HashMap学习和线程安全的HashMap
HashMap的底层数据结构?
HashMap在JDK1.8里面的Node数组加链表加红黑树,当链表长度大于8且数组长度大于64,链表转化为红黑树。当红黑树节点数小于6,红黑树转化为链表。在JDK1.7中是数组加链表。
为什么要用红黑树?
当hash冲突严重导致链表长度过长,影响查找性能。红黑树的查找性能相比于链表更好log(n)。
为什么链表转红黑树的阈值是8?
时间和空间的平衡。
时间:当阈值设置的太大,影响查找性能,当阈值设置的太小,红黑树和链表的性能差距不明显
空间:红黑树节点的大小是链表节点的两倍,阈值太小,性能提升不明显,且占据的空间会增大
节点分布在 hash 桶中的频率遵循泊松分布,按照泊松分布的公式计算,当节点数为8,概率非常低,不会导致频繁的转换。
为什么转回链表节点是用的6而不是复用8?
防止节点数在8附近,导致频繁的转换,影响性能。
HashMap的初始容量计算方式?
默认初始容量是16,当传入的值不是2的N次方,会计算成一个大于等于该数组的最小的一个2的N次方。算法为五次左移和或运算,通过最高位的1,拿到2个1、4个1、8个1、16个1、32个1,最后得到的值+1,会得到1个比n 大的 2 的N次方.
为什么HashMap 的容量必须是 2 的 N 次方?
计算索引位置的公式为:(n - 1) & hash,当n的值是2的N次方,n - 1 为低位全是 1 ,此时任何值跟 n - 1 进行 & 运算的结果为该值的低 N 位,达到了和取模同样的效果,实现了均匀分布。&运算比取模运算效率更好。
为什么负载因子默认值是0.75?
时间和空间的考虑。当设置为1,减少了空间,但hash冲突增大,影响查找性能,当设置的较小,空间会浪费较多。
hash的计算方式?
hash函数是先拿到 key 的hashcode,hashCode 的高16位和 hashCode 进行异或(XOR)运算,得到最终的 hash 值。相当于扰动函数,减少hash碰撞,结果更分散。当table 的长度较小的时候,n - 1的低位是1,& hash之后只会获得最低位的值,无论高位怎么变化,都不会影响结果,造成hash碰撞。
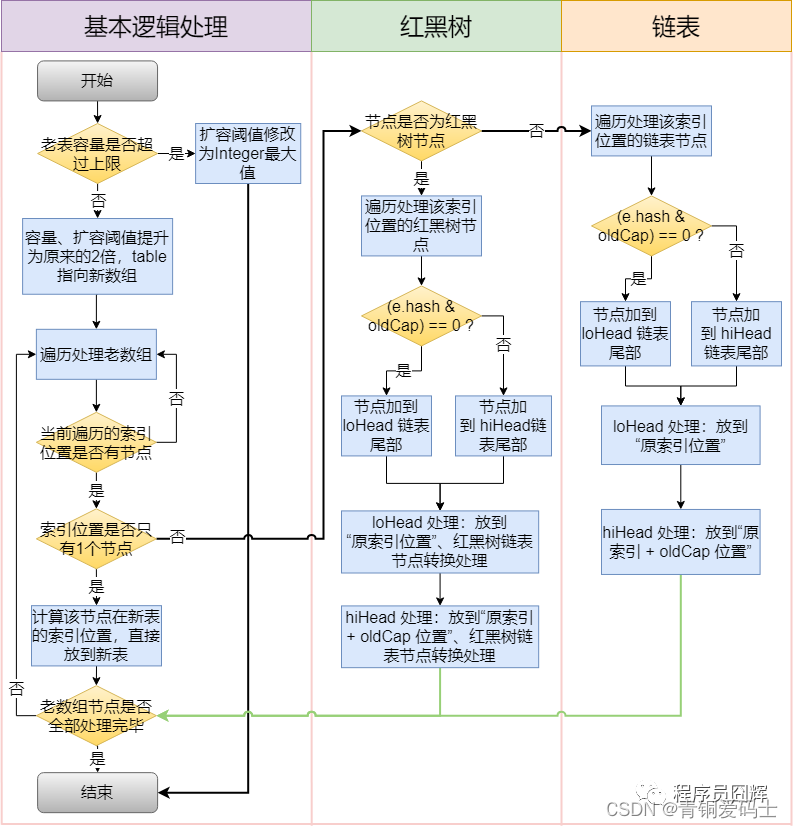
为什么红黑树和链表都是通过 e.hash & oldCap == 0 来定位在新表的索引位置?
索引的计算方式(n - 1) & hash,当扩容后,容量是之前的两倍,新的n-1比老的n-1的最高位多了一个1,因此计算新的索引位置时,只取决于高位多出来的这一位,而这一位的值刚好等于oldCap( 两者相减,值是oldCap,2的N次方)。当e.hash & oldCap == 0时,说明oldCap位是0,索引位置为“原索引位置”,当e.hash & oldCap != 0,oldCap位是1,新表索引位置为“原索引 + oldCap 位置”。
HashMap线程不安全体现在什么地方?
1.7 会产生死循环、数据丢失、数据覆盖的问题,1.8 中会有数据覆盖的问题。
当A线程判断index位置为空后正好挂起,B线程开始往index位置的写入节点数据,这时A线程恢复现场,执行赋值操作,就把A线程的数据给覆盖了;还有++size这个地方也会造成多线程同时扩容等问题。
HashMap插入流程?
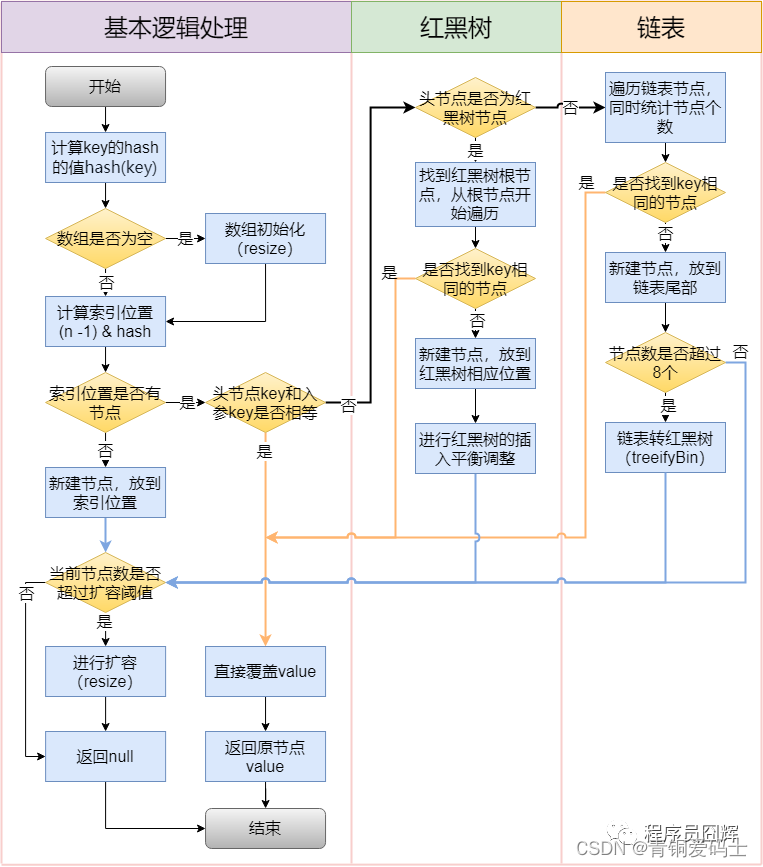
HashMap扩容流程?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!