T2T VIT 学习笔记(附代码)
论文地址:https://arxiv.org/abs/2101.11986
代码地址:https://github.com/PaddlePaddle/PASSL/tree/main/configs/t2t_vit
1.是什么?
T2T-ViT是一种基于Transformer的视觉模型,用于图像分类任务。它通过将图像分割成小的图块,并使用Transformer模型对这些图块进行编码和处理,从而实现对图像的分类。
T2T-ViT模型的复杂度可以根据不同的配置进行调整。作者设计了几种不同复杂度的T2T-ViT模型,以与常见的手动设计的CNN模型进行对比。这些模型包括T2T-ViT-14、T2T-ViT-19、T2T-ViT-24、T2T-ViT-7、T2T-ViT-10和T2T-ViT-12,分别对应于ResNet50、ResNet101、ResNet152、MobileNetV1、MobileNetV2等模型的复杂度。
在实验中,作者对这些T2T-ViT模型进行了评估和比较。他们使用了常见的图像分类数据集,并通过计算模型在测试集上的准确率来评估模型的性能。实验结果表明,T2T-ViT模型在图像分类任务上取得了与手动设计的CNN模型相媲美甚至更好的性能。
2.为什么?
通过分析发现:
(1) 输入图像的简单token化难以很好的建模近邻像素间的重要局部结构(比如边缘、线条等),这就导致了少量样本时的低效性;
(2) 在固定计算负载与有限训练样本约束下,ViT中的冗余注意力骨干设计限制了特征的丰富性。可参考下图,ResNet50可以逐步捕获到期望的局部结构(比如边缘、线条、纹理等),然而ViT的结构建模信息较差,反而全局相关性被更好的获取。与此同时,可以看到:ViT的特征中存在零值,这导致其不如ResNet高效,限制了其特征丰富性。

为克服上述局限性,我们提出了一种新的Tokens-to-Token Vision Transformer,T2T-ViT,它引入了(1) 层级Tokens-to-Token变换通过递归的集成近邻Tokens为Token将渐进的将图像结构化为tokens,因此局部结构可以更好的建模且tokens长度可以进一步降低;(2) 受CNN架构设计启发,设计一种高效的deep-narrow的骨干结构用于ViT。
相比标准ViT,所提T2T-ViT的参数量与MACs可以减低200%,并取得2.5%的性能提升(注仅用ImageNet从头开始训练);所提T2T-ViT同样取得了优于ResNet的性能,比如,在ImageNet数据集上,T2T-ViT-ResNet50取得了80.7%的Top1精度。可参考下图。
 ?
?
总而言之,本文的主要贡献包含以下几个方面:
- 首次通过精心设计Transformer结构在标准ImageNet数据集上取得了全面超越CNN的性能,而无需在JFT-300M数据进行预训练;
- 提出一种新颖的渐进式Token化机制用于ViT,并证实了其优越性,所提T2T模块可以更好的协助每个token建模局部重要结构信息;
- CNN的架构设计思想有助于ViT的骨干结构设计并提升其特征丰富性、减少信息冗余。通过实验发现:
deep-narrow结构设计非常适合于ViT。
3.怎么样?
3.1网络结构
3.1.1Tokens-to-Token
Tokens-to-Token(T2T)模块旨在克服ViT中简单Token化机制的局限性,它采用渐进式方式将图像结构化为token并建模局部结构信息;而Tokens的长度可以通过渐进式迭代降低,每个T2T过程包含两个步骤:Restructurization与SoftSplit,见下图。

Re-structurization?
?如上图所示,给定Tokens序列T,将通过自注意力模块对齐进行变换处理,可以描述为:
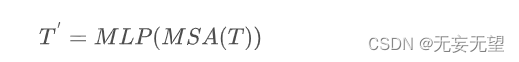
注:MSA表示多头自注意力模块,MLP表示多层感知器。经过上述变换后,Tokens将在空间维度上reshape为图像形式,描述如下:?
![]()
?Soft Split
正如上图所示,在得到重结构化图像I后,作者对其进行软拆分操作以建模局部结构信息,降低Tokens长度。为避免图像到tokens过程中的信息损失,将图像拆分为重叠块,也就是说:每个块将与近邻块之间构建相关性。每个拆分块内的Token将通过Concat方式变换为一个Token(即Tokens-to-Token),因此可以更好的建模局部信息。作者假设每个块大小为k*k ,重叠尺寸为s,padding为p,对于重建图像?,其对应的输出Token?可以表示为如下尺寸:

注:每个拆分块尺寸为k*k*c?。最后将所有块在空域维度上flatten为Token?。这里所得到的输出Token将被送入到下一个T2T处理过程。?
3.1.2?T2T module
通过交替执行上述Re-structurization与Soft Split操作,T2T模块可以逐渐的减少Token的长度、变换图像的空间结构。T2T模块可以表示为如下形式:

对于输入图像?,作者采用SoftSplit操作将其拆分为Token:
?。在完成最后的迭代后,输出Token
?具有固定IG长度,因此T2T-ViT可以在?
上建模全局相关性。
另外,由于T2T模块中的Token长度要比常规形式的更大,故而MAC与内存占用会非常大。为克服该局限性,在T2T模块中,作者设置通道维度为32(或者64)以降低MACs。
例子:
为了方便理解流程,这里不考虑 batch size,定义输入尺寸为?3, 224, 224,首先经过一次 soft split,将图像转为二维张量,这个过程利用?nn.Unfold?函数,如下所示

然后我们通过 T2T Transformer 来提取 Token 的全局信息,T2T Transformer 和 ViT 的 MSA 极其相似,都采用了 Self-Attention 结构?

接下来就是 T2T process 部分,论文给出的流程图如下所示,其中我们目前得到的数据(size=3136, 64)对应下图的 Ti’,我们可以看见 T2T process 操作流程为Reshape+Unfold
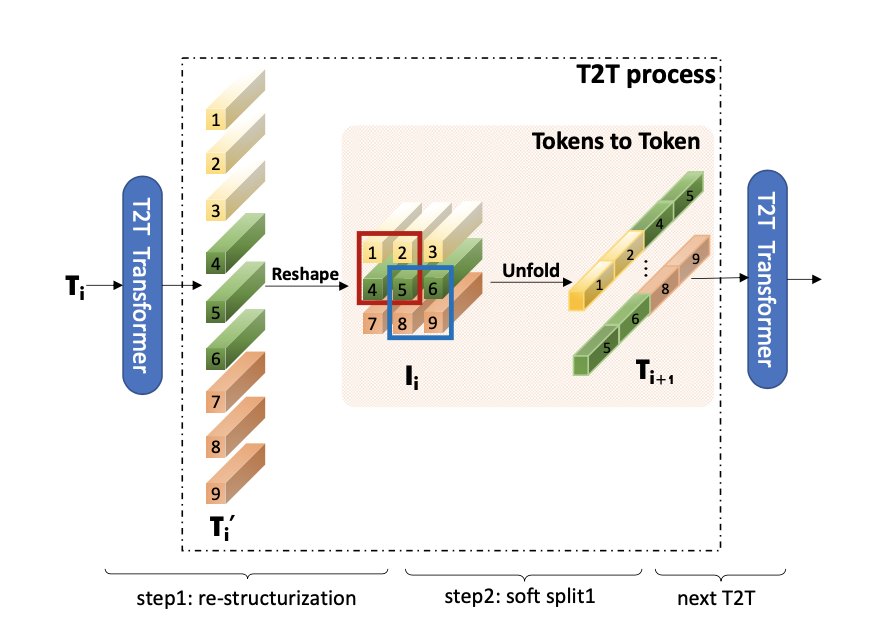
为什么要这样做呢?怎么理解上图的 Tokens to Token?
实际上 soft split 操作是用来模拟局部结构信息,作者希望建立一个先验,即周围的 Token 之间应该有更强的关联性,如上图所示,token1、token2、token4、token5 这4个 token 局部相邻,将它们通过 Unfold(soft split 操作)来融合成新的 token,如上图 Ti+1[0] 所示
T2T process 详细输出变化如下所示

?其中 T2T Transformer 用于提取全局表征,T2T process 用于引入局部先验,这两个模块交替进行特征提取,得到输出为196, 576,然后通过 Linear 得到 final token(196,576 --Linear--> 196,786)。
3.1.3?T2T-ViT Backbone
?由于ViT骨干中的不少通道是无效的,故而作者计划设计一种高效骨干以降低冗余提升特征丰富性。T2T-ViT将CNN架构设计思想引入到ViT骨干设计以提升骨干的高效性、增强所学习特征的丰富性。由于每个Transformer具有类似ResNet的跳过连接,一个最直接的想法是采用类似DenseNet的稠密连接提升特征丰富性;或者采用Wide-ResNet、ResNeXt结构改变通道维度。本文从以下五个角度进行了系统性的比较:
-
Dense Connection,类似于DenseNet;
-
Deep-narrow vs shallow-wide结构,类似于Wide-ResNet一文的讨论;
-
Channel Attention,类似SENet;
-
More Split Head,类似ResNeXt;
-
Ghost操作,类似GhostNet。
结合上述五种结构设计,作者通过实验发现:(1) Deep-Narrow结构可以在通道层面通过减少通道维度减少冗余,可以通过提升深度提升特征丰富性,可以减少模型大小与MACs并提升性能;(2) 通道注意力可以提升ViT的性能,但不如Deep-Narrow结构高效。
基于上述结构上的探索与发现,作者为T2T-ViT设计了Deep-Narrow形式的骨干结构,也就是说:更少的通道数、更深的层数。对于定长Token?,将类Token预期Concat融合并添加正弦位置嵌入(Sinusoidal Position Embedding, SPE),类似于ViT进行最后的分类:
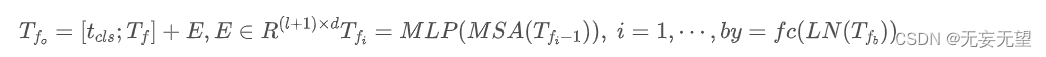
 3.2代码实现
3.2代码实现
3.2.1.?T2T ViT
class T2T_ViT(nn.Module):
"""
:param
img_size: 图像尺寸
tokens_type: tokens类型,分为经典的vit的token和谷歌performer的token
in_chans: 输入的通道数
num_classes: 分类类别数
embed_dim: 每个patch的编码长度
depth: token to token处理的深度
drop_path_rate: 防过拟合的比例
mlp_ratio: 多层感知器中隐藏层结点数目与输入结点数目的比例
qkv_bias: query、key、value向量是否偏置,因此qkv是通过Linear层生成的参数矩阵,可以设定其偏置
qk_scale: query * key 的缩放比例
drop_rate:
"""
def __init__(self, img_size=224, tokens_type='performer', in_chans=3, num_classes=1000, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., norm_layer=nn.LayerNorm, token_dim=64):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.tokens_to_token = T2T_module(
img_size=img_size, tokens_type=tokens_type, in_chans=in_chans, embed_dim=embed_dim, token_dim=token_dim)
num_patches = self.tokens_to_token.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(data=get_sinusoid_encoding(n_position=num_patches + 1, d_hid=embed_dim),
requires_grad=False)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)
for i in range(depth)])
self.norm = norm_layer(embed_dim)
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def no_weight_decay(self):
return {'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
x = self.tokens_to_token(x)
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embed
x = self.pos_drop(x)
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x3.2.2 T2T Module:通过这样的一个模块,让模型更好的感知图像中的纹理特征信息,从而达到更好的分类效果
class T2T_module(nn.Module):
"""
Tokens-to-Token encoding module
"""
def __init__(self, img_size=224, tokens_type='performer', in_chans=3, embed_dim=768, token_dim=64):
super().__init__()
if tokens_type == 'transformer':
print('adopt transformer encoder for tokens-to-token')
# unfold将卷积核相同位置的元素放置在一起组成新的向量,这样可以类似卷积网络那样提取出领域特征信息
self.soft_split0 = nn.Unfold(kernel_size=(7, 7), stride=(4, 4), padding=(2, 2))
self.soft_split1 = nn.Unfold(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.soft_split2 = nn.Unfold(kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
self.attention1 = Token_transformer(dim=in_chans * 7 * 7, in_dim=token_dim, num_heads=1, mlp_ratio=1.0)
self.attention2 = Token_transformer(dim=token_dim * 3 * 3, in_dim=token_dim, num_heads=1, mlp_ratio=1.0)
self.project = nn.Linear(token_dim * 3 * 3, embed_dim)
self.num_patches = (img_size // (4 * 2 * 2)) * (
img_size // (4 * 2 * 2)) # there are 3 sfot split, stride are 4,2,2 seperately
def forward(self, x):
# 第一次重构数据
x = self.soft_split0(x).transpose(1, 2)
# 第一次Attention机制
x = self.attention1(x)
B, new_HW, C = x.shape
x = x.transpose(1, 2).reshape(B, C, int(np.sqrt(new_HW)), int(np.sqrt(new_HW)))
# 第二次重构数据
x = self.soft_split1(x).transpose(1, 2)
# 第二次Attention机制
x = self.attention2(x)
B, new_HW, C = x.shape
x = x.transpose(1, 2).reshape(B, C, int(np.sqrt(new_HW)), int(np.sqrt(new_HW)))
# 第三次重构数据
x = self.soft_split2(x).transpose(1, 2)
# 产生新的token
x = self.project(x)
return x? ? ? ? 2.Embedding:(cls token adding+ position embedding)
? ? ? ? 3.Block:(和Vit中的Norm-Attention、Norm-MLP组成的encoder一致)
? ? ? ? ? ? ? ? NormLayer -> Attention -> ResLayer in DropPath
? ? ? ? ? ? ? ? -> NormLayer -> MLP -> ResLayer in DropPath
? ? ? ? 4.Linear 类别映射
————————————————
版权声明:本文为CSDN博主「尼卡尼卡尼」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_42418728/article/details/120550784
参考:ResNet被全面超越了,是Transformer干的:依图科技开源“可大可小”T2T-ViT
各类Transformer都得稍逊一筹,LV-ViT:探索多个用于提升ViT性能的高效Trick?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- linux 内核链表操作
- 最新版本Vue3的学习笔记-第一章
- 浙江大唐乌沙山电厂选择ZStack Cloud打造新一代云基础设施
- 解决windows环境变量配置完不生效
- CSS实现旋转圆角叠加样式,你学会了吗?
- trino-435: trino接入TIDB数据源
- 腾讯云轻量应用服务器和云服务器哪个好
- 神级的PPT收藏馆
- [C++从入门到精通] 10.回顾类内初始化、默认构造函数、=default
- 推动老年人社区服务(源码+开题)