基于LLM+RAG的问答

每日推荐一篇专注于解决实际问题的外文,精准翻译并深入解读其要点,助力读者培养实际问题解决和代码动手的能力。
欢迎关注公众号

原文标题:LLM+RAG based Question Answering
原文地址:https://teemukanstren.com/2023/12/25/llmrag-based-question-answering/

最近,检索增强生成(RAG)似乎相当流行。在大型语言模型(LLM)的浪潮中,它是一种流行的技术,可以让 LLM 在特定任务(如内部文档的问题解答)中表现得更好。前段时间,我参加了 Kaggle 的一个比赛,让我尝试了一下,学习效果比自己随机实验要好一些。以下是我在撰写本文时从那次实验和下面的实验中学到的一些东西。
RAG 概览
RAG 有两个主要部分:检索和生成。在第一部分,检索用于获取与感兴趣的查询相关的文档(块)。在第二部分中,生成将这些获取的文档块作为新增输入(称为上下文),用于模型生成答案。这种添加的上下文旨在为生成器提供更多的最新信息,希望能比基础训练数据更好地作为生成答案的依据。
构建 RAG 输入或文本分块
LLM 有其可处理的最大上下文或序列窗口长度,为 RAG 生成的输入上下文必须足够短,以适应该序列窗口。我们希望将尽可能多的相关信息纳入该上下文,因此从潜在输入文档中获取最佳文本 "块 "非常重要。这些文本块应该是与生成 RAG 系统所提问题的正确答案最相关的文本块。
第一步,输入文本通常会被分割成小块。RAG 的一个基本预处理步骤是使用特定的嵌入模型将这些分块转换为嵌入。嵌入模型的典型序列窗口为 512 个标记,这也是块大小的实用目标。将文档分块并编码成嵌入向量后,就可以使用向量进行相似性搜索,从而建立生成答案的上下文。
我发现 Langchain 为输入加载和分块提供了有用的工具。例如,使用 Langchain 对文档进行分块(在本例中,使用 Flan-T5-Large 模型的标记符)就非常简单:
from transformers import AutoTokenizer
from langchain.text_splitter import RecursiveCharacterTextSplitter
#This is the Flan-T5-Large model I used for the Kaggle competition
llm = "/mystuff/llm/flan-t5-large/flan-t5-large"
tokenizer = AutoTokenizer.from_pretrained(llm, local_files_only=True)
text_splitter = RecursiveCharacterTextSplitter
?????????? .from_huggingface_tokenizer(tokenizer, chunk_size=12,
???????????????? ????? chunk_overlap=2, ???????????????????????
separators=["\n\n", "\n", ". "])
section_text="Hello. This is some text to split. With a few "\
"uncharacteristic words to chunk, expecting 2 chunks."
texts = text_splitter.split_text(section_text)
print(texts)
这样就产生了以下两块内容
['Hello. This is some text to split','. With a few uncharacteristic words to chunk, expecting 2 chunks.']
在上述代码中,chunk_size=12 会告诉 LangChain 每个语块最多包含 12 个token。根据文本结构的不同,这不一定能做到 100% 精确。不过,根据我的经验,效果一般都不错。需要注意的是token与单词之间的区别。下面是对上述 section_text 进行标记化的示例
section_text="Hello. This is some text to split. With a few uncharacteristic words to chunk, expecting 2 chunks."
encoded_text = tokenizer(section_text)
tokens = tokenizer.convert_ids_to_tokens(encoded_text['input_ids'])
print(tokens)
结果输出标记:
['▁Hello', '.', '▁This', '▁is', '▁some', '▁text', '▁to', '▁split', '.', '▁With', '▁', 'a', '▁few', '▁un', 'character', 'istic', '▁words', '▁to', '▁chunk', ',', '▁expecting', '▁2', '▁chunk', 's', '.', '</s>']
由于 section_text 中的大多数单词都是文本中的常见单词,因此它们本身就构成了一个token。但是,对于特殊形式的单词或领域单词,情况可能会复杂一些。例如,“uncharacteristic “一词在这里就变成了三个标记[” un”, " character", " istic"]。这是因为模型tokenizer知道这三个部分子词,但不知道整个词(“uncharacteristic”)。每个模型都有自己的tokenizer,以匹配输入和模型训练中的这些规则。
在分块时,上述代码中使用的 Langchain 中的 RecursiveCharacterTextSplitter 会计算这些token,并寻找给定的分隔符,按照要求将文本分割成块。试验不同的块大小可能会有帮助。在 Kaggle 实验中,我从嵌入模型的最大 512 个token开始。然后又尝试了文本块大小为 256、128 和 64 个token。
RAG 查询示例
我提到的 Kaggle 竞赛是关于基于维基百科数据的多选题回答。任务是从每道题的多个选项中选出正确答案。显而易见的方法是使用 RAG 从维基百科转储中找到所需的信息,并用它生成正确答案。下面是竞赛数据中的第一个问题及其答案选项,以作说明:

多选题是使用 RAG 的一个有趣话题。但我认为,最常见的 RAG 用例是根据源文件回答问题。这有点像聊天机器人,但通常是针对特定领域或(公司)内部文档进行问题解答。我将在本文中使用这种基本的问题解答用例来演示 RAG。
作为本文的 RAG 问题示例,我需要一些 LLM 无法直接根据其训练数据知道答案的问题。我使用了维基百科数据,因为它很可能是 LLM 训练数据的一部分,所以我需要一个与模型训练后的内容相关的问题。我在本文中使用的模型是 Zephyr 7B beta,训练时间为 2023 年初。最后,我决定询问有关谷歌巴德人工智能聊天机器人的问题。在 Zephyr 训练日期之后的一年里,它有了很多发展。我对巴德也有一定的了解,可以评估 LLM 的回答。因此,我用 "what is google bard?"作为本文的例题。
嵌入向量
RAG 检索的第一阶段以嵌入向量为基础,嵌入向量实际上就是多维空间中的点。它们看起来是这样的(这里只有前 10 个值):
q_embeddings[:10]
# array([-0.45518905, -0.6450379, 0.3097812, -0.4861114 , -0.08480848,-0.1664767 , 0.1875889, 0.3513346, -0.04495572, 0.12551129],
这些嵌入向量可用来比较单词/句子及其相互关系。这些向量可以使用嵌入模型建立。在 MTEB 排行榜上可以找到一组不错的模型,每个模型都有不同的统计信息。使用这些模型中的一个非常简单:
from sentence_transformers import SentenceTransformer, util
embedding_model_path = "/mystuff/llm/bge-small-en"
embedding_model = SentenceTransformer(embedding_model_path, device='cuda')
HuggingFace 上的模型页面通常会显示示例代码。上述代码从本地磁盘加载了 "bge-small-en "模型。使用该模型创建嵌入模型只需:
question = "what is google bard?"
q_embeddings = embedding_model.encode(question)
在这种情况下,嵌入模型被用来将给定的问题编码成一个嵌入向量。该向量与上例相同:
q_embeddings.shape
# (, 384)
q_embeddings[:10]
# array([-0.45518905, -0.6450379, 0.3097812, -0.4861114 , -0.08480848, -0.1664767 , 0.1875889, 0.3513346, -0.04495572, 0.12551129],dtype=float32)
形状(, 384)告诉我 q_embeddings 是一个长度为 384 个浮点数的单一向量(而不是同时嵌入多个文本的列表)。上面的切片显示了这 384 个值中的前 10 个值。有些模型使用较长的向量来获得更精确的关系,而有些模型(如本模型)则使用较短的向量(此处为 384)。同样,MTEB 排行榜上也有很好的例子。较小的向量需要的空间和计算量较少,较大的向量在表示块之间的关系方面有所改进,有时还能表示序列长度。
对于我的 RAG 相似性搜索,我首先需要问题的嵌入。这就是上面的 q_embeddings。这需要与所有搜索文章(或其分块)的嵌入向量进行比较。在这种情况下,就是维基百科的所有分块文章。为所有这些文章建立嵌入向量:
article_embeddings = embedding_model.encode(article_chunks)
这里的 article_chunks 是英文维基百科转储库中所有文章的所有分块的列表。这样就可以对它们进行批量编码。
矢量数据库
在大型文档集/文档块上实现相似性搜索在基本层面上并不复杂。常见的方法是计算查询和文档向量之间的余弦相似度,并据此排序。不过,在大规模情况下,这种方法的管理有时会变得有些复杂。矢量数据库是一种工具,可以使这种管理和搜索变得更容易/更有效。
例如,Weaviate 是一个矢量数据库,曾用于 StackOverflow 基于人工智能的搜索。在最新版本中,它还能以嵌入式模式使用,即使在 Kaggle 笔记本中也能使用。一些 Deeplearning.AI LLM 短期课程中也使用了它,因此至少看起来有点受欢迎。当然,还有很多其他的软件,进行比较是有好处的,因为这个领域的发展也很快。
在我的试验中,我使用 Facebook/Meta Research 的 FAISS 作为向量数据库。FAISS 更像是一个库,而不是客户端-服务器数据库,因此在 Kaggle 笔记本中使用非常简单。而且它运行得非常好。
数据分块和嵌入
所有文章的分块和嵌入工作全部完成后,我建立了一个包含所有相关信息的 Pandas DataFrame。下面是我使用的维基百科转储的前 5 个分块的示例,文档标题为 “Anarchism”:

该表(Pandas DataFrame)中的每一行都包含分块处理后的单个分块的数据。它有 5 列:
-
chunk_id:允许我稍后将大块嵌入映射到大块文本。
-
doc_id:允许将数据块映射回其文档。
-
doc_title:用于试用在每个数据块中添加文档标题等方法。
-
chunk_title:文章小节的标题,与 doc_title 用途相同。
-
chunk:实际的文本块
以下是前五个Anarchism文本块的嵌入,顺序与上述 DataFrame 相同:
[[ 0.042624 -0.131264 -0.266858 ... -0.329627 0.178211 0.248001]
[-0.120318 -0.110153 -0.059611 ... -0.297150 -0.043165 0.558150]
[ 0.116761 -0.066759 -0.498548 ... -0.330301 0.019448 0.326484]
[-0.517585 0.183634 0.186501 ... 0.134235 -0.033262 0.498731]
[-0.245819 -0.189427 0.159848 ... -0.077107 -0.111901 0.483461]]
这里只显示了每一行的部分内容,但可以说明问题。
搜索相似的查询嵌入 vs 分块嵌入
早些时候,我对查询 "what is google bard?"的查询向量,然后对所有文章块进行了编码。有了这两组嵌入,RAG 搜索的第一部分就很简单了:找到与查询 "语义 "最接近的文档。实际上,只需计算查询嵌入向量和所有文章块向量之间的余弦相似度,然后根据相似度得分排序即可。
以下是与 q_embeddings 在 "语义 "上最接近的前 10 个块:
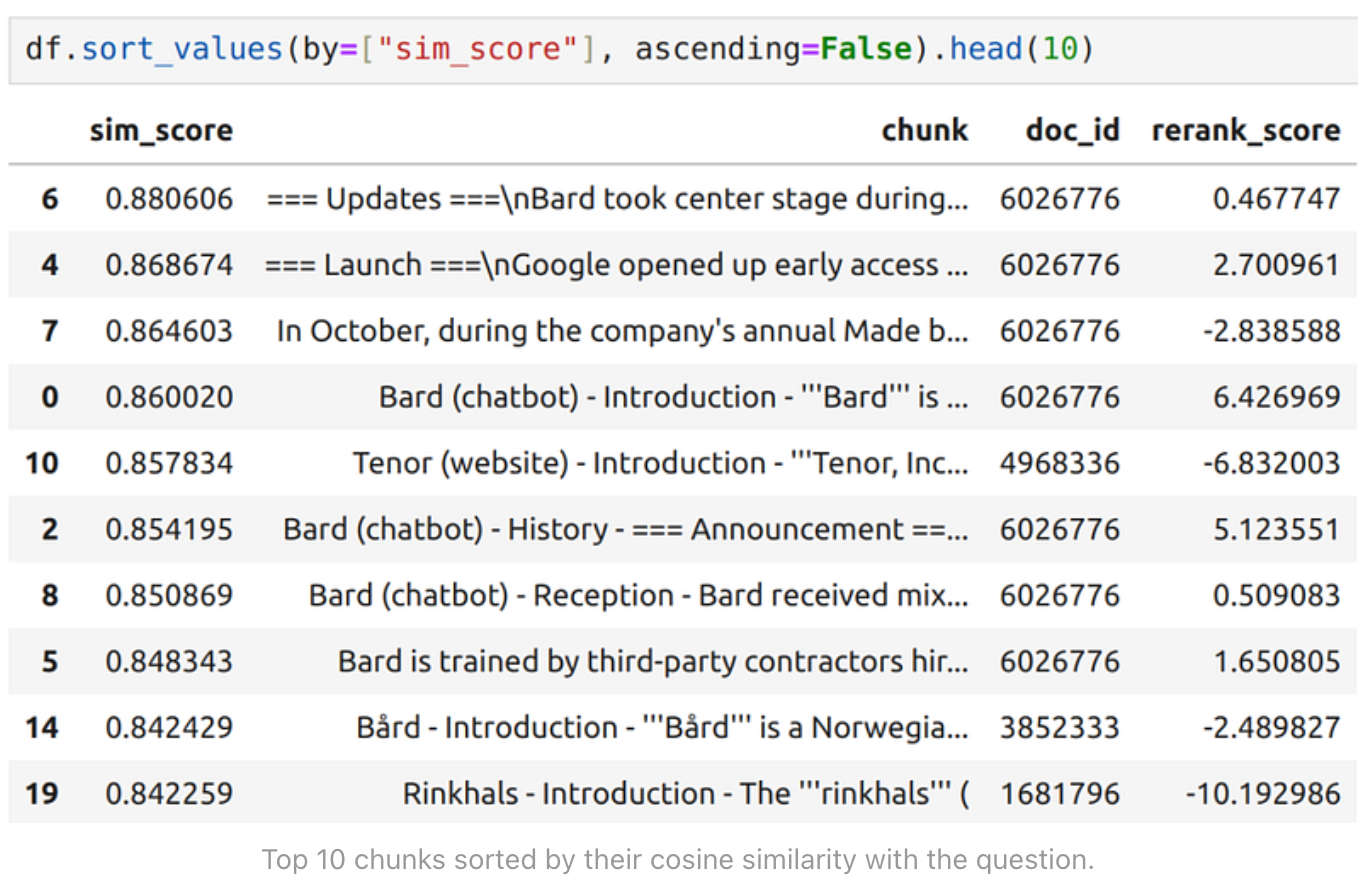
该表(DataFrame)中的每一行代表一个数据块。这里的 sim_score 是计算得出的余弦相似度得分,行按余弦相似度从高到低排序。该表显示了 sim_score 最高的前 10 行。
重排名
基于纯嵌入的相似性搜索在计算方面非常快速且成本低。但是,它并不像其他一些方法那样精确。重新排序(Re-ranking)是一个术语,用来描述使用另一个模型来更准确地排序最初的top文档列表的过程,这个模型的计算成本更高。这种模型通常过于昂贵,无法针对所有文档和数据块运行,但在初始相似性搜索后,针对最高数据块集运行这种模型则更为可行。重排序有助于获得更好的最终块列表,从而为 RAG 的生成部分建立输入上下文。
在 MTEB 排行榜上,嵌入模型的度量指标也有许多模型的重排名得分。在这种情况下,我使用 bge-reranker-base 模型进行重新排名:
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
rerank_model_path = "/mystuff/llm/bge-reranker-base"
rerank_tokenizer = AutoTokenizer.from_pretrained(rerank_model_path)
rerank_model = AutoModelForSequenceClassification
.from_pretrained(rerank_model_path)
rerank_model.eval()
def calculate_rerank_scores(pairs):
with torch.no_grad(): inputs = rerank_tokenizer(pairs, padding=True,
truncation=True, return_tensors='pt',
max_length=512)
scores = rerank_model(**inputs, return_dict=True)
.logits.view(-1, ).float()
return scores
question = questions[idx]
pairs = [(question, chunk) for chunk in doc_chunks_all[idx]]
rerank_scores = calculate_rerank_scores(pairs)
df["rerank_score"] = rerank_scores
将 rerank_score 添加到DataFrame 并进行排序后:
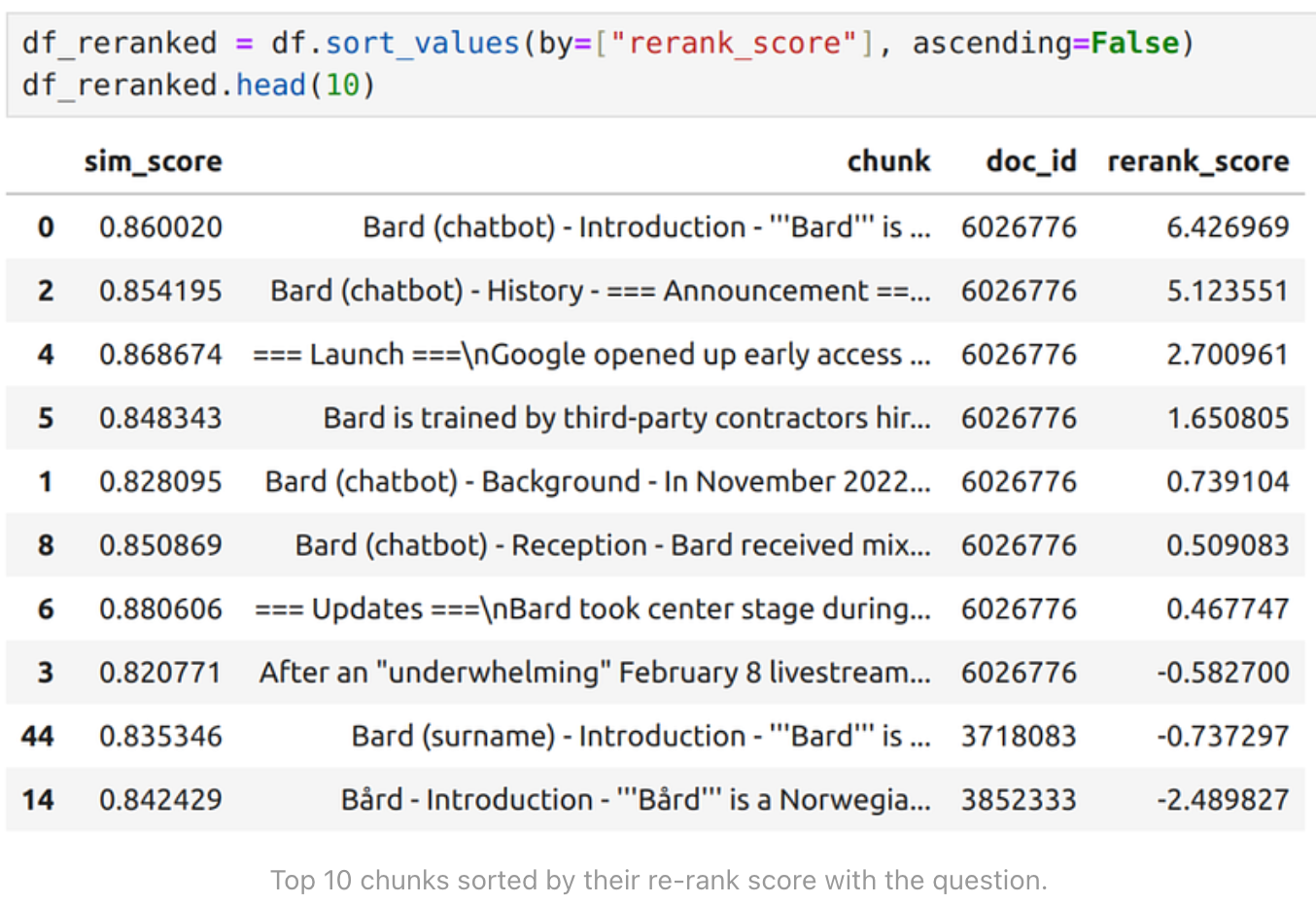
对比上面两张表格(先按 sim_score 排序,后按 rerank_score 排序),我们可以发现一些明显的不同。按照嵌入式的简单相似度得分(sim_score)排序,Tenor 页面是相似度最高的页面,排在第 5 位。由于 Tenor 看起来是由 Google 托管的 GIF 搜索引擎,我猜测将其向量与问题 “what is google bard?” 的相似性排在前五可能有一定道理。但它与 Bard 本身实际上没有太多关系,除了 Tenor 是在类似领域中的一个谷歌产品。
不过,按照 rerank_score 排序后,结果就更合理了。前十名中没有了 “Tenor”,只有前十名中的最后两块内容似乎是不相关的。这两个词分别是 "Bard "和 “B?rd”。可能是因为有关 Google Bard 的最佳信息来源似乎是 Google Bard 页面,在上述表格中,该页面的文档 ID 是 6026776。在这之后,我猜 RAG 就没有好的匹配文章了,于是就有点偏离了方向(B?rd)。这也可以从表格最后两行/块的负重排分数中看出。
通常情况下,可能会有很多相关文档和文档中的数据块,而不仅仅是上述的 1 个文档和 8 个数据块。但在本例中,这种限制有助于说明基于嵌入式的基本相似性搜索与重排序的区别,以及重排序如何对最终结果产生积极影响。
建立上下文
收集到 RAG 输入的top文本块后,我们该做什么?我们需要根据这些文本块建立生成器模型的上下文。最简单的方法就是将选中的top文本块连接成一个长文本序列。该序列的最大长度受所用模型的限制。我使用的是 Zephyr 7B 模型,最大长度为 4096 个token。Zephyr 页面给出了灵活的序列限制(具有滑动注意力窗口)。较长的上下文似乎更好,但似乎并非总是如此。最好试试看。
以下是我在这种情况下生成答案的基本代码:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
llm_answer_path = "/mystuff/llm/zephyr-7b-beta"
torch_device = "cuda:0"
tokenizer = AutoTokenizer.from_pretrained(llm_answer_path,
local_files_only=True)
llm_answer = AutoModelForCausalLM.from_pretrained(llm_answer_path,
device_map=torch_device, local_files_only=True,
torch_dtype=torch.float16)
# assuming here that "context" contains the pre-built context
query = "answer the following question, "\
"based on your knowledge and the provided context. "\n
"Keep the answer concise.\n\nquestion:" + question +
"\n\ncontext:"+context
input_ids = tokenizer.encode(query+"\n\nANSWER:", return_tensors='pt',
return_attention_mask=False).to(torch_device)
greedy_output = llm_answer.generate(input_ids, max_new_tokens=1024,
do_sample=True)
answer = tokenizer.decode(greedy_output[0], skip_special_tokens=True)
print(answer[len(query):])
如前所述,在这种情况下,上下文只是排名靠前的文本块的连接。
生成答案
为了进行比较,首先让我们试试模型在不添加任何上下文的情况下,即仅根据其训练数据得出的答案:
query = "what is google bard?"
input_ids = tokenizer.encode(query+"\n\nANSWER:", return_tensors='pt',
return_attention_mask=False).to(torch_device)
greedy_output = llm_answer.generate(input_ids, max_new_tokens=1024,
do_sample=True)
answer = tokenizer.decode(greedy_output[0], skip_special_tokens=True)
print(answer[len(query):])
由此得出(多次运行中的一次,略有不同,但大体相似):
#ANSWER:
#Google Bard is an experimental, AI-based language model developed by Google's sister company, DeepMind. Its primary use is to generate human-like text responses to prompts, which can help in tasks such as content creation, idea generation, and text summarization. Bard is trained on a vast amount of textual data and can provide highly relevant and contextually accurate responses, making it a useful tool in various applications where text generation is required. However, as an experimental feature, Bard's accuracy and effectiveness may still be improving, and it is not yet publicly available for use.
基本准确,但缺少很多最新进展。相比之下,让我们试着提供问题产生的背景:
query = "answer the following question, "\
"based on your knowledge and the provided context. "\
"Keep the answer concise.\n\n"\
"question:" + question + "\n\ncontext:"+context
input_ids = tokenizer.encode(query+"\n\nANSWER:", return_tensors='pt',
return_attention_mask=False).to(torch_device)
greedy_output = llm_answer.generate(input_ids, max_new_tokens=1024,
do_sample=True)
answer = tokenizer.decode(greedy_output[0], skip_special_tokens=True)
print(answer[len(query):])
下面是一个答案示例,上下文为 sim_score 排序最高的文本块(包括 Tenor 和 B?rd 页面块):
# ANSWER:
# Bard is a conversational generative artificial intelligence (AI) chatbot developed by Google based initially on the LaMDA family of large language models (LLMs) and later PaLM. It was launched in a limited capacity in March 2023 to mixed reviews, and expanded to other countries in May, following the launch of Microsoft's Bing Chat. Google researcher Jacob Devlin resigned from the company after alleging Bard had surreptitiously leveraged data from ChatGPT. Tenor is an online GIF search engine and database owned by Google, available on Android, iOS, and macOS. Its main product is the GIF Keyboard, which is integrated into numerous apps and messaging services. B?rd is a Norwegian masculine given name of Old Norse origin. It is sometimes used as a surname. It may refer to several people. Tenor and B?rd are not related.
这不是一个很好的答案,因为它开始谈论完全不相关的话题,即 Tenor 和 B?rd。部分原因是在这种情况下,Tenor 语块包含在上下文中,而且语块顺序一般也不太理想,因为它没有重新排序。
相比之下,使用 rerank_score 对上下文块进行排序(更好的块排序和 Tenor 消失):
# ANSWER:
# Google Bard is a conversational generative artificial intelligence (AI) chatbot, based initially on the LaMDA family of large language models (LLMs) and later on PaLM, developed by Google to compete with OpenAI's ChatGPT. It was rolled out in a limited capacity in March 2023 and expanded to more countries in May, prompting a mixed reception from critics, who raised safety and ethical concerns about its accuracy and usefulness. Google has promised that Bard will be tightly integrated with other Google AI products and services, leading to claims that a new AI-powered version of the Google Assistant, dubbed "Assistant with Bard", is being prepared for launch. Google has also stressed that Bard is still in its early stages and being continuously refined, with plans to upgrade it with new personalization and productivity features, while stressing that it remains distinct from Google Search.
现在,无关的话题不见了,答案总体上更好、更切题。
这突出表明,不仅要为模型找到适当的背景,还要剔除不相关的背景。至少在这种情况下,Zephyr 模型无法直接确定哪部分上下文是相关的,而似乎是将其全部概括了。这不能怪模型,因为是我给了它上下文并要求使用它的。
从数据块的重新排名得分来看,基于负的重排名得分等指标的一般过滤方法也能解决上述问题,因为在这种情况下,"坏 "数据块的重排名得分是负的。
值得注意的是,在我撰写这篇文章的同时,谷歌为Bard发布了新的、经过大幅改进的Gemini系列模型。由于维基百科转储的生成略有延迟,因此在这里生成的答案中并未提及。因此,正如我们可以想象的那样,在上下文中尽量提供最新信息,并保持信息的相关性和针对性是非常重要的。
可视化嵌入检查
嵌入式是一种很好的工具,但有时要真正掌握嵌入式的工作原理以及相似性搜索的情况并不容易。一个基本的方法是绘制嵌入模型之间的对比图,以便深入了解它们之间的关系。
利用 PCA 和可视化库构建这种可视化效果非常简单。它包括将嵌入向量映射到 2 维或 3 维,并绘制结果。在这里,我将 384 个维度映射为 2 维,并绘制出结果:
import seaborn as sns
import numpy as np
fp_embeddings = embedding_model.encode(first_chunks)
q_embeddings_reshaped = q_embeddings.reshape(1, -1)
combined_embeddings = np.concatenate((fp_embeddings, q_embeddings_reshaped))
df_embedded_pca = pd.DataFrame(X_pca, columns=["x", "y"])
# text is short version of chunk text (plot title)
df_embedded_pca["text"] = titles
# row_type = article or question per each embedding
df_embedded_pca["row_type"] = row_types
X = combined_embeddings pca = PCA(n_components=2).fit(X)
X_pca = pca.transform(X)
plt.figure(figsize=(16,10))
sns.scatterplot(x="x", y="y", hue="row_type",
palette={"article": "blue", "question": "red"},
data=df_embedded_pca, #legend="full",
alpha=0.8, s=100 )
for i in range(df_embedded_pca.shape[0]):
plt.annotate(df_embedded_pca["text"].iloc[i],
(df_embedded_pca["x"].iloc[i], df_embedded_pca["y"].iloc[i]),
fontsize=20 )
plt.legend(fontsize='20')
# Change the font size for x and y axis ticks plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
# Change the font size for x and y axis labels
plt.xlabel('X', fontsize=16)
plt.ylabel('Y', fontsize=16)
对于 "what is google bard?"问题的前 10 篇文章的可视化情况如下:

在这幅图中,红点是问题 "what is google bard?"的嵌入点。蓝点是根据 sim_score 得出的最接近的维基百科文章匹配。
显然,Bard文章与问题最接近,而其他文章则稍远一些。Tensor似乎是第二接近的,而B?rd一文则稍远一些,这可能是由于从 384 维映射到 2 维时损失了一些信息。
下图展示了我在 Kaggle 代码中使用类似 PCA 图发现的实际错误。为了获得一些启发,我尝试了一个关于维基百科转储中第一篇文章(“Anarchism”)的简单问题。问题是 "what is the definition of anarchism? " 。下面是最接近的文章的 PCA 可视化图,标出的异常值可能是最有趣的部分:

左下角的红点也是问题。旁边的蓝点群是关于anarchism的相关文章。然后是右上角的两个离群点。为了保持可读性,我去掉了图中的标题。这两篇离群文章看起来与问题无关。
这是为什么呢?当我用 512、256、128 和 64 等不同的分块大小为文章建立索引时,我在处理 256 分块大小的所有文章时遇到了一些问题,于是在中间重新开始了分块。这导致了一些嵌入与我存储的分块文本的索引存在差异。注意到这些奇怪的结果后,我重新计算了 256 个标记块大小的嵌入结果,并将结果与 512 个标记块大小的嵌入结果进行了比较,发现了这种差异。可惜当时比赛已经结束了 🙂
更高级的上下文选择
在上文中,我讨论了对文档进行分块,并使用相似性搜索+重新排序的方法来查找相关分块,并建立问答的上下文。我发现有时考虑如何选择初始文档进行分块与仅考虑块本身相比也是有用的。
作为示例方法,DeepLearning.AI 上的高级 RAG 课程介绍了两种方法:句子窗口和分层块合并。简而言之,这种方法就是查看附近的语块,如果多个语块的得分排名靠前,就将它们作为一个大的语块。这种 "分层 "方法是通过考虑越来越大的语块组合来确定联合相关性。与随机有序的小块相比,它的目标是获得更有凝聚力的上下文,从而为生成器 LLM 提供更好的输入。
举个简单的例子,下面是我上述Bard例子中重新排序的top块集合:

这里最左边的一列是数据块的索引。在我的生成中,我只是按照表格中的排序顺序选取了最前面的数据块。如果我们想让上下文更加连贯,可以按照文档中的顺序对最终选定的文本块进行排序。如果在排名靠前的语块之间缺少一小块,那么添加缺少的那一块(例如这里的语块 ID 7)可以帮助弥补缺失的空白,类似于分层合并。这可以作为最后一步来尝试,以获得最终收益。
在我的 Kaggle 实验中,我仅根据第一大块进行了初始文档选择。这部分是由于 Kaggle 的资源限制,但似乎也有一些其他优势。通常情况下,一篇文章的开头是摘要(引言或摘要)。从此类排序的文章中选择初始数据块可能有助于选择与整体上下文更相关的数据块。
这一点在我上面的 Bard 示例中可以看到,最佳文章的第一块的 rerank_score 和 sim_score 都是最高的。为了改善这种情况,我还尝试在初始文档选择中使用更大的块大小,以包含更多的介绍,从而提高相关性。然后用较小的块大小对选中的top文档进行分块,以实验每种大小的上下文效果如何。
虽然由于资源限制我无法在 Kaggle 上对所有文档的所有块运行初始搜索,但我在 Kaggle 之外进行了尝试。在这些尝试中,我注意到有时单个不相关文章的块会排名很高,而实际上这对于生成答案是误导的。例如,在相关电影中的演员传记。初始文档相关性选择可能有助于避免这种情况。不幸的是,我没有时间使用不同的配置进一步研究这个问题,而良好的重新排序可能已经有所帮助。
最后,在上下文中的多个信息块中重复相同的信息并不是很有用。信息块排名靠前并不能保证它们之间具有最佳互补性或最佳信息块多样性。例如,LangChain 有一个特殊的最大边际相关性(Maximum Marginal Relevance)块选择器。它的做法是,根据新块与已添加块的接近程度对其进行惩罚。
扩展RAG查询
我在 RAG 示例中使用了一个非常简单的问题/查询(“what is google bard?”) 考虑到我使用的嵌入模型的最大序列长度为 512 个token,这个查询输入非常短。如果我使用嵌入模型的标记化器(bge-small-en)将这个问题编码成标记,就会得到以下标记:
['[CLS]', 'what', 'is', 'google', 'bard', '?', '[SEP]']
这相当于总共 7 个token。由于最大序列长度为 512,因此如果我想使用更长的查询句,这就留出了足够的空间。有时这很有用,尤其是当我们想要检索的信息不是一个如此简单的查询,或者所涉及的领域更为复杂时。对于很小的查询,语义搜索的效果可能不会最好,这一点在 Stack Overflows AI Journey 的帖子中也有提到。
例如,Kaggle 竞赛有一组问题,每个问题有 5 个答案选项可供选择。我最初尝试 RAG 时,只将问题作为嵌入模型的输入。搜索结果并不理想,于是我再次尝试使用问题+所有答案选项作为查询。结果要好得多。
以竞赛训练数据集中的第一道题目为例:
Which of the following statements accurately describes the impact of Modified Newtonian Dynamics (MOND) on the observed "missing baryonic mass" discrepancy in galaxy clusters?
这对于 bge-small-en 模型来说是 32 个token。因此,在最大 512 个标记序列长度中还剩下约 480 个。
下面是第一道题和给出的 5 个答案选项:

将问题和给定选项合并为一个 RAG 查询,长度为 235 个词组,嵌入模型序列长度仍有 50%以上的剩余。就我而言,这种方法产生的结果要好得多。无论是从人工检查,还是从竞赛得分来看,都是如此。因此,尝试用不同的方法使 RAG 查询本身更具表现力是值得一试的。
幻觉
最后,还有幻觉的话题,即模型生成的文本是不正确的或捏造的。我的 sim_score 分类中的 Tenor 例子就是一个例子,即使生成器确实是根据实际给定的上下文生成的。因此,我想最好还是保持上下文的良好:)。
为了解决幻觉问题,大型人工智能公司的聊天机器人(Google Bard、ChatGPT、Bing Chat)都提供了将生成答案的部分内容链接到可验证来源的方法。Bard 有一个特定的 "G "按钮,可以执行谷歌搜索,并突出显示生成答案中与搜索结果相匹配的部分。可惜的是,我们的数据并不总能得到世界级搜索引擎的帮助。
Bing Chat 也采用了类似的方法,突出显示了答案的部分内容,并添加了源网站参考。ChatGPT 的方法略有不同;我必须明确要求它验证答案并更新最新进展,告诉它使用浏览器工具。之后,它会进行互联网搜索,并链接特定网站作为来源。与任何互联网搜索一样,来源的质量似乎差别很大。当然,对于内部文件来说,这种网络搜索是不可能的。不过,即使是在内部,也应始终可以链接到来源。
我还向 Bard、ChatGPT+ 和 Bing 询问了检测幻觉的想法。结果包括一个 LLM 幻觉排名指数,其中包括 RAG 幻觉。在调整 LLM 时,将温度参数设置为零也可能有助于 LLM 生成确定性最强的输出标记。
最后,由于这是一个非常普遍的问题,目前似乎正在开发各种方法来更好地应对这一挑战。例如,帮助检测幻觉的特定 LLM 似乎是一个很有前景的领域。我没有时间尝试,但肯定与大型项目有关。
评估结果
除了实施一个可运行的 RAG 解决方案外,能够说明它的运行情况也是一件好事。在 Kaggle 竞赛中,这一点非常简单。我只需运行解决方案,尝试回答训练数据集中给出的问题,并与训练数据中给出的正确答案进行比较。或者在 Kaggle 竞赛测试集上提交模型进行评分。答案得分越高,说明 RAG 解决方案越好,即使得分还不够高。
在很多情况下,特定领域的 RAG 可能没有合适的评估数据集。在这种情况下,我们可能需要从一些通用的 NLP 评估数据集入手,例如本列表。LangChain 等工具也支持自动生成问题和答案,并对其进行评估。在这种情况下,一个 LLM 用于为给定的文档集创建示例问题和答案,而另一个 LLM 则用于评估 RAG 是否能为这些问题提供正确答案。本教程中关于使用 LangChain 对 RAG 进行评估的内容或许能更好地解释这一点。
虽然通用解决方案可能是很好的开端,但在实际项目中,我会尝试从领域专家和 RAG 解决方案的预期用户那里收集真实的问题和答案数据集。由于 LLM 通常需要生成自然语言回答,因此在正确的情况下,回答可能会有很大的差异。因此,评估答案是否正确并不像正则表达式或类似的模式匹配那样简单。在这里,我发现使用另一个 LLM 来评估给定的回答是否与参考回答相匹配是一个非常有用的工具。这些模型可以更好地处理文本变化。
结论
RAG 是一个非常不错的工具,随着人们对 LLM 的普遍高度关注,它也成为了一个热门话题。虽然 RAG 和嵌入已经存在了很长时间,但最新的强大 LLM 及其快速发展可能使它们对许多高级用例更有吸引力。我希望该领域能继续保持良好的发展速度,有时要跟上所有方面的发展有点困难。为此,诸如 RAG 发展回顾之类的总结可以提供一些要点,至少可以让我们了解主要的发展。
一般来说,RAG 方法非常简单:找到一组与给定查询相似的文本块,将它们串联成上下文,然后向 LLM 询问答案。然而,正如我在这里试图展示的那样,如何使这种方法在不同的需求下有效地工作,需要考虑各种问题。从良好的上下文检索,到排序和选择最佳结果,最后是将结果链接回实际源文件。并对由此产生的查询上下文和答案进行评估。正如 Stack Overflow 的用户所指出的那样,尽管语义搜索很酷,但有时更传统的词法搜索或混合搜索也非常有用。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【软件测试常见Bug清单】
- .babky勒索病毒解密方法|勒索病毒解决|勒索病毒恢复|数据库修复
- 嵌入式实战(一)| GPIO实验 跑马灯效果实现 寄存器及其代码全解析
- 《JVM由浅入深学习【四】 2023-12-24》JVM由简入深学习提升分享
- 邮政快递查询,邮政快递单号查询,按物流更新量来筛选单号
- 背会了常见的几个线程池用法,结果被问翻了
- 【MybatisPlus Docker】
- NFC物联网开发读写器设计方案
- Visual Studio 2017 “无法查找或打开PDB文件“ 解决方法
- 数据处理之pandas库