Kafka设计原理详解
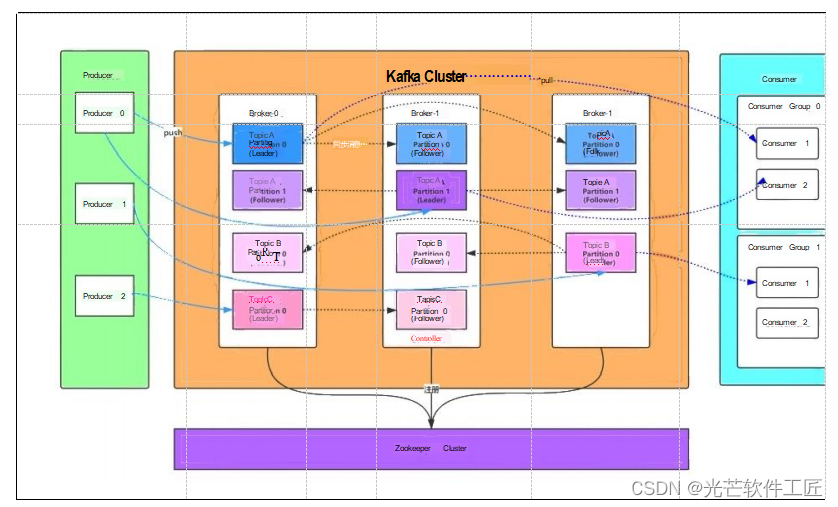
Kafka核心总控制器 (Controller)
在Kafka集群中,通常会有一个或多个broker,其中一个会被选举为控制器 (Kafka Controller),其主要职责是管理整个集群中所有分区和副本的状态。具体来说:
- 当某个分区的leader副本出现故障时,控制器负责选举新的leader副本。
- 当探测到某个分区的ISR集合发生变化时,控制器负责通知所有broker更新其元数据信息。
- 当使用kafka-topics.sh脚本为某个topic增加分区数量时,同样由控制器负责确保新分区被其他节点感知到。
Controller选举机制
Kafka集群在启动时会自动选举一台broker作为控制器,该选举过程的关键在于每个broker都尝试在Zookeeper上创建一个临时节点/controller,而Zookeeper会确保只有一个broker能够成功创建此节点,成为集群的控制器。如果当前的控制器宕机,其临时节点将消失,其他broker将监听该节点的变化,一旦发现节点消失,它们将再次竞选成为新的控制器,这便构成了控制器的选举机制。
控制器角色的broker需要承担一些额外的职责,包括:
- 监听与broker相关的变化,通过为Zookeeper中的
/brokers/ids/节点添加BrokerChangeListener来处理broker的增减变化。 - 监听与topic相关的变化,通过为Zookeeper中的
/brokers/topics节点添加TopicChangeListener来处理topic的增减变化,同时为/admin/delete_topics节点添加TopicDeletionListener以处理删除topic的操作。 - 从Zookeeper中读取并管理与topic、partition以及broker有关的所有信息,通过为所有topic对应的
/brokers/topics/[topic]节点添加PartitionModificationsListener来监听topic中分区分配的变化。 - 更新集群的元数据信息,并将其同步到其他普通的broker节点中。
Partition副本选举Leader机制
当控制器检测到某个分区的leader所在的broker宕机时,它会从ISR列表中选择第一个可用的broker作为新的leader,前提是参数unclean.leader.election.enable设置为false,这意味着只有在ISR列表中的副本之间进行选举。如果unclean.leader.election.enable设置为true,则表示在ISR列表中的所有副本都宕机时,也可以从ISR列表之外的副本中选择新的leader,这种设置可以提高可用性,但可能导致新leader的数据同步滞后。副本进入ISR列表需要满足以下两个条件:
- 副本节点不能产生分区,必须能够与Zookeeper保持会话并与leader副本保持网络连接。
- 副本必须能够复制leader上的所有写操作,并且不能滞后太多。滞后时间由
replica.lag.time.max.ms配置决定,超过此时间没有与leader同步的副本将被移出ISR列表。
消费者消费消息的offset记录机制
每个消费者定期将其消费分区的offset提交到名为__consumer_offsets的Kafka内部主题。提交时,使用key表示consumerGroupId + topic + 分区号,value表示当前的offset值。Kafka会定期清理__consumer_offsets主题中的消息,保留最新的offset记录。由于__consumer_offsets可能会受到高并发请求的影响,Kafka默认将其分配了50个分区(可以通过offsets.topic.num.partitions进行配置),以增加其并发处理能力。
消费者Rebalance机制
Rebalance指的是在消费组中的消费者数量发生变化或者消费的分区数发生变化时,Kafka会重新分配消费者与分区的关系。例如,如果消费组中的某个消费者崩溃,Kafka会自动将分配给它的分区重新分配给其他消费者,如果该消费者重新启动,则会再次接收到一些分区。需要注意的是,Rebalance仅适用于使用subscribe方式消费的情况,而不适用于使用assign方式手动指定分区的情况。
触发消费者Rebalance的情况包括:
- 消费组中的消费者数量发生变化。
- 动态增加了topic的分区。
- 消费组订阅了更多的topic。
在Rebalance过程中,消费者无法从Kafka消费消息,这可能会对Kafka的吞吐量产生影响,特别是在包含大量节点的Kafka集群中,Rebalance可能会耗费较长时间,因此应尽量避免在系统高峰期进行Rebalance操作。
Rebalance的过程可以概括如下:
当有新的消费者加入消费组时,消费者、消费组和组协调器之间会经历以下几个阶段。

第一阶段:选择组协调器(Selecting the Group Coordinator)
在消费者组(Consumer Group)中,每个消费者组会选择一个代表自己的组协调器(Group Coordinator)。这个组协调器的主要职责是监控该消费组内所有消费者的心跳,检测宕机情况,并启动消费者再平衡(Consumer Rebalance)。
每个消费者在启动时都会向 Kafka 集群的某个节点发送 FindCoordinatorRequest 请求,以查找与其对应的组协调器(Group Coordinator),然后建立与该协调器的网络连接。
组协调器的选择方式遵循以下公式:hash(consumer group id) % _consumer_offsets 主题的分区数。其中,分区的 leader 代表着该消费者组的协调器。
第二阶段:加入消费组(Joining the Consumer Group)
一旦成功找到了消费者组对应的 Group Coordinator,消费者将进入加入消费组的阶段。在这个阶段,消费者会向 Group Coordinator 发送 JoinGroupRequest 请求,并等待响应。然后,Group Coordinator 从消费者组中选择第一个加入的消费者作为组的领袖(Consumer Group Coordinator),并将消费者组的信息发送给领袖。
第三阶段:同步消费组(Sync Group)
消费者领袖通过向 Group Coordinator 发送 SyncGroupRequest 来同步消费组的状态。随后,Group Coordinator 将分区分配方案下发给各个消费者,消费者将根据指定的分区 leader broker 进行网络连接和消息消费。
消费者再平衡的分区分配策略
消费者再平衡有三种主要策略:range(范围)、round-robin(轮询)和sticky(粘性)。Kafka 提供了消费者客户端参数 partition.assignment.strategy 来设置消费者与订阅主题之间的分区分配策略,默认情况下是使用 range 分配策略。
以一个主题具有 10 个分区(0-9)和三个消费者为例,不同策略的分配如下:
-
Range 策略:按照分区序号排序,前 1 个消费者分配 4 个分区,后 2 个消费者分配 3 个分区。
- 消费者 1:分区 0-3
- 消费者 2:分区 4-6
- 消费者 3:分区 7-9
-
Round-robin 策略:轮流分配分区,每个消费者分到不同的分区。
- 消费者 1:分区 0, 3, 6, 9
- 消费者 2:分区 1, 4, 7
- 消费者 3:分区 2, 5, 8
-
Sticky 策略:初始时类似于 round-robin,但在再平衡时,需要确保两个原则:
- 分区分配尽可能均匀。
- 分区分配尽可能与上次分配相同。 当两者发生冲突时,第一个原则优先考虑。例如,如果第三个消费者挂掉,重新分配后的结果如下:
- 消费者 1:分区 0-3, 7
- 消费者 2:分区 4-6, 8, 9
生产者发布消息机制剖析
-
写入方式:生产者采用推送(push)模式将消息发布到 Kafka Broker。每条消息都被附加到相应的分区,从而实现顺序写入磁盘。这种顺序写入方式提高了 Kafka 的吞吐量,因为与随机写入内存相比,顺序写入磁盘更加高效。
-
消息路由:当生产者发送消息到 Broker 时,会根据分区算法选择将消息存储到哪个分区。路由机制如下:
- 如果指定了分区,则直接使用指定的分区。
- 如果未指定分区但指定了键(key),则根据键的值进行哈希计算,以选出一个分区。
- 如果既未指定分区也未指定键,则使用轮询方式选出一个分区。
这些步骤组成了 Kafka 生产者的消息发布流程。
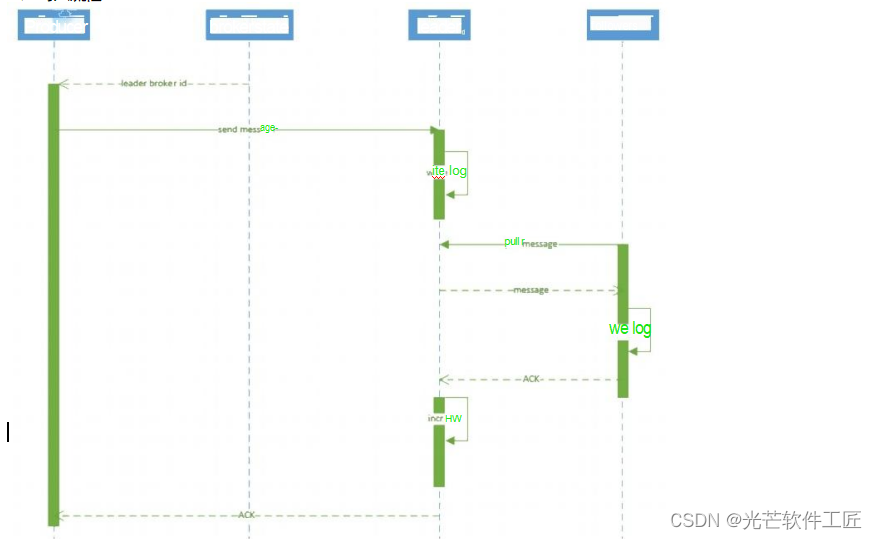
Kafka 消息写入和高水位(HW)详解
Kafka 中消息的写入和高水位(High Watermark,简称 HW)有关重要步骤,这些步骤如下:
-
生产者查找分区 leader: 生产者首先从 Zookeeper 的"/brokers/.../state"节点中找到该分区的 leader。
-
生产者向 leader 发送消息: 生产者将要发送的消息发送给分区的 leader。
-
Leader 写入消息到本地日志: 分区的 leader 将接收到的消息写入自己的本地日志。
-
Followers 从 Leader 拉取消息: 非 leader 的 followers 从分区的 leader 拉取消息,并将这些消息写入自己的本地日志。随后,followers 向 leader 发送确认 ACK。
-
Leader 收到所有 ISR 中的 Replica 的 ACK: Leader 收到来自 ISR(In-Sync Replicas,同步副本)中所有副本的确认 ACK 后,将高水位(HW,即最后 commit 的 offset)增加,并向生产者发送 ACK。
高水位(HW)和日志末尾偏移(LEO)详解
高水位(HW)通常用于限制消费者的读取位置。在 Kafka 中,HW 是 ISR 中最小的 LEO(Log-End-Offset)的值。消费者最多只能消费到 HW 所在的位置。每个 Replica(副本)都维护自己的 HW 状态,包括 Leader 和 Followers。Leader 负责等待消息被 ISR 中的所有副本同步后,才会更新 HW。这确保了消息不会在被生产后立即被消费,而是要等待所有 ISR 中的副本都同步成功后才能被消费。这种机制保证了即使 Leader 所在的 Broker 失效,消息仍然可以从新选举的 Leader 中获取。
对于来自内部 Broker 的读取请求,通常不会受到 HW 的限制,因为这些请求是针对 Kafka 内部的,而不需要考虑消费者的限制。HW 主要用于外部消费者,以确保它们不会读取到未同步的消息。

结合HW 和LEO看下?acks=1的情况

日志分段存储
Kafka一个分区的消息数据对应存储在一个文件夹下,以topic名称+分区号命名,消息在分区内是分段(segment)存储,??每个段的消息都存储在不一样的log文件里,这种特性方便old?segment?file快速被删除,kafka规定了一个段位的?log?文??件最大为1G, ?做这个限制目的是为了方便把?log 文件加载到内存去操作:

这个9936472之类的数字,就是代表了这个日志段文件里包含的起始?Offset, ?也就说明这个分区里至少都写入了接近?1000万条数据了。
Kafka Broker 有一个参数,log.segment.bytes,限定了每个日志段文件的大小,最大就是1GB。
一个日志段文件满了,就自动开一个新的日志段文件来写入,避免单个文件过大,影响文件的读写性能,这个过程叫做
log ????????rolling, 正?在?被?写?入?的?那?个 日?志?段?文?件?,?叫?做?active ??????log??????segment。
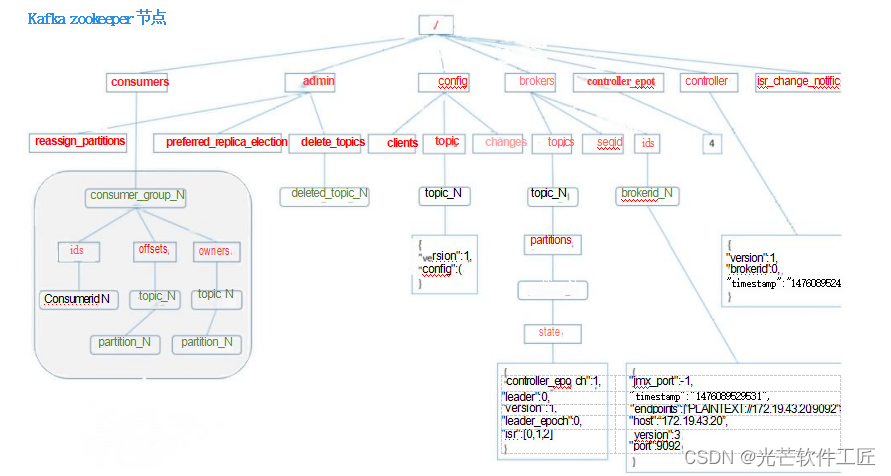
最后附一张zookeeper?节点数据图:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!