通过遮蔽或从真实边界框中选择目标。Chen et al.(2019b)和 Shridhar et al.(2020)使用交并比(Intersection over Union,IoU)作为评估指标,这是 CV 中常用的指标,特别是在目标检测任务中(Padilla et al.,2020)。然而,这并不是唯一的指标,也不是信息量最大的指标。
最近,Kim et al.(2020)提出了三个指标来评估目标的选择效果:
- 收集目标正确性(Collected Target Correctness,CTC)
- 放置目标正确性(Placement Target Correctness。PTC)
- 对等放置目标距离(reciprocal Placement Object Distance,rPOD)
CTC 衡量选择的目标是否正确;PTC 衡量放置的目标是否正确。需要注意的是,CTC 和 PTC 都可以看作是阈值 IoU 问题,因为有些智能体(Shridhar et al. 2020)就是这样决定是否拾取一个目标的。rPOD 是一种标准化的测量方法,如果物体的摆放位置与理想位置相差甚远,则得分为接近零分;如果摆放位置完全正确,则得分为 1 分。
虽然只适用于 EGM 和 EOR,但测量目标选择交互的质量也很重要。这是任务的另一个方面,也是了解语言的哪些方面对模型来说更难的一个好方法。目标识别方面的最新研究(Padilla 等人,2020 年)表明,有许多衡量标准和变体。在这些任务中,即使是更传统的指标,如精度、召回率和 F 分数,目前也没有报告。这样做可以提供更多有关边界框准确性的信息。此外,我们还可以报告每个类别的准确率,这将有助于识别哪些目标未被模型检测到。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 苹果紧急修复两大零日漏洞,影响iPhone、iPad 和 Mac 设备
- 3‘aTWAS—3‘adapter-based transcriptome-wide association study
- 基于 IDEA 进行 Maven 工程构建
- 数据存储模式与验证方法 & 字符串系列函数 & 指针 & 冒泡排序
- Go语言基础:深入理解结构体
- DshanMCU-R128s2 R128 模组
- 03 SpringBoot实战 -微头条之首页门户模块(跳转某页面自动展示所有信息+根据hid查询文章全文并用乐观锁修改阅读量)
- SpringFrame框架无法添加Sring Config如何解决
- NFTScan | 01.08~01.14 NFT 市场热点汇总
- 24. 两两交换链表中的节点