pytorch学习笔记
发布时间:2024年01月03日
torchvision处理图像的
pytorch官网上看数据集的包,COCO数据集目标检测、语义分割,cifar物体识别
预训练好的模型

这个模块是图片的处理

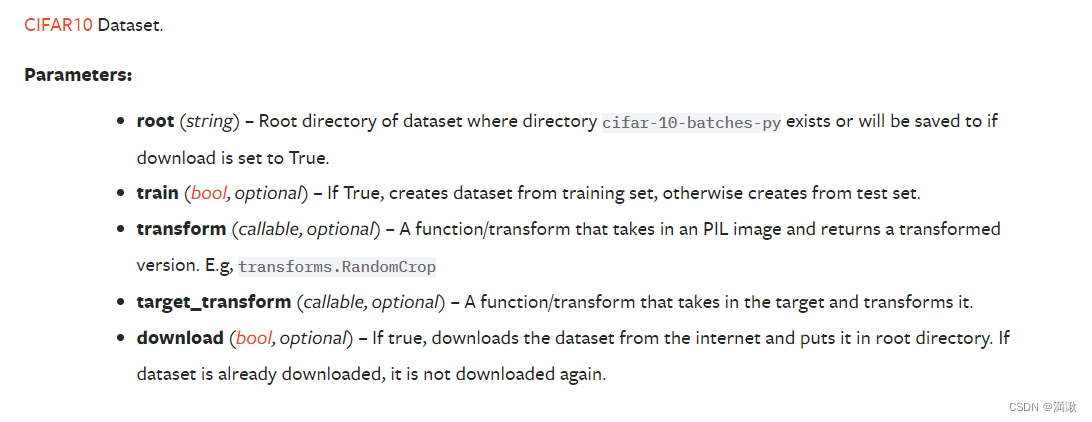
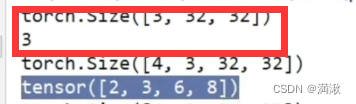
root-位置,train-创建的true是个训练集,transform


前面是输出图片的数据类型,“3”是target
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
# ###########数据集的下载,和测试集属性的展示
# train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, download=True)
# test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, download=True)
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
# print(test_set.classes)
# print(test_set[0])
# img, traget = test_set[0]
# print(img)
# print(traget)#对应的是猫
# print(test_set.classes[traget])
# img.show()
# print(test_set[0])
#和transform进行联动使用,要给pytorch进行使用的时候要转为tensor数据类型,把数据的
#用tensorboard进行展示
writer = SummaryWriter("p10")
#显示测试数据集中的前10张图片
for i in range(10):
img, traget = test_set[i]
writer.add_image("test_set", img, i)
writer.close()Dataloader使用,从dataset加载数据,把数据加载到神经网络当中。

![]()


以扑克牌为例,batch_size就是每次去抓牌抓两张,shuffle打乱,num_workers多个进程。

drop_last,例如我们有100张拍,要取他的1/3,当他除不尽,剩下的余数是要取出来还是舍去。
这边batch_size=4的效果,相当于它会把getitem得到的数据进行一个打包,然后做dataloader的返回。
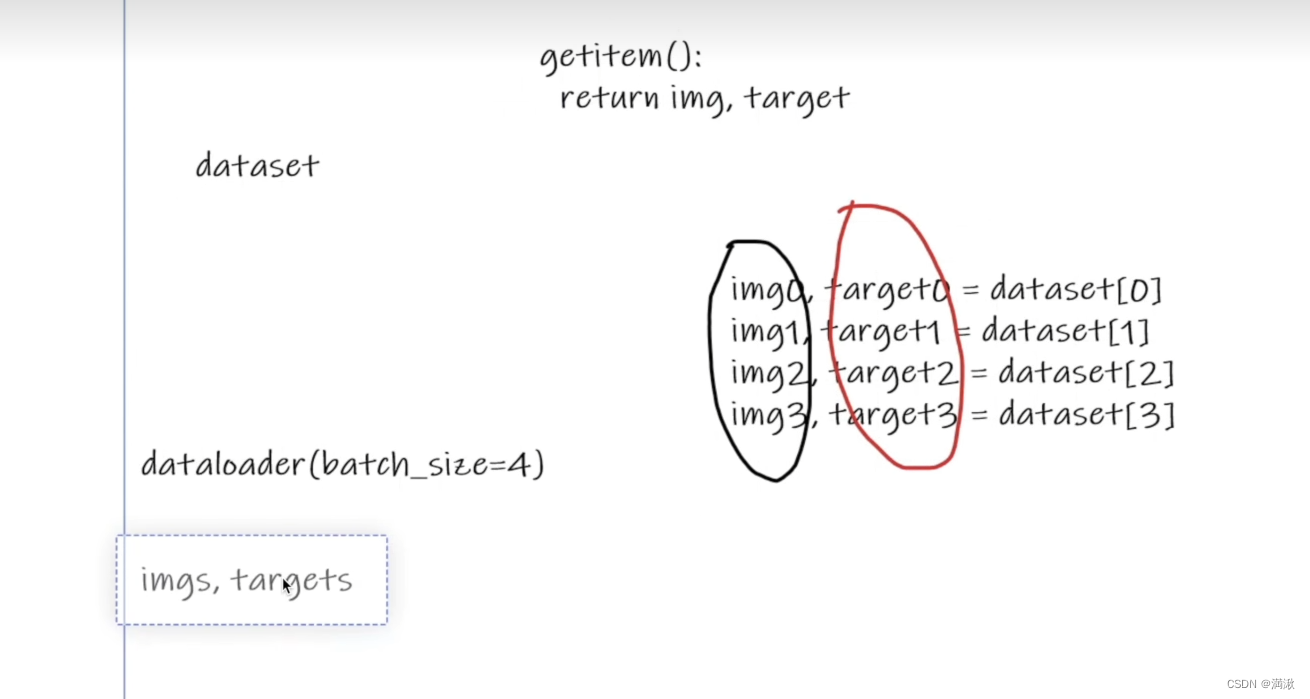
随机抓取4张图片

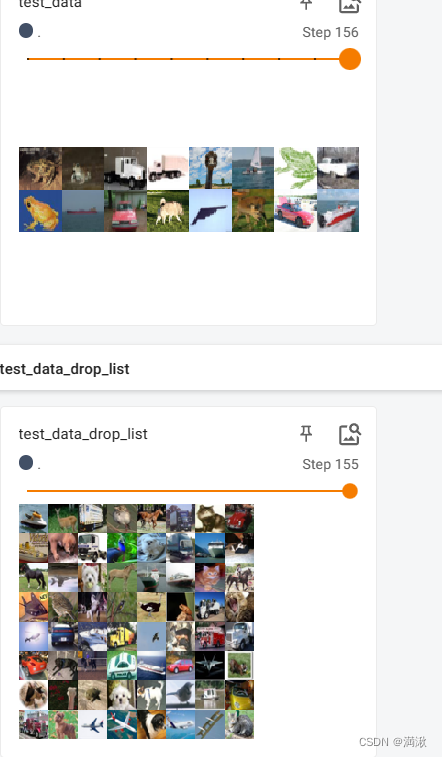
随机抓取64张图片效果展示,并且对比了drop_list有没有的情况,没有drop_list的情况下有156步,但是第156步只有16张图片,这可能导致获取的数据的大小不合适
文章来源:https://blog.csdn.net/weixin_44680341/article/details/135355133
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!