HashMap 是怎么解决哈希冲突的?
发布时间:2023年12月29日
常用数据结构基本上是面试必问的问题,比如 HashMap、LinkList、ConcurrentHashMap 等。
关于 HashMap,有个学员私信了我一个面试题说: “HashMap 是怎么解决哈希冲突的?”
关于这个问题,我们来看看高手对于这个问题的回答。
一、问题解析
这个问题我从三个方面来回答。
1. 要了解 Hash 冲突,那首先我们要先了解 Hash 算法和 Hash 表。(如图)
a. Hash 算法,就是把任意长度的输入,通过散列算法,变成固定长度的输出, 这个输出结果是散列值。
b. Hash 表又叫做“散列表”,它是通过 key 直接访问在内存存储位置的数据结构,在具体实现上,我们通过 hash 函数把 key 映射到表中的某个位置,来获取这个位置的数据,从而加快查找速度。

c. 所谓 hash 冲突,是由于哈希算法被计算的数据是无限的,而计算后的结果范围有限,所以总会存在不同的数据经过计算后得到的值相同,这就是哈希冲突。
d. 通常解决 hash 冲突的方法有 4 种。
i.
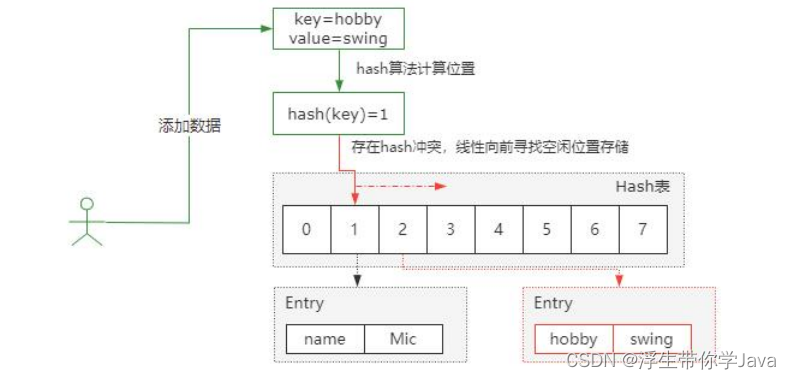
开放定址法,也称为线性探测法,就是从发生冲突的那个位置开始,按照一定的次序从 hash 表中找到一个空闲的位置,然后把发生冲突的元素存入到这个空闲位置中。ThreadLocal 就用到了线性探测法来解决 hash 冲突的。向这样一种情况(如图),在 hash 表索引 1 的位置存了一个key=name,当再次添加 key=hobby 时,hash 计算得到的索引也是 1,这个就是 hash 冲突。而开放定址法,就是按顺序向前找到一个空闲的位置来存储冲突的 key。
ii. 链式寻址法,这是一种非常常见的方法,简单理解就是把存在 hash 冲突的 key,以单向链表的方式来存储,比如 HashMap 就是采用链式寻址法来实现的。向这样一种情况(如图),存在冲突的 key 直接以单向链表的方式进行存储。

iii. 再 hash 法,就是当通过某个 hash 函数计算的 key 存在冲突时,再用另外一个 hash 函数对这个 key 做 hash,一直运算直到不再产生冲突。这种方式会增加计算时间,性能影响较大。
iv. 建立公共溢出区, 就是把 hash 表分为基本表和溢出表两个部分,凡事存在冲突的元素,一律放入到溢出表中。
e. HashMap 在 JDK1.8 版本中,通过链式寻址法+红黑树的方式来解决 hash 冲突问题,其中红黑树是为了优化 Hash 表链表过长导致时间复杂度增加的问题。当链表长度大于 8 并且 hash 表的容量大于 64 的时候,再向链表中添加元素就会触发转化。
以上就是我对这个问题的理解!
二、问题总结
这道面试题主要考察 Java 基础,面向的范围是工作 1 到 5 年甚至 5 年以上。因为集合类的对象在项目中使用频率较高,如果对集合理解不够深刻,容易在项目中制造隐藏的 BUG。所以,再强调一下,面试的时候,基础是很重要的考核项!!
本期高手面试系列的文章就到这里结束了,喜欢的朋友记得点赞收藏。
我是 浮生,一个工作了 14 年的 Java 程序员,咱们下期再见。
三、粉丝福利
最近很多同学问我有没有java学习资料,我根据我从小白到架构师多年的学习经验整理出来了一份?50W字面试解析文档、简历模板、学习路线图、java必看学习书籍?、 需要的小伙伴 可以关注我
公众号:“?灰灰聊架构?”, 回复暗号:“?321?”即可获取

文章来源:https://blog.csdn.net/sinat_53467514/article/details/135292097
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 运放负反馈
- 2.4 DEVICE GLOBAL MEMORY AND DATA TRANSFER
- [Kafka 常见面试题]如何保证消息的不重复不丢失
- bash脚本等待MQTT服务启动后再启动程序
- 三、C语言中的分支与循环—for循环 (6)
- 拿到公司给的地址如何使用git拉取呢?
- 【Python常见数据结构操作-持续更新】
- opencv入门到精通——图像阈值
- dubbo与seata集成
- Spring Boot CLI 中文文档