20240124-大模型日报
大模型学会听音乐了!风格乐器精准分析,还能剪辑合成
https://mp.weixin.qq.com/s/idTbJr7GhtyQejbqLQ7BtQ
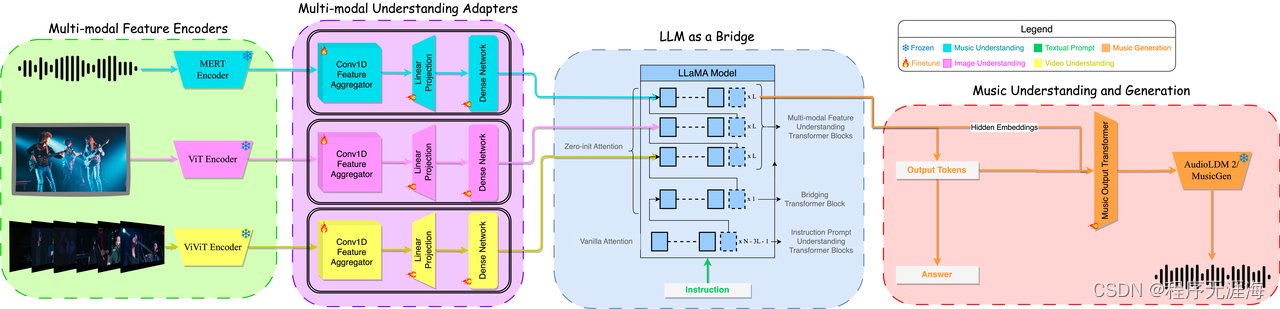
能处理音乐的多模态大模型,终于出现了!只见它准确分析出音乐的旋律、节奏,还有使用的乐器,甚至其中的意境也能解读。腾讯PCG ARC实验室新推出的基于多模态模型的音乐理解与生成框架M2UGen。它可以进行音乐理解、音乐编辑以及多模态音乐生成(文本/图像/视频到音乐生成)。研究团队在模型的五种能力上分别和现有模型进行了一一对比,并在多模态音乐生成的三个子任务上(文本/图像/视频到音乐生成)做了主观评测实验,发现M2UGen模型性能均优于现有模型。
视觉Mamba模型的Swin时刻,中国科学院、华为等推出VMamba
https://mp.weixin.qq.com/s/1h4z2Kb0B5GTPnSUUU8c8g
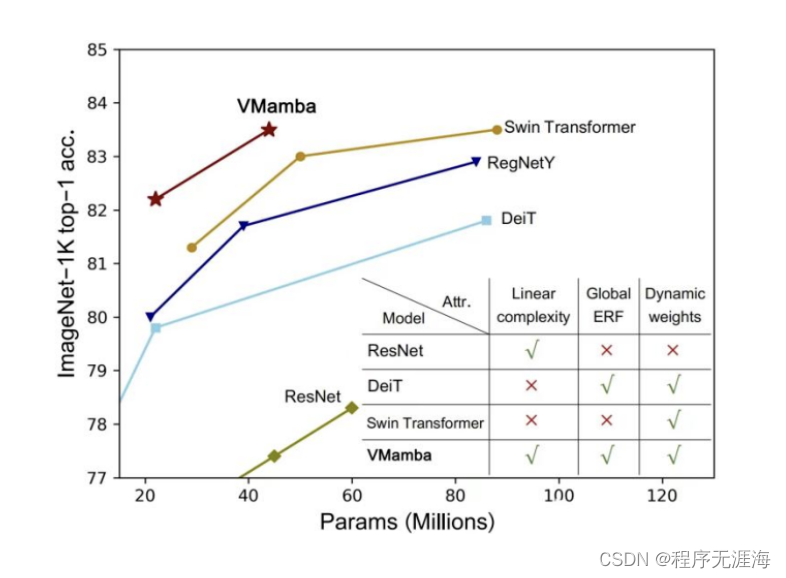
Transformer 在大模型领域的地位可谓是难以撼动。不过,这个AI 大模型的主流架构在模型规模的扩展和需要处理的序列变长后,局限性也愈发凸显了。Mamba的出现,正在强力改变着这一切。它优秀的性能立刻引爆了AI圈。上周四, Vision Mamba(Vim)的提出已经展现了它成为视觉基础模型的下一代骨干的巨大潜力。仅隔一天,中国科学院、华为、鹏城实验室的研究人员提出了 VMamba:一种具有全局感受野、线性复杂度的视觉 Mamba 模型。这项工作标志着视觉 Mamba 模型 Swin 时刻的来临。
零一万物Yi-VL多模态大模型开源,MMMU、CMMMU两大权威榜单领先

https://mp.weixin.qq.com/s/LXrEFN7chMGas7yTytC52w
1 月 22 日,零一万物 Yi 系列模型家族迎来新成员:Yi Vision Language(Yi-VL)多模态语言大模型正式面向全球开源。据悉,Yi-VL 模型基于 Yi 语言模型开发,包括 Yi-VL-34B 和 Yi-VL-6B 两个版本。
Yi-VL 模型开源地址:
继特斯拉后 宝马工厂开始部署人形机器人

https://www.cls.cn/detail/1576698
宝马公司将在美国斯帕坦堡工厂部署机器人初创公司Figure的人形机器人;Figure首席执行官称,双方的合作将从少量开始,如果达到了性能目标,就会扩大规模;目前,包括特斯拉、本田等多家汽车制造商都开始使用人形机器人来承担某些体力工作。
日报小编下岗最快的一集:MultiOn 和modal labs合作,安排长时间运行的AI代理每天在后台自主地代表您执行任务

https://x.com/DivGarg9/status/1749149133317996796?s=20
宣布@MultiOn_AI 与 @modal_labs 合作!🚀
现在,您可以安排长时间运行的AI代理每天在后台自主地代表您执行任务🔥
尝试我们的Twitter AI新闻代理,它每天找到最新的AI新闻并发布推文👇:
https://modal.com/docs/examples/multion_news_agent
Sanseviero分享《句子嵌入。交叉编码器和重新排序》
https://x.com/osanseviero/status/1749013453686128652?s=20
Omar Sanseviero:
新博客文章发布了!我们讨论了检索和重新排序SPECTER2、增强句子嵌入等内容!我们还实现了一个使用不同开源模型的排名系统。祝您阅读愉快!
《句子嵌入。交叉编码器和重新排序》
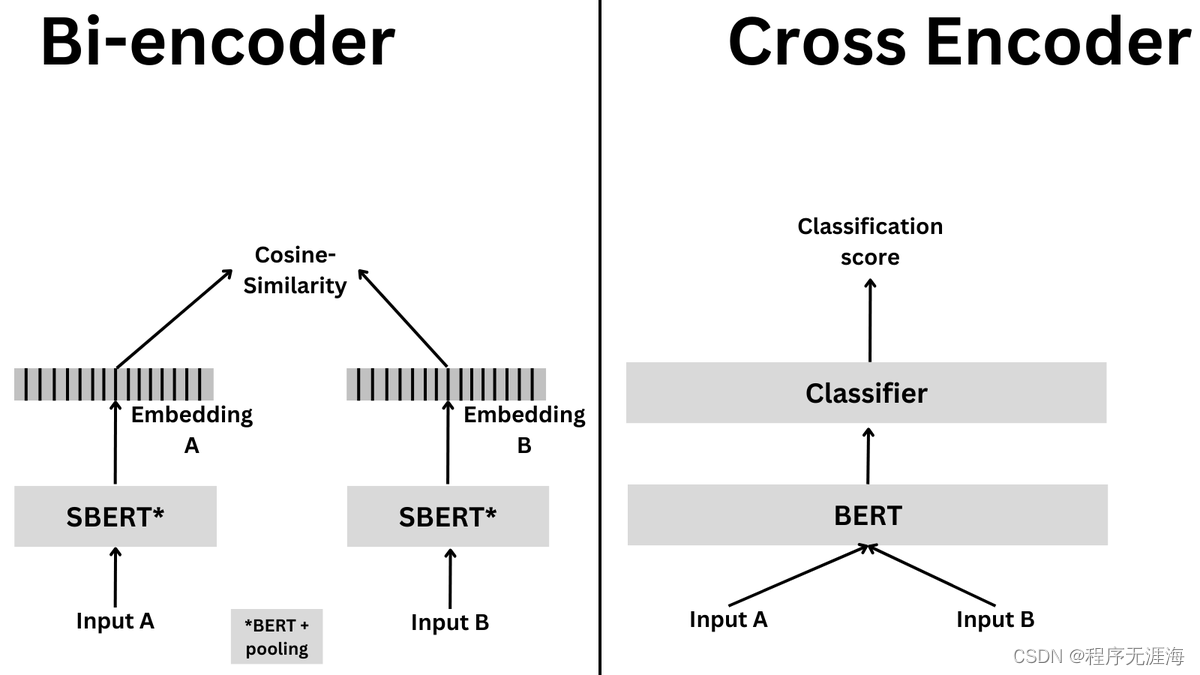
句子转换器支持两种类型的模型:双编码器和交叉编码器。双编码器更快且更具可扩展性,但交叉编码器更准确。尽管两者都处理类似的高级任务,但在何时使用哪一种方面则大不相同。双编码器更适合搜索任务,而交叉编码器更适合分类和高精度排名。让我们深入细节!
使用crewAI代理创建游戏:使用CrewAI框架自动化创建简单游戏
https://x.com/joaomdmoura/status/1749131650850570737?s=20
👾使用AI代理创建游戏🚣♂?,采用crewAI
代码是开源的:https://github.com/joaomdmoura/crewAI-examples/tree/main/game-builder-crew
如果你喜欢的话,我会非常感激你的转发?
这只是一个简单的例子,但如果你想知道如何将这样的东西构建到你的应用中,请查看https://crewai.io。
AI Crew用于游戏构建
这个项目是使用CrewAI框架自动化创建简单游戏的一个示例。CrewAI协调自主AI代理,使它们能够协作并高效执行复杂任务。
从亚马逊机器人总数已达超过750,000台看机器人行业的快速扩张
https://x.com/LinusEkenstam/status/1749216813416636791?s=20
亚马逊在其全球仓库和分配网络中部署了超过750,000台机器人,显示出机器人行业的快速扩张。从2013年的1,000台到2023年的750,000台,这种增长凸显了人工智能、机器人和计算机视觉在取代人力劳动方面的显著影响。这不仅加速了对高技能工作的需求,也意味着未来劳动力将面临重大的技能提升和转型挑战,标志着我们进入了机器人时代和智能时代。
AI Lawyer

AI Lawyer 利用 AI 技术改变法律援助。它非常适合寻求简单、负担得起的法律建议的消费者以及希望自动化研究和文书工作等日常任务的律师。
Cartbuddygpt
https://cartbuddygpt.com/
CartBuddyGPT 是一款由 GPT 驱动的购物助手,简化用户的在线购物体验。用户可以通过查询或请求与 CartBuddyGPT 进行交互,然后通过人工智能来解析大量的产品目录,以满足用户的特定需求和预算,提供包含详细信息的产品列表,如标题、价格、客户评级和其他关键属性,这些信息以易于访问的格式呈现。
demo-ai-app

https://github.com/sst/demo-ai-app
借助 AI 功能,帮助用户更准确的搜索需要的电影,用户可以通过对情节和电影画面的描述进行搜索。
InstantID

https://github.com/InstantID/InstantID
InstantID 是一种用于个性化图像合成的解决方案。该方法的特点包括低存储需求、一次前向推理、基于ID嵌入、高人脸保真度、即插即用模块、新颖的身份网设计以及与预训练文本到图像扩散模型的集成。InstantID 希望可以解决其他方法存在的问题,如高存储需求、冗长的微调过程、对多个参考图像的需求以及与社区预训练模型的兼容性问题。它的设计旨在提高效率,同时保持生成图像的高质量和真实感。
在英特尔GPU上的高效大型语言模型推理解决方案
https://arxiv.org/abs/2401.05391
该论文提出了一种在英特尔GPU上进行高效的大型语言模型(LLM)推理的解决方案。首先,为了降低内存访问频率和系统延迟,简化了LLM解码层,将数据移动和逐元操作融合。提出了分段KV缓存策略,有效管理设备内存,帮助扩大运行时批大小,提高系统吞吐量。还设计了一个自定义的缩放点积注意力(Scaled-Dot-Product-Attention)核心,以匹配分段KV缓存方案。相比于标准的HuggingFace实现,所提出的解决方案在英特尔GPU上达到了高达7倍的令牌延迟降低和27倍的吞吐量提高。
分析transformer模型的参数量、计算量、中间激活、KV cache
https://zhuanlan.zhihu.com/p/624740065
文章深入分析了transformer模型在大模型训练中的参数量、计算量、中间激活、以及推理时的KV缓存。主要挑戰包括显存效率和计算效率。训练LLM(大型语言模型)需要考虑模型参数大小、self-attention层及MLP层的复杂性,以及位置编码的策略。文章重点分析了在混合精度训练中,显存占用分为模型参数、中间激活、梯度和优化器状态。提出了使用激活重计算来节省显存,通过牺牲计算时间来换取显存。在模型推理过程中,KV缓存被作为一种提高推断速度的技术。文章的技术分析有助于理解和优化大模型训练和推断过程中的资源利用率。
利用LangChain、OpenAI、ChromaDB和Streamlit构建RAG
https://mp.weixin.qq.com/s/rtreZ7nQADnBvke6h9CgPw
文章探讨了如何利用ChromaDB构建基于检索增强生成(RAG)的LLM(大型语言模型)应用,并实现RAG驱动的聊天应用。ChromaDB的优势在于处理大型数据集的高效性,RAG结合信息检索与LLM,通过查询外部文档产生知情的智能响应。实现过程涵盖环境设置、文档处理、创建嵌入、以及通过Streamlit创建用户界面,该界面允许用户上传文件并提问,系统依然由LLM提供答案。通过这种方式,构建的聊天应用利用Generative AI解答与输入文件相关的问题。
https://medium.com/@oladimejisamuel/unlocking-the-power-of-generativeai-building-a-cutting-edge-rag-chat-application-with-chromadb-c5c994ccc584
单卡 3 小时训练专属大模型 Agent:基于 LLaMA Factory 实战
https://zhuanlan.zhihu.com/p/678989191
文章介绍了如何在3小时内使用单卡GPU训练出专属的LLM代理,通过LLaMA Factory平台实现。作者强调外部工具调用是LLM代理的一个关键能力,让模型可以处理实时和准确的信息,降低幻觉现象。微调模型有利于提高工具使用能力,文章选用的是Yi-6B双语模型,通过合适的数据集加强模型对话与工具调用功能。最后,还展示了如何将训练好的模型部署到生产环境,强化了LLM代理在任务解决中的出色能力。
通过代理调优语言模型
https://arxiv.org/abs/2401.08565
这篇论文介绍了一种名为“代理调优”的新颖算法,用于提升大型预训练语言模型的性能。该算法独特之处在于,它无需直接修改模型权重,只需通过模型的输出词汇表预测来实现调优。研究者通过调优一个小型语言模型,然后利用这个调优模型与未调优模型在预测上的差异,来调整基础模型的预测,从而在保持大规模预训练优势的同时实现调优目标。该方法在实验中显示出强大的效果,尤其是在知识、推理和安全性方面的基准测试中。这一技术对于资源有限或无法访问模型权重的情况尤为有用,为语言模型的高效定制提供了新的途径。
Awesome-LLM-RAG-Application
https://github.com/lizhe2004/Awesome-LLM-RAG-Application
GitHub上的"Awesome-LLM-RAG-Application"仓库由用户lizhe2004创建,聚焦于基于大型语言模型(LLM)与检索生成(RAG)模式的应用资源。该仓库很可能包含关于如何将RAG模式与LLM结合以增强其在各类任务中的性能表现的项目、论文、工具及相关资源集合。RAG模式通过从数据集中检索信息,然后基于这些信息生成恰当回应来优化AI应用的功能。此仓库旨在为对此开发方法感兴趣者提供参考。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【MyBatis-Plus】简化你的Java持久层开发
- java(渣哇)------输入与输出语句(详解) (???.??)
- 在Linux中遇到“没有可用软件包”的情况
- 认知觉醒(九)
- 跳跃游戏系列总结
- c++ 容器举例
- 在GBASE南大通用ADO.NET 中调用一个存储过程
- 算法设计与分析实验报告-贪心算法
- 体验新时代的CNI--cilium
- STL是什么?它有什么功能和特性?它值不值得我们去学习?我们该如何去学习呢?