MongoDB存储原理
存储引擎是数据库的组件,负责管理数据如何存储在内存和磁盘上。MongoDB 支持多个存储引擎,因为不同的引擎对于特定的工作负载表现更好。选择合适的存储引擎可以显著影响应用程序的性能。
WiredTiger 介绍
MongoDB 从 3.0 开始引入可插拔存储引擎的概念,主要有 MMAPV1、WiredTiger 存储引擎可供选择。从MongoDB 3.2 开始,WiredTiger 存储引擎是默认的存储引擎。从 4.2 版开始,MongoDB 删除了废弃的 MMAPv1 存储引擎。
WiredTiger 读写模型
读缓存
理想情况下,MongoDB 可以提供近似内存式的读写性能。WiredTiger 引擎实现了数据的二级缓存,第一层是操作系统的页面缓存,第二层则是引擎提供的内部缓存。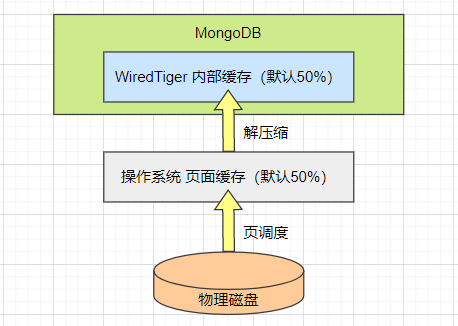
读取数据时的流程如下:
- 数据库发起 Buffer I/O 读操作,由操作系统将磁盘数据页加载到文件系统的页缓存区。
- 引擎层读取页缓存区的数据,进行解压后存放到内部缓存区。
- 在内存中完成匹配查询,将结果返回给应用。
MongoDB 为了尽可能保证业务查询的“热数据”能快速被访问,其内部缓存的默认大小达到了内存的一半,该值由 wiredTigerCacheSize 参数指定,其默认的计算公式如下:
wiredTigerCacheSize=Math.max(0.5*(RAM-1GB),256MB)
写缓冲
当数据发生写入时,MongoDB 并不会立即持久化到磁盘上,而是先在内存中记录这些变更,之后通过 CheckPoint 机制将变化的数据写入磁盘。为什么要这么处理?主要有以下两个原因:
- 如果每次写入都触发一次磁盘 I/O,那么开销太大,而且响应时延会比较大。
- 多个变更的写入可以尽可能进行 I/O 合并,降低资源负荷。
那么,MongoDB 会丢数据吗?
MongoDB 单机下保证数据可靠性的机制包括以下两个部分:
(1)CheckPoint(检查点)机制
快照(snapshot)描述了某一时刻(point-in-time)数据在内存中的一致性视图,而这种数据的一致性是 WiredTiger 通过 MVCC(多版本并发控制)实现的。当建立 CheckPoint 时,WiredTiger 会在内存中建立所有数据的一致性快照,并将该快照覆盖的所有数据变化一并进行持久化(fsync)。成功之后,内存中数据的修改才得以真正保存。默认情况下,MongoDB 每 60s 建立一次 CheckPoint,在检查点写入过程中,上一个检查点仍然是可用的。这样可以保证一旦出错,MongoDB 仍然能恢复到上一个检查点。
(2)Journal日志
Journal 是一种预写式日志(write ahead log)机制,主要用来弥补 CheckPoint 机制的不足。如果开启了 Journal 日志,那么 WiredTiger 会将每个写操作的 redo 日志写入 Journal 缓冲区,该缓冲区会频繁地将日志持久化到磁盘上。默认情况下,Journal缓冲区每 100ms 执行一次持久化。此外,Journal 日志达到 100MB,或是应用程序指定journal:true,写操作都会触发日志的持久化。一旦 MongoDB 发生宕机,重启程序时会先恢复到上一个检查点,然后根据 Journal 日志恢复增量的变化。由于 Journal 日志持久化的间隔非常短,数据能得到更高的保障,如果按照当前版本的默认配置,则其在断电情况下最多会丢失 100ms 的写入数据。
WiredTiger 写入数据的流程:
- 应用向 MongoDB 写入数据(插入、修改或删除)。
- 数据库从内部缓存中获取当前记录所在的页块,如果不存在则会从磁盘中加载(Buffer I/O)。
- WiredTiger 开始执行写事务,修改的数据写入页块的一个更新记录表,此时原来的记录仍然保持不变。
- 如果开启了 Journal 日志,则在写数据的同时会写入一条 Journal 日志(Redo Log)。该日志在最长不超过 100ms 之后写入磁盘。
- 数据库每隔 60s 执行一次 CheckPoint 操作,此时内存中的修改会真正刷入磁盘。
Journal 日志的刷新周期可以通过参数storage.journal.commitIntervalMs指定,MongoDB 3.4 及以下版本的默认值是 50ms,而 3.6 版本之后调整到了 100ms。由于 Journal 日志采用的是顺序 I/O 写操作,频繁地写入对磁盘的影响并不是很大。
CheckPoint 的刷新周期可以调整storage.syncPeriodSecs参数(默认值 60s),在 MongoDB 3.4 及以下版本中,当 Journal 日志达到 2GB 时同样会触发 CheckPoint 行为。如果应用存在大量随机写入,则 CheckPoint 可能会造成磁盘 I/O 的抖动。在磁盘性能不足的情况下,问题会更加显著,此时适当缩短 CheckPoint 周期可以让写入平滑一些。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 数据库备份脚本嘎嘎香,被秀到了!
- 041.Python异常处理_初识异常
- 知行合一:投资篇
- 推荐微信小程序的一本书!!!
- 软件是什么?前端,后端,数据库
- TikTok获客工具开发,这些代码不能少!
- JNDI注入&Log4j&FastJson&白盒审计&不回显处理
- SpringBoot 统计API接口用时该使用过滤器还是拦截器?
- 解锁 ESLint 的秘密:代码质量的守护者(下)
- OpenMP和MPI环境配置