计算机系统基础知识揭秘:硬件、处理器和校验码
计算机系统基础知识揭秘:硬件、处理器和校验码
一、计算机系统基础知识的重要性
-
理解整个计算机系统的工作原理和逻辑结构,有利于更深入地学习和理解计算机科学和工程领域的相关知识。
-
对计算机硬件、软件和系统进行故障排除、优化和性能调整时,有深厚的基础知识能够提高效率和准确度。
-
理解计算机系统基础知识有助于培养扎实的计算机科学和工程专业素养,从而提高解决技术问题的能力。
-
在处理计算机安全和网络问题时,了解计算机系统基础知识使人们能够更好地理解攻击者的行为,以及如何加强系统安全性。
-
对于软件工程师和系统管理员来说,了解计算机系统的基础知识能够帮助更好地设计和维护软件系统。
本文将深入探讨计算机系统基础知识,内容主要包括硬件、处理器、数据表示和校验码四个部分。介绍计算机硬件的基本组成,包括中央处理器(CPU)、内存、存储设备和输入输出设备等,探讨校验码的概念、类型和应用场景,以及校验码的计算和验证方法。
二、计算机系统硬件
计算机系统由硬件和软件组成,他们协同工作来运行程序。计算机系统的基本硬件由:运算器、控制器、存储器、输入设备和输出设备五个部分组成 。其中运算器、控制器等部件被集成在一起统称为中央处理单元(Central Processing Unit,CPU),它是计算机硬件系统的核心,负责执行计算机程序中的指令(各种算数、逻辑运算),控制和协调计算机系统的各个部件(即控制功能)。存储器是计算机系统中的记忆设备,分为内部存储器和外部存储器。内部存储器(RAM)的速度快、容量小,用于临时存储数据和程序,CPU需要从内存中读取数据和指令进行处理。外部存储器容量大、速度慢,用于长期存储数据和程序的设备,包括硬盘驱动器、固态硬盘、光盘等。输入设备用于将数据和指令输入到计算机系统中,例如键盘、鼠标、触摸屏等。输出设备用于将计算机处理后的数据和结果输出,例如显示器、打印机、音频设备等。输入设备和输出设备合称为外部设备(简称外设)。
其他组成:
- 主板:连接和支持计算机系统中各个部件的主要电路板。
- 电源:提供电能支持计算机硬件正常运行的设备。
2.1、内存和存储设备
内存(RAM)的作用:
- 临时存储正在运行的程序和数据,包括操作系统、应用程序和用户数据。
- 提供给CPU快速访问数据和指令的能力,加快计算机的运行速度。
- 内存的读写速度比存储设备快,适合用于临时存储和处理数据。
内存的分类:
- 随机存取内存(RAM):包括动态随机存取内存(DRAM)和静态随机存取内存(SRAM)等,用于临时存储程序和数据。
- 只读存储器(ROM):包括基本输入/输出系统(BIOS),存储固化的程序和数据,不易被修改。
存储设备的作用:
- 长期存储计算机程序、操作系统、用户数据等,保持数据持久性。
- 提供了大容量的存储空间,可以存储大量的数据和文件。
存储设备的分类:
- 硬盘驱动器(HDD):通过磁盘上的旋转磁盘和磁头进行数据读写,具有较大的存储容量和较低的成本。
- 固态硬盘(SSD):使用闪存存储技术,具有较快的读写速度和较低的能耗,但成本较高。
- 光盘(CD/DVD/Blu-ray):使用激光技术进行数据的读写,适合用于光盘媒体的存储和共享。
2.2、输入输出设备
外设负责将数据输入到计算机,同时将计算机处理后的数据输出到用户。
输入设备的作用:允许用户将数据和指令输入到计算机系统中,方便计算机对其进行处理。常见的输入设备包括键盘、鼠标、触摸屏、扫描仪等。
输出设备的作用:将计算机处理后的数据和结果呈现给用户,使用户能够看到计算机的输出信息。常见的输出设备包括显示器、打印机、音频设备(扬声器或耳机)等。
输入和输出设备常见的连接方式:
- USB(通用串行总线):用于连接键盘、鼠标、打印机、摄像头等设备。
- HDMI(高清晰度多媒体接口):用于连接显示器、电视等视频设备。
- 音频接口:用于连接音箱、耳机、麦克风等音频设备。
- 网络接口:用于连接计算机到局域网或互联网。
通过不同的接口与计算机系统连接让数据能够在设备和计算机之间双向传输。
三、中央处理器(CPU)
中央处理器(CPU)是计算机中最重要的部件之一,它负责获取程序指令、对指令进行译码并执行。
功能:
- 执行指令:CPU通过执行指令来 控制程序 的执行顺序。接收来自内存的指令,解码并执行这些指令,包括数学运算、逻辑操作、数据移动等操作。
- 控制数据操作:CPU控制数据的输入、输出和转移,以确保数据在计算机系统中的正确流动和处理。
- 时间控制。
- 数据处理。CPU最根本的任务。
- 中断响应:对系统内部和外部的中断(异常)做出响应。
CPU主要由 运算器、控制器、寄存器组和内部总线等部件组成 。
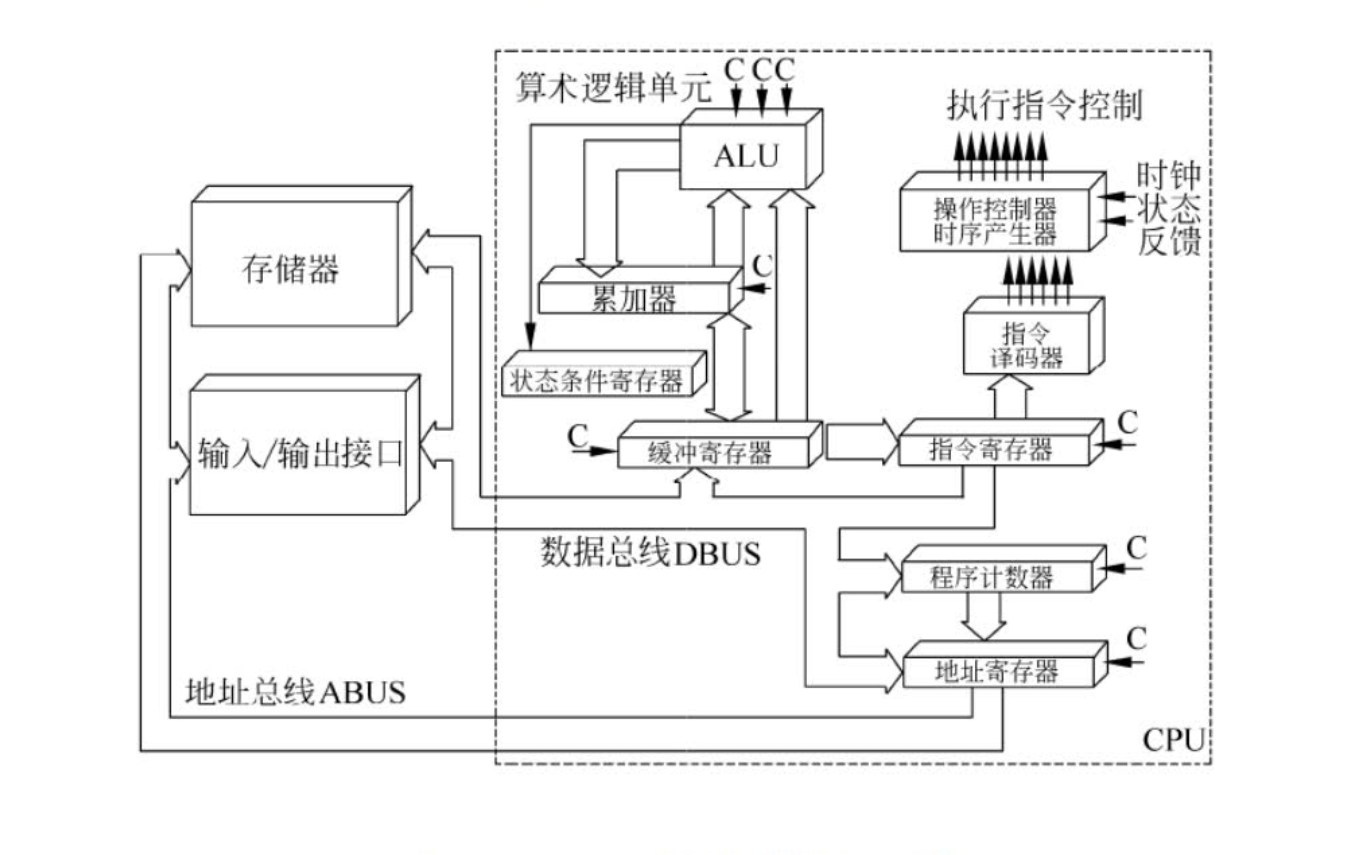
- 控制单元(Control Unit):控制单元负责指挥CPU中的其他部件,根据指令对数据进行处理与操作。
- 算术逻辑单元(Arithmetic Logic Unit, ALU):ALU执行算术运算(如加法、减法等)和逻辑运算(如与、或、非等),是CPU实际执行指令的部分。
- 寄存器(Registers):寄存器是一种小型的、高速的内部存储器,用于临时存储指令、数据和地址,包括程序计数器、指令寄存器、数据寄存器等。
- 数据总线(Data Bus):数据总线是CPU与其他组件之间传输数据的通道,可以双向传输数据。
3.1、运算器
运算器是计算机中的一个核心部件,它由算数逻辑单元(Arithmetic Logic Unit, ALU)、累加寄存器、数据缓冲寄存器和状态条件寄存器等组成。负责数据加工,执行各种算术运算和逻辑操作。
运算器是执行部件,接收控制器的命令来进行动作,即全部操作都是由控制器发出的控制信号来指挥的。运算器的主要功能包括:
- 算术运算:包括加法、减法、乘法和除法等基本的数学运算。
- 逻辑运算:包括与、或、非、异或等逻辑运算,通常用于处理信息的真值。并进行逻辑测试。
运算器中各组成部分的功能:
- 算数逻辑单元(ALU):负责处理数据,实现对数据的算术运算和逻辑运算,是运算器的重要组成部件。
- 累加寄存器(AC):简称累加器,是一个通用寄存器,为ALU提供一个工作区。通常用于存储运算结果、中间结果或操作数。运算结果是存放在累加器中的,所以运算器至少要有一个累加寄存器。
- 数据缓冲寄存器(DR):用于临时存储正在被处理的数据。当从内存或其他寄存器中读取数据时,这些数据会先存储在数据缓冲寄存器中,将不同时间段内读/写的数据隔离开,以便后续进行计算或进一步传输。
- 状态条件寄存器(PSW):状态条件寄存器存储了运算器运算过程中产生的一些状态信息,例如进位(C)、溢出(V)、零值(Z)、负数(N)等。这些状态信息反映了运算的结果特征,能够用于后续的条件判断和控制流程。
3.2、控制器
控制器用于控制着整个CPU的工作,不仅要保证程序的正常执行,而且要能够处理异常事件。控制器一般包括指令控制逻辑、时序控制逻辑、总线控制逻辑和中断控制逻辑等几个部分。
-
指令译码:控制器对从内存中读取的指令进行译码,将其解析为对应的操作码和操作数,并分发给相应的执行单元进行处理。
-
时序和时钟控制:控制器负责生成CPU内部各个部件的时序信号,并确保它们按照正确的时钟频率进行操作,同时协调各个部件之间的数据传输和操作。
-
分支预测和错误处理:控制器可以具有分支预测功能,用于预测分支指令的执行路径,以提高程序执行效率。同时,当发生错误或异常情况时,控制器也负责处理和协调异常处理流程。
-
中断和异常处理:控制器负责处理来自外部设备的中断请求以及CPU内部发生的异常情况,包括保存现场、切换上下文、执行中断服务例程等操作。
-
控制总线和数据总线:控制器管理CPU与其他部件之间的控制总线和数据总线,协调数据传输和控制命令的发送与接收。同时也负责协调各个部件的接入和访问内存。
指令控制逻辑要完成取指令、分析指令和执行指令的操作。其过程分为取指令、指令译码、按指令操作码执行、形成下一条指令地址等步骤。
- 指令寄存器(IR):CPU执行一条指令时,先把它从内存储器中取到缓冲寄存器,在送入IR暂存,指令译码器根据IR的内容生成各种微操作指令,控制其他组件工作完成所需功能。
- 程序计数器(PC):具有寄存信息和计数两种功能,又称为指令计数器。程序的执行分为顺序执行和转移执行两种情况。在程序开始执行前,将程序的起始地址传给PC(即程序第一条指令的地址);CPU自动修改PC的内容,使其保持的始终是将要执行的下一条指令的地址。对于顺序执行,修改过程至少简单的对PC加一;对于转移执行,后继指令的地址根据当前指令的地址加上一个向前或向后的位偏移量来得到,或者根据转移指令给出的直接的转移地址得到。
- 地址寄存器(AR):保存当前CPU所访问的内存单元的地址。
- 指令译码器(ID):包含操作码和地址码两部分,对指令中的操作码字段进行分析解释,发出控制信号,控制各部件工作。
时序控制逻辑要为每条指令按照时间顺序提供应有的控制信号。总线控制逻辑是为多个功能部件服务的信息通路的控制电路。中断控制逻辑用于控制各种中断请求,并根据中断优先级的高低进行排队,逐个交给CPU处理。
3.3、寄存器组
寄存器组可分为通用寄存器和专用寄存器两种类型。运算器和控制器的寄存器是专用寄存器,其作用是固定的。通用寄存器用途广泛,可由程序员指定其用途。
专用寄存器有:
-
程序计数器(PC):用于存储当前正在执行的指令所在的内存地址,也就是下一条将要执行的指令的地址。
-
指令寄存器(IR):用于暂存当前从主存读取的指令,待译码执行。
-
控制寄存器:用于存储各种控制信号和状态位,例如时钟控制、中断使能等。
-
状态条件寄存器(CCR):用于存储处理器运算过程中产生的各种状态信息,如进位、溢出、零值等。
-
栈指针寄存器(SP):用于存储当前程序执行的栈顶地址,用于支持程序的子函数调用和返回。
-
基址指针寄存器(BP):用于存储当前数据区的基地址,便于访问局部变量和参数。
-
索引寄存器(IX):用于支持寻址操作,实现对数组和结构体等结构化数据的访问。
-
数据缓冲寄存器(Data Buffer Register):用于临时缓存从内存中读取或写入的数据。
通用寄存器:用于存储临时数据和中间计算结果,是CPU内部数据处理的主要工作区,例如累加器、数据寄存器、地址寄存器等。
3.4、多核CPU
CPU所有的计算、接收/存储命令、处理数据都由核心执行。
多核CPU是指在一个物理芯片内集成了多个处理器核心的中央处理单元。每个核心独立地执行指令和处理数据,因此多核CPU可以同时处理多个任务。
CPU厂商Intel和AMD的双核技术在结构上有所不同。AMD将两个内核做在一个Die(晶圆)上,通过直连架构连接起来,集成度更高;Intel则是将放在不同核心上的两个内核封装在一起;因此将Intel的方案称为“双芯”,AMD方案称为“多核”。AMD的方案能够使得双核CPU的管脚、功耗等指标跟单核CPU保持一致,从单核升级到双核不需要更换电源、芯片组、散热系统和主板,只需要升级BIOS软件即可。
多核CPU有以下几个主要特点:
-
并行处理:多核CPU可以同时执行多个线程或进程,实现并行处理,从而提高整体的计算和处理能力。不同核心可以同时执行不同的任务,或者协同处理一个任务,提高系统的响应速度和运算效率。
-
能效比提高:相较于增加处理器的主频来提高性能,使用多核CPU可以更有效地提高计算能力,同时避免了过高的热量和能耗。
-
任务分配:操作系统可以将不同的任务分配给多个核心同时执行,充分利用了CPU的处理能力,从而提高了系统的整体性能。
-
物理封装:多核CPU在同一物理封装内集成多个处理器核心,减少了系统内部组件的复杂性和成本。
多核CPU最大的优点是可满足用户同时进行多任务处理的要求。单核多线和多核多线程都可以执行多任务,但是多核的速度更快。虽然采用了Intel超线程技术的单核可以视为“双核”,4核可以视为8核,但是视为是8核一般比不上实际是8核的CPU性能。
四、数据表示
各种数值在计算机中表示的形式称为机器数,其特点是采用二进制计数制,数的符号用0和1表示,小数点则隐含,表示不占位置。
机器数对应的实际数值称为数的真值。机器数有无符号数和带符号数之分。无符号数表示正数,在机器数中没有符号位。对于无符号数,若约定小数点的位置在机器数的最低位之后,则是纯整数;若约定小数点的位置在机器数的最高位之前,则是纯小数。对于带符号数,机器数的最高位是表示正、负的符号位 ,其余位则表示数值。为了便于运算,带符号的机器数可采用原码、反码和补码等不同的编码方法,机器数的这些编码方法称为码制。
4.1、原码、反码、补码及移码
(1)原码表示法。数值 X 的原码记为 [ X ] 原 [X]_原 [X]原?,如果机器字长为n(即采用n个二进制位表示数据),则原码的定义如下:
若 X 是纯整数,则 [ X ] 原 = { X 0 ? X ? 2 n ? 1 ? 1 2 n ? 1 + ∣ X ∣ ? ( 2 n ? 1 ? 1 ) ? X ? 0 若X是纯整数,则[X]_原= \begin{cases} X & 0\leqslant X \leqslant 2^{n-1}-1 \\ 2^{n-1}+|X| & -(2^{n-1}-1)\leqslant X \leqslant 0 \end{cases} 若X是纯整数,则[X]原?={X2n?1+∣X∣?0?X?2n?1?1?(2n?1?1)?X?0?
若 X 是纯小数,则 [ X ] 原 = { X 0 ? X < 1 2 0 + ∣ X ∣ ? 1 < X ? 0 若X是纯小数,则[X]_原= \begin{cases} X & 0\leqslant X < 1 \\ 2^0+|X| & -1 < X \leqslant 0 \end{cases} 若X是纯小数,则[X]原?={X20+∣X∣?0?X<1?1<X?0?
示例:假设机器字长 n 等于 8, 分别给出+1, -1, +127, -127, +45, -45, +0.5, -0.5的原码表示。
+1的原码=0000 0001
-1的原码=1000 0001
+127的原码=0111 1111
-127的原码=1111 1111
+45的原码=0010 1101
-45的原码=1010 1101
+0.5的原码=0*100 0000
-0.5的原码=1*100 0000
其中*表示小数点的位置。
原码是最简单的表示方法,符号位为0代表正数,符号位为1代表负数,其余位表示数值的绝对值。例如,8位原码表示中,+3的原码是00000011,-3的原码是10000011。但是,数值0的原码表示有两种形式: [ + 0 ] 原 = 00000000 , [ ? 0 ] 原 = 10000000 [+0]_原=0000 0000,[-0]_原=1000 0000 [+0]原?=00000000,[?0]原?=10000000。
(2)反码表示法。数值 X 的反码记为 [ X ] 反 [X]_反 [X]反?,如果机器字长为n(即采用n个二进制位表示数据),则反码的定义如下:
若 X 是纯整数,则 [ X ] 反 = { X 0 ? X ? 2 n ? 1 ? 1 2 n ? 1 + X ? ( 2 n ? 1 ? 1 ) ? X ? 0 若X是纯整数,则[X]_反= \begin{cases} X & 0\leqslant X \leqslant 2^{n-1}-1 \\ 2^{n-1}+X & -(2^{n-1}-1)\leqslant X \leqslant 0 \end{cases} 若X是纯整数,则[X]反?={X2n?1+X?0?X?2n?1?1?(2n?1?1)?X?0?
若 X 是纯小数,则 [ X ] 反 = { X 0 ? X < 1 2 ? 2 ? ( n ? 1 ) + X ? 1 < X ? 0 若X是纯小数,则[X]_反= \begin{cases} X & 0\leqslant X < 1 \\ 2-2^{-(n-1)}+X & -1 < X \leqslant 0 \end{cases} 若X是纯小数,则[X]反?={X2?2?(n?1)+X?0?X<1?1<X?0?
示例:假设机器字长 n 等于 8, 分别给出+1, -1, +127, -127, +45, -45, +0.5, -0.5的反码表示。
+1的反码 =0000 0001
-1的反码 =1111 1110
+127的反码 =0111 1111
-127的反码 =1000 0000
+45的反码 =0010 1101
-45的反码 =1101 0010
+0.5的反码 =0*100 0000
-0.5的反码 =1*011 1111
其中*表示小数点的位置。
反码是对原码的一种变换,正数的反码与原码相同,负数的反码是符号位不变,其余位取反。例如,+3的反码是00000011,-3的反码是11111100。但是,数值0的反码表示有两种形式: [ + 0 ] 反 = 00000000 , [ ? 0 ] 反 = 11111111 [+0]_反=0000 0000,[-0]_反=1111 1111 [+0]反?=00000000,[?0]反?=11111111。
(3)补码表示法 。数值 X 的反码记为 [ X ] 补 [X]_补 [X]补?,如果机器字长为n(即采用n个二进制位表示数据),则补码的定义如下:
若 X 是纯整数,则 [ X ] 补 = { X 0 ? X ? 2 n ? 1 ? 1 2 n + X ? 2 n ? 1 ? X ? 0 若X是纯整数,则[X]_补= \begin{cases} X & 0\leqslant X \leqslant 2^{n-1}-1 \\ 2^{n}+X & -2^{n-1}\leqslant X \leqslant 0 \end{cases} 若X是纯整数,则[X]补?={X2n+X?0?X?2n?1?1?2n?1?X?0?
若 X 是纯小数,则 [ X ] 补 = { X 0 ? X < 1 2 + X ? 1 < X ? 0 若X是纯小数,则[X]_补= \begin{cases} X & 0\leqslant X < 1 \\ 2+X & -1 < X \leqslant 0 \end{cases} 若X是纯小数,则[X]补?={X2+X?0?X<1?1<X?0?
示例:假设机器字长 n 等于 8, 分别给出+1, -1, +127, -127, +45, -45, +0.5, -0.5的补码表示。
+1的补码 =0000 0001
-1的补码 =1111 1111
+127的补码 =0111 1111
-127的补码 =1000 0001
+45的补码 =0010 1101
-45的补码 =1101 0011
+0.5的补码 =0*100 0000
-0.5的补码 =1*100 0000
其中*表示小数点的位置。
补码是对原码的另一种变换,它是计算机中最常用的表示方法。正数的补码和原码一样,负数的补码是反码加1。例如,+3的补码是00000011,-3的补码是11111101。但是,数值0的补码表示有两种形式: [ + 0 ] 补 = 00000000 , [ ? 0 ] 补 = 00000000 [+0]_补=0000 0000,[-0]_补=0000 0000 [+0]补?=00000000,[?0]补?=00000000。
(4)移码表示法。移码表示法是在数 X上增加一个偏移量来定义的,常用于表示浮点数中的阶码。如果机器字长为n,规定偏移量为 2 n ? 1 2^{n-1} 2n?1 ,则移码的定义为:若X是纯整数,则 [ X ] 移 = 2 n ? 1 + X ( ? 2 n ? 1 ? 1 ? X < 2 n ? 1 ) [X]_移=2^{n-1} +X (-2^{n-1}-1\leqslant X \lt 2^{n-1}) [X]移?=2n?1+X(?2n?1?1?X<2n?1);若X是纯小数,则 [ X ] 移 = 1 + X ( ? 1 ? X < 1 ) [X]_移=1+X(-1 \leqslant X \lt 1) [X]移?=1+X(?1?X<1)。
示例:若机器字长n等于8,分别给出+1, -1, +127, -127, +45, -45, +0, -0的移码表示。
+1的移码 =1000 0001
-1的移码 =0111 1111
+127的移码 =1111 1111
-127的补码 =0000 0001
+45的移码 =1010 1101
-45的移码 =0101 0011
+0的移码 =1000 0000
-0的移码 =1000 0000
其中*表示小数点的位置。
移码是另一种用来表示带符号数的方法,和补码表示方法相似,不同之处在于符号位的表示。在移码表示中,正数的符号位为0,负数的符号位为1且其余位取反。例如,+3的移码是00000011,-3的移码是11111100。
实际上,在偏移 2 n ? 1 2^{n-1} 2n?1的情况下,只要将补码的符号位取反便可获得相应的移码表示。
这些表示方法在计算机中用于存储和运算带符号数,每种表示方法都有其特定的优点和缺点。补码是在计算机中使用最广泛的表示方法 ,因为它对于加法和减法运算是封闭的,也就是说,对于任何两个补码进行加法运算,得到的结果仍然是一个补码。
4.2、定点数和浮点数
定点数和浮点数是用来表示和处理实数的两种不同的表示方法。
(1)定点数表示法是一种用于在计算机中表示和处理整数和小数部分固定位数的数值的方法。在定点数表示法中,数值被表示为一个定点小数,小数点的位置是固定的,通常固定在某个位置的左边或者右边。因为小数点的位置是固定的,所以定点数可以比较简单地进行加减运算,但是对于大范围的数值和精确度要求较高的计算,定点数表示法就不够灵活。在运算中很容易因为结果超出范围而溢出。
简单来说,定点数就是小数点的位置固定不动的数。通常有两种约定方式:定点整数(纯整数,小数点在最低有效数值位之后)和定点小数(纯小数,小数点在最高有效数值位之前)。
机器字长为n时各种码制表示的带符号数的范围:

(2)浮点数表示法是一种用于在计算机中表示和处理实数的方法。浮点数表示法使用科学计数法的表示方式,包含一个底数和一个指数部分。由于指数部分可以对小数点的位置进行动态调整,所以浮点数表示法能够表示很大或者很小的数值,并且能够保持相对较高的精度。因此,浮点数表示法一般用于科学计算、工程计算以及需要高精度的计算中。
简单的说,浮点数是小数点位置不固定的数,能表示更大范围的数。
在十进制中,一个数可以写成多种表示形式。例如,83.125 可写成 1 0 3 × 0.083125 10^3× 0.083125 103×0.083125 或 1 0 4 × 0.0083125 10^4×0.0083125 104×0.0083125等。同样,一个二进制数也可以写成多种表示形式。例如,二进制数1011.10101可以写成 2 4 × 0.101110101 、 2 5 × 0.0101110101 或 2 6 × 0.00101110101 2^4 \times 0.101110101、2^5 \times 0.0101110101或2^6 \times 0.00101110101 24×0.101110101、25×0.0101110101或26×0.00101110101等。因此,一个二进制数 N可以表示为更一般的形式 N = 2 E × F N=2^E \times F N=2E×F,其中 E称为阶码,F称为尾数。用阶码和尾数表示的数称为浮点数,这种表示数的方法称为浮点表示法 。在浮点表示法中,阶码为带符号的纯整数,尾数为带符号的纯小数。浮点数的表示格式:阶符、阶码、数符、位数。
一个数的浮点表示不是唯一的。当小数点的位置改变时,阶码也随着相应改变,因此可以用多个浮点形式表示同一个数。浮点数所能表示的数值范围主要由阶码决定,所表示数值的精度则由尾数决定。为了充分利用尾数来表示更多的有效数字,通常采用规格化浮点数,即将尾数的绝对值限定在区间[0.5,1]。
当尾数用补码表示时:
- 若尾数 M>0,则其规格化的尾数形式为 M=0.1×××…×,其中,×可为 0, 也可为 1,即将尾数限定在区间[0.5, 1]。
- 若尾数 M<0,则其规格化的尾数形式为 M=1.0×××…×,其中,×可为 0, 也可为 1,即将尾数M的范围限定在区间[-1,-0.5]。
如果浮点数的阶码(包括 1 位阶符)用 R 位的移码表示,尾数(包括 1 位数符)用 M 位的补码表示,则这种浮点数所能表示的数值范围为:
最大的正数为
+
(
1
?
2
?
M
+
1
)
×
2
2
R
?
1
?
1
+(1-2^{-M+1}) \times 2^{2^{R-1}-1}
+(1?2?M+1)×22R?1?1,最小的负数为
?
1
×
2
2
R
?
1
?
1
-1\times 2^{2^{R-1}-1}
?1×22R?1?1。
(3)工业标准IEEE754。由IEEE制定的有关浮点数的工业标准,形式为:
(
?
1
)
S
2
E
(
b
0
b
1
b
2
.
.
.
b
P
?
1
)
(-1)^S2^E(b_0b_1b_2...b_{P-1})
(?1)S2E(b0?b1?b2?...bP?1?)
其中,
(
?
1
)
S
(-1)^S
(?1)S是数符(表示数的正负),E为指数(阶码)并用移码表示,
(
b
0
b
1
b
2
.
.
.
b
P
?
1
)
(b_0b_1b_2...b_{P-1})
(b0?b1?b2?...bP?1?)是尾数,长度为P并用原码表示。
计算机中主要使用3种形式的IEEE 754浮点数:
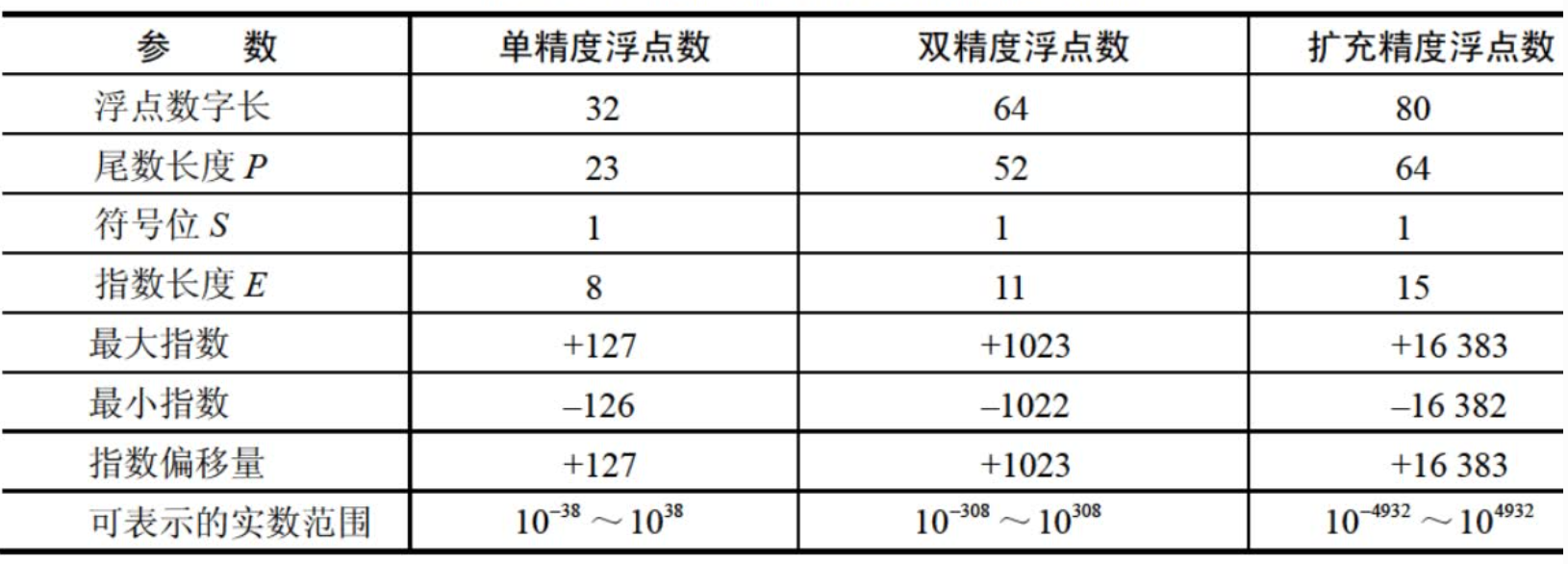
根据IEEE754标准,被编码的值分为3种不同的情况:规格化的值、非规格化的值和特殊值,规格化的值为最普遍的情形。
-
规格化的值:当阶码部分的二进制值不全为 0 也不全为 1 时,所表示的是规格化的值。例如,在单精度浮点格式下,阶码为10110011时,偏移量为+127 (01111111) ,则其表示的真值为10110011-01111111=00110100,转换为十进制后为52。对于尾数部分,由于约定小数点左边隐含有一位,通常这位数就是1,因此单精度浮点数尾数的有效位数为24位,即尾数为1.××…×。也就是说,不溢出的情况下尾数M的值在 1 ? M < 2 1 \leqslant M \lt 2 1?M<2之中,这是一种获得一个额外精度位的表示技巧。例如,单精度浮点数格式下, b 0 b 1 . . . b 22 b_0b_1...b_{22} b0?b1?...b22?=0100 1001 1000 1000 1001 011时,其对应的尾数真值为 1 + 2 ? 2 + 2 ? 5 + 2 ? 8 + 2 ? 9 + 2 ? 13 + 2 ? 17 + 2 ? 20 + 2 ? 22 + 2 ? 23 1+2^{-2}+2^{-5}+2^{-8}+2^{-9}+2^{-13}+2^{-17}+2^{-20}+2^{-22}+2^{-23} 1+2?2+2?5+2?8+2?9+2?13+2?17+2?20+2?22+2?23 即 尾 数 的 真 值 为1.28724038600921630859375 (在程序中以十进制方式输出时,由于精度的原因不能完全给出此值)。
-
非规格化的值。当阶码部分的二进制值全为 0 时,所表示的数是非规格化的。在这种情况下,指数的真值为 1-偏移量(对于单精度浮点数为-126,对于双精度浮点数为-1022),尾数的值就是二进制形式对应的小数,不包含隐含的 1。非规格化数有两个用途:一是用来表示数值0,二是表示那些非常接近于0 的数。因为在规格化表示方式下,必须使尾数大于等于 1,因此不能表示出 0。实际上,+0.0 的浮点表示是符号、阶码和尾数的二进制表示都全为0。需要注意的是,符号位为1而阶码和尾数部分全为0 时表示-0.0。也就是说,+0.0和-0.0 在浮点表示时有所不同。
-
特殊值。当阶码部分的二进制值全为1时,表示特殊的值。当尾数部分全部为0时表示无穷大,当符号位为0 时表示正无穷大,当符号位为1 时表示负无穷大。当浮点运算溢出时,用无穷来表示。当尾数部分不全为0时,称为“NaN”,即“不是一个数”。当运算结果不是实数或者无穷,就表示为 NaN。
参考文献:
(4)浮点数的运算。运算过程要经过对阶、求尾数和(差)、结果规格化并判溢出、舍入处理和溢出判别等步骤。
- 对阶。使两个数的阶码相同。把阶码小的数的尾数右移|i-j|位,使其阶码加上|i-j|。
- 求尾数和(差)。
- 结果规格化并判溢出。若运算结果所得的尾数不是规格化的数,则需要进行规格化处理。当尾数溢出时,需要调整阶码。
- 舍入处理。在对结果右规时,尾数的最低位将因移出而丢掉。另外,在对阶过程中也会将尾数右移使最低位丢掉。这就需要进行舍入处理,以求得最小的运算误差。
- 溢出判别。以阶码为准,若阶码溢出,则运算结果溢出;若阶码下溢(小于最小值),则结果为0;否则结果正确,无溢出。
浮点数相乘,其积的阶码等于两乘数的阶码相加,积的尾数等于两乘数的尾数相乘。
浮点数相除,其商的阶码等于被除数的阶码减去除数的阶码,商的尾数等于被除数的尾数除以除数的尾数。
乘除运算的结果都需要进行规格化处理并判断阶码是否溢出。
五、计算机校验码
校验码是一种用于检测传输或存储数据中出现错误的技术手段。它通过对数据进行特定的计算和附加信息的方式,能够在数据传输或存储过程中,检测出是否存在误码(数据被破坏)或漏码(数据丢失)。校验码通常会附加在被保护数据的末尾,以便在接收端对接收到的数据进行校验。
其基本思想是把数据可能出现的编码分为两类:合法编码和错误编码。合法编码用于传送数据,错误编码是不允许在数据中出现的编码。合理地设计错误编码以及编码规则,使得数据在传送中出现某种错误时会变成错误编码,这样就可以检测出接收到的数据是否有错。
码距是指一个编码系统中任意两个合法编码之间至少有多少个二进制位不同。例如,4位8421码的码距为1,在传输过程中,该代码的一位或多位发生错误,都将变成另外一个合法的编码,因此这种代码无检错能力。
校验码的作用主要有以下几个方面:
-
错误检测:校验码能够检测在数据传输或存储过程中发生的错误,例如数据位被破坏或丢失的情况。通过对接收到的数据进行计算,接收方可以进行校验,以确定数据是否完整和准确。
-
数据完整性验证:校验码可以用于验证接收到的数据是否完整,以防止数据在传输或存储过程中部分丢失或被篡改。
-
数据安全性:在一些情况下,校验码可以用于检测数据是否受到了恶意篡改,从而确保数据的安全性。
常见的校验码包括奇偶校验、循环冗余校验(CRC)、校验和等。
5.1、奇偶校验
奇偶校验(Parity Codes)是一种简单有效的校验方法,通常应用于串行数据传输中。这种方法通过在编码中增加一位校验位来使编码中1的个数为奇数(奇校验)或者为偶数(偶校验),从而使码距变为2。对于奇校验,它可以检测代码中奇数位出错的编码,但不能发现偶数位出错的情况,即当合法编码中的奇数位发生了错误时,即编码中的 1变成 0 或 0 变成 1,则该编码中 1的个数的奇偶性就发生了变化,从而可以发现错误。
常用的奇偶校验码有3种:水平奇偶校验码、垂直奇偶校验码和水平垂直校验码。
虽然奇偶校验是一种简单的数据校验技术,但它相对于更复杂的校验方法来说,性能较弱,因为它只能检测到数据中包含的1的个数为奇数或偶数的错误,无法检测到多个位的错误。
5.2、海明码
海明码(Hamming code)由贝尔实验室的理查德·瓦斯利·海明提出的一种错误检测与纠正编码方式。它是一种利用奇偶性来检错和纠错的校验方法,通过在数据中加入冗余位来对数据进行编码,以便在传输或存储过程中检测并纠正错误。
海明码的基本原理是使用一个特定的矩阵进行数据编码,在矩阵中每一列对应一个数据位,而每一行对应一个校验位。通过特定的运算,每个校验位都被计算为覆盖一定范围内的数据位,以便对数据进行校验和纠正。
海明码的构成方法是在数据位之间的特定位置上插入 k 个校验位,通过扩大码距来实现检错和纠错。设数据位是 n 位,校验位是 k位,则 n 和k必须满足关系: 2 k ? 1 ? n + k 2^k-1\geqslant n+k 2k?1?n+k。
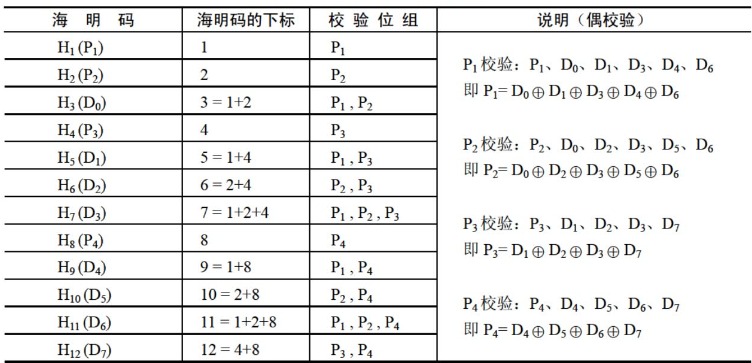
海明码的编码规则:设k个校验位为 P k P k ? 1 , … , P 1 P_kP_{k-1},…,P_1 Pk?Pk?1?,…,P1?,n个数据位为 D n ? 1 , D n ? 2 , . . . , D 1 , D 0 D_{n-1},D_{n-2},...,D_1,D_0 Dn?1?,Dn?2?,...,D1?,D0?,对应的海明码为 H n + k H n + k ? 1 , … , H 1 H_{n+k}H_{n+k-1},…,H_1 Hn+k?Hn+k?1?,…,H1?,那么:
- P i P_i Pi?在海明码的第 2 i ? 1 2^{i-1} 2i?1位置,即 H j = P i H_j=P_i Hj?=Pi?,且 j = 2 i ? 1 j=2^{i-1} j=2i?1,数据位则依序从低到高占据海明码中剩下的位置。
- 海明码中的任何一位都是由若干个校验位来校验的。其对应关系为:被校验的海明位的下标等于所有参与校验该位的校验位的下标之和,而校验位由自身校验。
对于 8 位的数据位,进行海明校验需要 4 个校验位 ( 2 3 ? 1 = 7 , 2 4 ? 1 = 15 > ( 8 + 4 ) ) (2^3-1=7,2^4-1=15>(8+4)) (23?1=7,24?1=15>(8+4))。令数据位为 D 7 , D 6 , D 5 , D 4 , D 3 , D 2 , D 1 , D 0 D_7,D_6,D_5,D_4,D_3,D_2,D_1,D_0 D7?,D6?,D5?,D4?,D3?,D2?,D1?,D0?,校验位为 P 4 , P 3 , P 2 , P 1 P_4,P_3,P_2,P_1 P4?,P3?,P2?,P1?,形成的海明码为 H 12 , H 11 , . . . , H 3 , H 2 , H 1 H_{12}, H_{11},...,H_3,H_2,H_1 H12?,H11?,...,H3?,H2?,H1?,则编码过程如下:
-
确定 D 与P 在海明码中的位置。
H 12 ? H 11 ? H 10 ? H 9 ? H 8 ? H 7 ? H 6 ? H 5 ? H 4 ? H 3 ? H 2 ? H 1 H_{12} \space H_{11} \space H_{10} \space H_9 \space H_8 \space H_7 \space H_6 \space H_5 \space H_4 \space H_3 \space H_2 \space H_1 H12??H11??H10??H9??H8??H7??H6??H5??H4??H3??H2??H1?
D 7 ??? D 6 ??? D 5 ?? D 4 ? P 4 ?? D 3 ? D 2 ? D 1 ? P 3 ?? D 0 ? P 2 ? P 1 D_7 \space \space \space D_6 \space \space \space D_5 \space \space D_4 \space P_4 \space \space D_3 \space D_2 \space D_1 \space P_3 \space \space D_0 \space P_2 \space P_1 D7????D6????D5???D4??P4???D3??D2??D1??P3???D0??P2??P1? -
确定校验关系。若采用奇校验,则将各校验位的偶校验值取反即可。
-
检测错误。对使用海明编码的数据进行差错检测很简单,只需做以下计算: G 1 = P 1 + D 0 + D 1 + D 2 + D 3 + D 4 + D 6 ; G 2 = P 2 + D 0 + D 2 + D 3 + D 5 + D 6 ; G 3 = P 3 + D 1 + D 2 + D 3 + D 7 ; G 4 = P 4 + D 4 + D 5 + D 6 + D 7 G_1=P_1+D_0+D_1+D_2+D_3+D_4+D_6;G_2=P_2+D_0+D_2+D_3+D_5+D_6;G_3=P3+D_1+D_2+D_3+D_7;G_4=P_4+D_4+D_5+D_6+D_7 G1?=P1?+D0?+D1?+D2?+D3?+D4?+D6?;G2?=P2?+D0?+D2?+D3?+D5?+D6?;G3?=P3+D1?+D2?+D3?+D7?;G4?=P4?+D4?+D5?+D6?+D7?。若采用偶校验,则 G 4 G 3 G 2 G 1 G_4G_3G_2G_1 G4?G3?G2?G1?全为0时表示接收到的数据无错误(奇校验应全为1) 。当 G 4 G 3 G 2 G 1 G_4G_3G_2G_1 G4?G3?G2?G1?不全为0时说明发生了差错,而且 G 4 G 3 G 2 G 1 G_4G_3G_2G_1 G4?G3?G2?G1?的十进制值指出了发生错误的位置,例如 G 4 G 3 G 2 G 1 G_4G_3G_2G_1 G4?G3?G2?G1?=1010,说明 H 10 ( D 5 ) H_{10}(D_5) H10?(D5?)出错了,将其取反即可纠正错误。
海明码可以检测和纠正多位错误,并且在相同冗余位数的情况下,它的纠错能力比奇偶校验等简单的错误检测方案更高。
海明码通常被应用于需要高度可靠数据传输和存储的场景,例如计算机存储系统、数字通信系统和数据传输链路等。它在数据通信中起着至关重要的作用,能够确保数据的可靠性和完整性。
5.3、循环冗余校验(CRC)
循环冗余校验(CRC)是一种广泛应用于数字通信和磁介质存储系统中的错误检测技术,它利用生成多项式为k个数据位产生r个校验位来进行编码,其编码长度为k+r。CRC通常用于检测数据传输中的位错误,有时也可以用于包括纠正一定数量的错误在内的数据完整性检查。CRC 的代码格式为:

由此可知,循环冗余校验码是由两部分组成的,左边为信息码(数据),右边为校验码。若信息码占k位,则校验码就占n-k位。其中, n为CRC码的字长,所以又称为(n, k)码。校验码是由信息码产生的,校验码位数越多,该代码的校验能力就越强。在求CRC编码时,采用的是模2运算。模2加减运算的规则是按位运算,不发生借位和进位。
CRC的基本原理是将数据按照特定的生成多项式进行编码,生成多项式通常是预先确定的多项式,例如CRC-32中使用的是32位的多项式。发送端在发送数据前,会对整个数据包进行CRC编码,并将生成的校验码附加到数据包的末尾。接收端收到数据后,也会使用相同的生成多项式对数据包进行CRC编码,然后与接收到的校验码比对,以确定数据是否存在错误。
CRC能够检测多种常见的错误,包括单比特错误、双比特错误、交换一对比特错误等。并且,CRC还有能力在一定程度上纠正错误,尤其是在一些实时通信系统中。
CRC广泛应用于网络通信、存储系统、以太网、Wi-Fi、蓝牙等协议规范中。它是一种高效的错误检测技术,能够有效地提高数据传输的可靠性和完整性。
循环冗余校验码(Cyclic Redundancy Check, CRC)广泛应用于数据通信领域和磁介质存储系统中。它利用生成多项式为k个数据位产生r个校验位来进行编码,其编码长度为k+r。CRC 的代码格式为:
六、重点知识掌握情况
通过练习题的方式,摸清自己对上述内容的掌握情况。答案可见总结或评论区。
填空题:
(1)计算机系统的基本硬件由:_____、______、______、______和______五个部分组成 。
(2)CPU主要由 ______、______、______和______等部件组成 ;负责______________________________。
(3)运算器是计算机中的一个核心部件,它由______、______、______和______等组成。负责___________________________________。
(4)
(5)常见的校验码包括______、______、______等。
问答题:
(6)程序计数器(PC)的作用是什么?
______________________________________________。
(7)写出十进制280的原码、反码、补码,假设机器长度为16。
______________________________________________。
(8)根据IEEE754标准,写出62.56的浮点表示。
______________________________________________。
总结
深入探讨了计算机系统基础知识,从硬件到校验码,全面解析了内存、CPU、输入输出设备等硬件组件的重要性和功能。同时,对中央处理器(CPU)的各个部分进行了详细分析,包括运算器、控制器、寄存器组以及多核CPU技术。此外,还深入探讨了数据表示的复杂性,包括原码、补码、浮点数等内容。最后,对计算机校验码的种类进行了介绍,包括奇偶校验、海明码和CRC。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- java设计模式学习之【享元模式】
- skimage图像处理(全)
- CentOS安装docker
- test-04-test case generate 测试用例生成 tcases 快速开始
- 绿洲便利店商品售卖系统(源码+开题)
- GPTs 官方榜单 Top10,第一个独属于中国传统文化的胜利
- VMware虚拟机安装CentOS 7操作系统的步骤及方法
- 【产品设计】信息建设三驾马车:MES系统拆解
- C++客户关系管理系统架构——设计模式应用场景代码分析
- 案例1—综合项目组网(1)