LangChain中的检索增强生成(RAG)
概述[2]
什么是RAG?[3]
RAG是一种通过额外的、通常是私有或实时的数据来增强LLM知识的技术。LLM能够推理各种广泛的主题,但它们的知识仅限于它们训练时的公共数据,到达其特定时间节点为止。如果你想构建可以推理私人数据或在模型截止日期之后引入的数据的人工智能应用程序,你需要用特定信息增强模型的知识。将适当的信息带入并插入到模型提示中的过程被称为“检索增强生成”(RAG)。
检索增强生成?(RAG)?是一种使用来自私有或专有数据源的信息来辅助文本生成的技术。它将检索模型(设计用于搜索大型数据集或知识库)和大型语言模型?(LLM),此类模型会使用检索到的信息生成可供阅读的文本回复)结合在一起。通过从更多数据源添加背景信息,以及通过训练来补充?LLM?的原始知识库,检索增强生成能够提高搜索体验的相关性。这能够改善大型语言模型的输出,但又无需重新训练模型。额外信息源的范围很广,从训练?LLM?时并未用到的互联网上的新信息,到专有商业背景信息,或者属于企业的机密内部文档,都会包含在内。RAG?对于诸如回答问题和内容生成等任务,具有极大价值,因为它能支持生成式?AI?系统使用外部信息源生成更准确且更符合语境的回答。它会实施搜索检索方法(通常是语义搜索或混合搜索)来回应用户的意图并提供更相关的结果。

检索增强生成的工作流程
- 检索:?首先,我们需要进行的是检索过程。在这个阶段,我们利用用户的查询内容,从外部知识源获取相关信息。具体来说,就是将用户的查询通过嵌入模型转化为向量,这样就可以与向量数据库中的其他上下文信息进行比对。通过这种相似性搜索,我们可以找到向量数据库中最匹配的前k个数据。
- 增强:接下来,我们进入增强阶段。在这个阶段,我们将用户的查询和检索到的额外信息一起嵌入到一个预设的提示模板中。这个过程的目的是为了提供更丰富、更具上下文的信息,以便于后续的生成过程。
- 生成:?最后,我们进行生成过程。在这个阶段,我们将经过检索增强的提示内容输入到大语言模型(LLM)中,以生成所需的输出。这个过程是RAG的核心,它利用了LLM的强大生成能力,结合了前两个阶段的信息,生成了准确、丰富且与上下文相关的输出。
包含内容[4]
LangChain具有一些专门设计来帮助构建RAG应用程序的组件。为了熟悉这些组件,我们将在一个文本数据源上构建一个简单的问答应用程序。具体而言,我们将在Lilian?Weng的LLM?Powered?Autonomous?Agents[5]博文上构建一个QA机器人。在此过程中,我们将介绍一个典型的QA架构,讨论相关的LangChain组件,并突出更高级的QA技术的其他资源。我们还将看到LangSmith如何帮助我们跟踪和理解我们的应用程序。随着我们的应用程序变得越来越复杂,LangSmith将变得越来越有帮助。?注意?这里我们关注的是无结构数据的?RAG。我们在其他地方涵盖的两个?RAG?应用场景是:
?对结构化数据进行?QA[6](例如,SQL)
?对代码进行?QA[7](例如,Python)
架构[8]
一个典型的?RAG?应用有两个主要组件:
索引化:从来源中摄取数据并进行索引的流程。通常在离线状态下进行。
检索和生成:实际的RAG链,在运行时接收用户查询并从索引中检索相关数据,然后将其传递给模型。
从原始数据到答案的最常见完整序列如下:
索引化[9]"
- 加载:首先,我们需要加载数据。我们将使用DocumentLoaders[10]?来实现这一点。
- 分割:文本分割器[11]?将大的Documents分割为较小的块。这对于索引数据和传递给模型都很有用,因为大块的数据较难搜索,而且无法在模型的有限上下文窗口中使用。
- 存储:我们需要一个地方来存储和索引我们的分割数据,以便以后可以进行搜索。通常使用VectorStore[12]和Embeddings[13]模型来实现这一点。
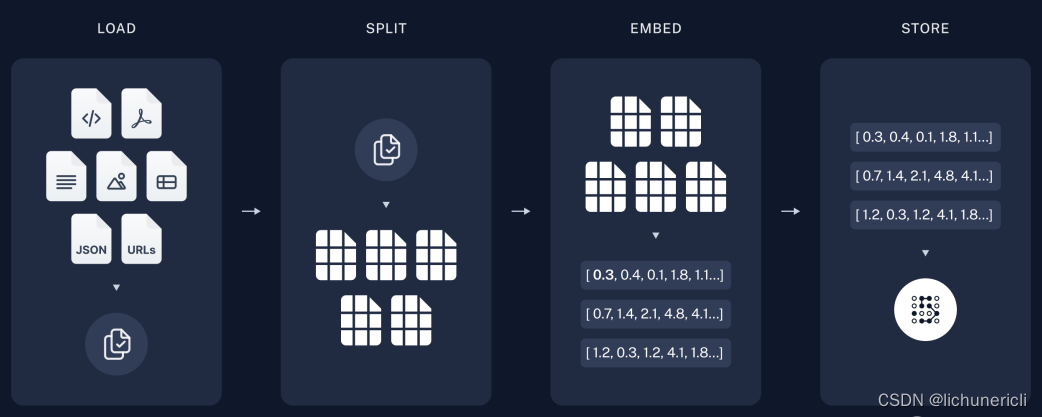 indexdiagram
indexdiagram
检索与生成[14]
- 检索:根据用户输入,使用Retriever[15]从存储中检索相关的拆分。
- 生成:使用包含问题和检索数据的提示,ChatModel[16]?/?LLM[17]生成答案。
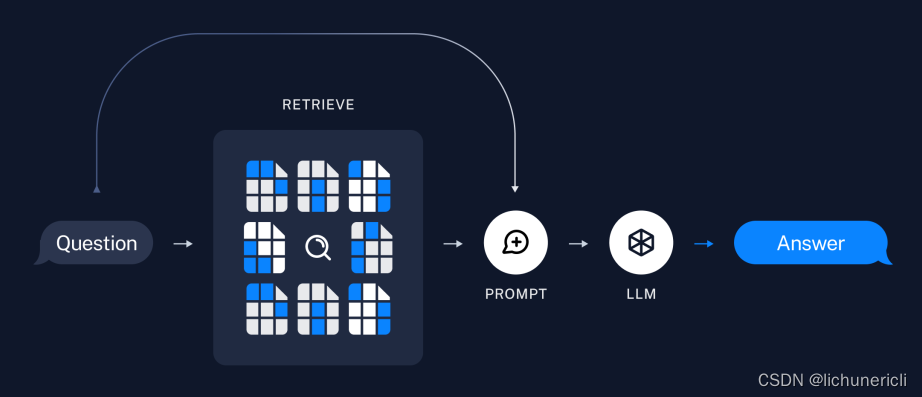 检索示意图
检索示意图
安装?[18]
依赖?[19]
我们将在这个教程中使用一个OpenAI聊天模型,嵌入和Chroma向量存储,但是这里展示的所有内容也适用于任何ChatModel[20]或LLM[21],?Embeddings[22],?以及?VectorStore[23]?或?Retriever[24]。
我们将使用以下软件包:
!pip?install?-U?langchain?openai?chromadb?langchainhub?bs4我们需要设置环境变量OPENAI_API_KEY,可以直接设置或从.env文件中加载,例如:
import?getpass
import?os
os.environ["OPENAI_API_KEY"]?=?getpass.getpass()#?import?dotenv#?dotenv.load_dotenv()LangSmith[25]
许多使用LangChain构建的应用程序将包含多个步骤,并进行多次LLM调用。随着这些应用程序变得越来越复杂,能够检查链条或代理内部具体发生了什么变得至关重要。最好的方法是使用LangSmith[26]。请注意,LangSmith并非必需,但它非常有帮助。如果您想要使用LangSmith,在上面的链接上注册后,请确保设置您的环境变量以开始记录追踪信息:文本:
os.environ["LANGCHAIN_TRACING_V2"]?="true"
os.environ?["LANGCHAIN_API_KEY"]?=?getpass.getpass()Quickstart
假设我们想要在Lilian?Weng的博客文章“?LLM?Powered?Autonomous?Agents”上构建一个QA应用程序。我们可以用大约20行代码创建一个简单的流水线:
import?bs4
from?langchain?import?hub
from?langchain.chat_models?import?ChatOpenAI
from?langchain.document_loaders?import?WebBaseLoader
from?langchain.embeddings?import?OpenAIEmbeddings
from?langchain.schema?import?StrOutputParser
from?langchain.schema.runnable?import?RunnablePassthrough
from?langchain.text_splitter?import?RecursiveCharacterTextSplitter
from?langchain.vectorstores?import?Chromaloader?=?WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),?bs_kwargs=dict(parse_only=bs4.SoupStrainer(class_=("post-content",?"post-title",?"post-header"))))
docs?=?loader.load()
text_splitter?=?RecursiveCharacterTextSplitter(chunk_size=1000,?chunk_overlap=200)
splits?=?text_splitter.split_documents(docs)
vectorstore?=?Chroma.from_documents(documents=splits,?embedding=OpenAIEmbeddings())
retriever?=?vectorstore.as_retriever()
prompt?=?hub.pull("rlm/rag-prompt")
llm?=?ChatOpenAI(model_name="gpt-3.5-turbo",?temperature=0)
def?format_docs(docs):
????return?"\n\n".join(doc.page_content?for?doc?in?docs)
rag_chain?=?({"context":?retriever?|?format_docs,?"question":?RunnablePassthrough()}?|?prompt?|?llm?|?StrOutputParser())rag_chain.invoke('什么是任务分解?')
任务分解是一种将复杂任务分解为更小更简单步骤的技术。可以通过提示技术,如思维链或思维树,或者使用特定任务指令或人类输入来完成。任务分解帮助代理计划并更有效地管理复杂任务。
#?cleanupvectorstore.delete_collection()
查看?LANGSMITH?trace[27]
详细步骤
点击上面的链接逐步查看以上代码,以便真正理解代码的执行过程。
步骤1.?加载
点击上面的链接查看步骤1.?加载。我们首先需要加载博客文章内容。我们可以使用DocumentLoader来实现,DocumentLoader是从源加载数据作为Documents的对象。Document是一个具有page_content(str)和metadata(dict)属性的对象。在这种情况下,我们将使用“WebBaseLoader”,它使用“urllib”和“BeautifulSoup”来加载和解析传入的网址,每个网址返回一个“Document”。我们可以通过将参数传递给“BeautifulSoup”解析器上的“bs_kwargs”来自定义html->文本解析(请参阅BeautifulSoup文档[28])。在这种情况下,只有带有“post-content”,“post-title”或“post-header”类的HTML标签是相关的,因此我们将删除所有其他标签。
from?langchain.document_loaders?import?WebBaseLoader
loader?=?WebBaseLoader(web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),?bs_kwargs={"parse_only":?bs4.SoupStrainer(class_=("post-content",?"post-title",?"post-header"))})
docs?=?loader.load()len(docs[0].page_content)42824print(docs[0].page_content[:500])以?LLM(大型语言模型)作为核心控制器建立代理是一个很酷的概念。AutoGPT、GPT-Engineer?和?BabyAGI?等几个概念验证演示是令人鼓舞的示例。LLM?的潜力超越了生成写作、故事、文章和程序的能力;它可以被视为一个强大的通用问题解决器。
更深入[29]
DocumentLoader:从源加载数据作为Documents的对象。-?文档[30]:有关如何使用DocumentLoader的进一步文档。-?集成[31]:查找与您的用例相关的DocumentLoader集成(超过160个)。
步骤2.拆分
我们加载的文档超过42k个字符长度。这太长了,无法适应许多模型的上下文窗口。即使对于那些可以适应完整帖子的模型,根据经验,模型在非常长的提示中很难找到相关的上下文。
因此,我们将拆分“文档”以便进行嵌入和向量存储。这样,我们可以在运行时只检索出博客文章中最相关的部分。在这种情况下,我们将把我们的文档分成每块1000个字符,并且每块之间有200个字符的重叠。这种重叠有助于减轻将一句话与与之相关的重要上下文分开的可能性。我们使用“RecursiveCharacterTextSplitter”来分割文档,它将(递归地)使用常见的分隔符(如换行符)来分割文档,直到每个块达到适当的大小。
from?langchain.text_splitter?import?RecursiveCharacterTextSplitter
text_splitter?=?RecursiveCharacterTextSplitter(chunk_size=1000,?chunk_overlap=200,?add_start_index=True)
all_splits?=?text_splitter.split_documents(docs)len(all_splits)66len(all_splits[0].page_content)969all_splits[10].metadata{'source':?'https://lilianweng.github.io/posts/2023-06-23-agent/',?'start_index':?7056}更深入了解[32]
“DocumentSplitter”:将`Document`列表分成较小块的对象。是`DocumentTransformer`的子类。-?探索“上下文感知分割器”,它保持原始`Document`中每个分割的位置(“上下文”):-?[Markdown文件](https://python.langchain.com/docs/use_cases/question_answering/document-context-aware-QA)-?[代码(py或js)](https://python.langchain.com/docs/use_cases/question_answering/docs/integrations/document_loaders/source_code)-?[科学论文](https://python.langchain.com/docs/integrations/document_loaders/grobid)
`DocumentTransformer`:一个在`Document`列表上执行转换的对象。-?[文档](https://python.langchain.com/docs/modules/data_connection/document_transformers/):关于如何使用`DocumentTransformer`的进一步文档?-?[集成](https://python.langchain.com/docs/integrations/document_transformers/)
##?第三步。存储[](https://python.langchain.com/docs/use_cases/question_answering/#step-3.-store?"直达第三步。存储")
现在我们已经在内存中有了66个文本块,我们需要将它们存储和索引,以便在我们的RAG应用程序中稍后进行搜索。这样做的最常见方式是嵌入每个文档分割的内容,并将这些嵌入上传到向量存储器中。
然后,当我们想要在我们的分割数据中进行搜索时,我们将搜索查询也进行嵌入,并执行某种“相似性”搜索来识别与我们查询嵌入最相似的存储分割。最简单的相似性度量是余弦相似度?-?我们测量每对嵌入之间的夹角的余弦值(它们只是非常高维的向量)。
我们可以使用?`Chroma`?向量存储和?`OpenAIEmbeddings`?模型的单个命令来嵌入和存储所有的文档分割。语句:
from?langchain.embeddings?import?OpenAIEmbeddingsfrom?langchain.vectorstores?import?Chromavectorstore?=?Chroma.from_documents(documents=all_splits,?embedding=OpenAIEmbeddings())深入了解[33]
“Embeddings”:?是一个文本嵌入模型的封装器,用于将文本转换为嵌入。-?文档[34]:?更多关于接口的文档。-?集成[35]:?浏览30多个文本嵌入集成。“VectorStore”:封装了一个向量数据库,用于存储和查询嵌入向量。-?文档[36]:有关接口的进一步文档。-?集成[37]:浏览超过40个“VectorStore”集成。这完成了管道的索引部分。在这一点上,我们拥有一个可查询的向量存储,其中包含我们博客文章的块内容。给定一个用户问题,理想情况下,我们应该能够返回回答问题的博客文章摘录:
步骤3.?检索[38]
现在让我们来编写实际的应用逻辑。我们希望创建一个简单的应用程序,用户可以提问,搜索与问题相关的文档,将获取的文档和初始问题传递给模型,最后返回一个答案。
LangChain定义了一个“Retriever”接口,它封装了一个索引,可以根据字符串查询返回相关文档。所有的检索器都实现了一个公共方法“get_relevant_documents()”(以及它的异步变体“aget_relevant_documents()”)。最常见的Retriever类型是VectorStoreRetriever,它使用向量存储的相似度搜索能力来进行检索。任何VectorStore都可以很容易地转化为Retriever:
retriever?=?vectorstore.as_retriever(search_type="similarity",?search_kwargs={"k":?6})retrieved_docs?=?retriever.get_relevant_documents("What?are?the?approaches?to?Task?Decomposition?")len(retrieved_docs)6print(retrieved_docs[0].page_content)思维树(Yao等人,2023)通过在每一步探索多种推理可能性来扩展CoT。它首先将问题分解为多个思考步骤,并在每个步骤中生成多个思考,从而创建一个树结构。搜索过程可以是宽度优先搜索(BFS)或深度优先搜索(DFS),每个状态通过分类器(通过提示)或多数投票来评估。任务分解可以通过以下方式完成:(1)使用类似“XYZ步骤。\n1.”、“实现XYZ的子目标是什么?”的简单提示来使用LLM,(2)使用特定任务的说明,例如“写一个故事大纲。”来写小说,或(3)使用人类输入。”
深入了解
常用于检索的矢量存储,但还有许多其他检索方式。“Retriever”:一个根据文本查询返回“文档”对象的对象-?文档[39]:有关接口和内置检索技术的进一步文档。其中一些包括:-?MultiQueryRetriever 生成输入问题的变体[40]?以提高检索命中率。-?MultiVectorRetriever(如下图所示)生成嵌入的变体[41],也是为了提高检索命中率。-?最大边际收益选择已检索文档中的相关性和多样性,以避免传入重复上下文。-?在使用向量存储的检索过程中,可以使用元数据筛选器[42]对文档进行筛选。-?整合[43]:与检索服务的整合。
步骤4.生成
让我们将所有内容汇总到一个链条中,该链条接受一个问题,检索相关文档,构建提示,将其传递给一个模型,并解析输出。
我们将使用gpt-3.5-turbo的OpenAI聊天模型,但可以替换为任何LangChain的LLM或ChatModel。
from?langchain.chat_models?import?ChatOpenAI
llm?=?ChatOpenAI(model_name="gpt-3.5-turbo",?temperature=0)我们将使用一个已经加入LangChain提示中心的RAG提示(链接在这里[44])。
from?langchain?import?hub
prompt?=?hub.pull("rlm/rag-prompt")print(prompt.invoke({"context":?"填充内容",?"question":?"填充问题"}).to_string())Human:?You?are?an?assistant?for?question-answering?tasks.?Use?the?following?pieces?of?retrieved?context?to?answer?the?question.?If?you?don't?know?the?answer,?just?say?that?you?don't?know.?Use?three?sentences?maximum?and?keep?the?answer?concise.Question:?filler?question?Context:?filler?context?Answer:
你是一个用于问答任务的助手。使用以下检索到的背景内容来回答问题。如果你不知道答案,只需说你不知道。答案限定在三个句子内,并保持简洁。问题:填充问题。背景:填充背景。答案:我们将使用LCEL?Runnable[45]协议来定义链,这使得我们可以以透明的方式将组件和函数进行连接,可以自动在LangSmith中跟踪我们的链,并且可以轻松实现流式、异步和批处理调用。
from?langchain.schema?import?StrOutputParser
from?langchain.schema.runnable?import?RunnablePassthrough
def?format_docs(docs):
????return?"\n\n".join(doc.page_content?for?doc?in?docs)
rag_chain?=?(
????{"context":?retriever?|?format_docs,?"question":?RunnablePassthrough()}
????|?prompt
????|?llm
????|?StrOutputParser()
)for?chunk?in?rag_chain.stream("What?is?Task?Decomposition?"):
????print(chunk,?end="",?flush=True)任务分解是一种将复杂任务拆分为较小、较简单步骤的技术。可以通过思维链?(CoT)?或思维树等方法来进行,其中涉及将任务划分为可管理的子任务,并在每个步骤中探索多种推理可能性。任务分解可以通过?AI?模型的提示、任务特定的指令或人类输入来完成。
请查看?LANGSMITH?追踪[46]。
深入了解[47]
选择LLMs[48]
ChatModel:?使用LLM作为支持的聊天模型包装器。接受一系列消息并返回一条消息。-?文档[49]?-?集成[50]:?探索超过25个ChatModel的集成。"LLM:一个输入字符串并返回字符串的文本输入-文本输出LLM。-?文档[51]?-?集成[52]:?浏览超过75个LLM的集成。
查看使用本地运行模型的RAG指南这里[53]。
选择LLMs[54]
如上所示,我们可以从提示中心加载提示(例如,此RAG提示[55])。该提示也可以很容易地进行自定义:
from?langchain.prompts?import?PromptTemplate
template?=?"""使用以下背景信息来回答最后的问题。如果你不知道答案,直接说不知道,不要编造答案。答案要尽量简洁,最多三句话。最后要说“谢谢你的提问!"。{context}问题:{question}有帮助的回答:"""
rag_prompt_custom?=?PromptTemplate.from_template(template)
rag_chain?=?(
????{"context":?retriever?|?格式化文档,?"question":?RunnablePassthrough()}
????|?rag_prompt_custom
????|?llm
????|?StrOutputParser()
)
rag_chain.invoke("什么是任务分解?")任务分解是将复杂任务分解为更小、更简单的步骤的过程。可以通过思维链(CoT)或思维树等技术来进行分解,这些技术涉及将问题分为多个思维步骤,并为每个步骤生成多个思考结果。任务分解有助于提高模型性能并理解模型的思考过程。谢谢您的提问!请查看LangSmith[56]。添加来源 [57]
使用LCEL很容易从检索到的文档中返回文档或特定的源数据:
from?operator?import?itemgetter
from?langchain.schema.runnable?import?RunnableParallel
rag_chain_from_docs?=?(
????{
????????"context":?lambda?input:?format_docs(input["documents"]),
????????"question":?itemgetter("question"),
????}
????|?rag_prompt_custom
????|?llm
????|?StrOutputParser()
)
rag_chain_with_source?=?RunnableParallel(
????{"documents":?retriever,?"question":?RunnablePassthrough()}
)?|?{
????"documents":?lambda?input:?[doc.metadata?for?doc?in?input["documents"]],
????"answer":?rag_chain_from_docs,
}
rag_chain_with_source.invoke("What?is?Task?Decomposition")任务分解是一种将复杂任务分解为较小和简单步骤的技术。它涉及将大任务转化为多个可管理的任务,从而实现更系统和有组织的问题解决方法。谢谢您的提问!考查一下?LangSmith?trace[58]。添加记忆[59]
假设我们想创建一个记住过去用户输入的有状态应用程序。我们需要做两件主要的事情来支持这一点。1.?在我们的链中添加一个消息占位符,允许我们传入历史消息。2.?添加一个链,获取最新的用户查询,并将其在聊天历史上下文中重构成一个可以传递给我们的检索器的独立问题。
让我们从第2步开始。我们可以构建一个“简化问题”的链,大致如下:
from?langchain.prompts?import?PromptTemplate,MessagesPlaceholder
condense_q_system_prompt?=?"""给定聊天记录和最新的用户问题,这个问题可能参考了聊天记录,要求提供一个可以独立理解的问题,不要回答问题,只要有必要就重新表述并返回原样。"""
condense_q_prompt?=?ChatPromptTemplate.from_messages(
????[
????????("system",?condense_q_system_prompt),
????????MessagesPlaceholder(variable_name="chat_history"),
????????("human",?"{question}"),
????]
)
condense_q_chain?=?condense_q_prompt?|?llm?|?StrOutputParser()from?langchain.schema.messages?import?AIMessage,HumanMessage
condense_q_chain.invoke(
????{
????????"chat_history":?[
????????????HumanMessage(content="LLM是什么意思?"),
????????????AIMessage(content="大型语言模型"),
????????],
????????"question":?"大型在语言模型中是什么意思?",
????}
)condense_q_chain.invoke({
????"chat_history":?[
????????HumanMessage(content="LLM?是什么的缩写?"),
????????AIMessage(content="大型语言模型"),
????],
????"question":?"transformers?是如何工作的",
})'转换模型是如何运作的?'现在我们可以构建完整的问答链条。请注意,我们添加了一些路由功能,以便只有在聊天历史不为空时才运行“缩减问题链条”。
qa_system_prompt?=?"""您是一个用于问答任务的助手。请使用以下检索到的上下文片段来回答问题。如果您不知道答案,只需说您不知道即可。最多使用三个句子,并且保持回答简洁。\n{context}"""
qa_prompt?=?ChatPromptTemplate.from_messages(
????[
????????("system",?qa_system_prompt),
????????MessagesPlaceholder(variable_name="chat_history"),
????????("human",?"{question}"),
????]
)
def?condense_question(input:?dict):
????if?input.get("chat_history"):
????????return?condense_q_chain
????else:
????????return?input["question"]
rag_chain?=?(
????RunnablePassthrough.assign(context=condense_question?|?retriever?|?format_docs)
????|?qa_prompt
????|?llm
)
chat_history?=?[]
question?=?"什么是任务分解?"
ai_msg?=?rag_chain.invoke({"question":?question,?"chat_history":?chat_history})
chat_history.extend([HumanMessage(content=question),?ai_msg])
second_question?=?"常见的任务分解方法有哪些?"
rag_chain.invoke({"question":?second_question,?"chat_history":?chat_history})常见的任务分解方式包括:
- 使用思路链(CoT):CoT是一种提示技术,它指导模型“逐步思考”,将复杂的任务分解为更小更简单的步骤。它利用更多的测试时间计算,并揭示了模型的思考过程。
- 使用语言模型(LLM)进行提示:可以使用语言模型(LLM)以简单的指令提示模型,例如“XYZ的步骤”或“实现XYZ的子目标是什么?”这使得模型能够生成一系列的子任务或思考步骤。
- 任务特定的指导:对于某些任务,可以提供任务特定的指导,以引导模型进行任务分解。例如,对于写一本小说的任务,可以给出“写故事纲要”的指导,以将任务分解成可管理的步骤。
- 人类输入:在某些情况下,可以使用人类输入来协助进行任务分解。人类可以提供他们的专业知识和知识来识别和分解复杂的任务成较小的子任务。
请查看以下内容 LANGSMITH?跟踪[60]在这里,我们介绍了如何添加链逻辑以合并历史输出。但是,我们如何实际存储和检索不同会话的历史输出呢?要了解详情,请查看?LCEL?如何添加消息历史记录(内存)[61]?页面。
步骤5[62]
在短时间内,我们涵盖了大量的内容。在上述各个部分中,还有许多细微之处、特点、集成等待探索。除了上述提到的来源外,好的下一步包括:
?在Retrievers[63]部分深入研究更高级的检索技术。?了解LangChain的Indexing?API[64],该API可帮助重复同步数据源和向量存储,避免冗余计算和存储。?探索RAG的LangChain模板[65],这些模板是易于使用LangServe[66]部署的参考应用程序。?了解如何使用LangSmith评估RAG应用程序的方法,可参考在LangSmith上评估RAG应用程序[67]。
References
[1]?:?https://colab.research.google.com/github/langchain-ai/langchain/blob/master/docs/docs/use_cases/question_answering/index.ipynb
[2]?跳转至概述:?https://python.langchain.com/docs/use_cases/question_answering/#overview
[3]?跳转至什么是RAG?:?https://python.langchain.com/docs/use_cases/question_answering/#what-is-rag
[4]?直接链接到这个指南的内容:?https://python.langchain.com/docs/use_cases/question_answering/#whats-in-this-guide
[5]?LLM?Powered?Autonomous?Agents:?https://lilianweng.github.io/posts/2023-06-23-agent/
[6]?对结构化数据进行?QA:?https://python.langchain.com/docs/use_cases/qa_structured/sql
[7]?对代码进行?QA:?https://python.langchain.com/docs/use_cases/question_answering/code_understanding
[8]?直接链接到架构:?https://python.langchain.com/docs/use_cases/question_answering/#architecture
[9]?直达索引化:?https://python.langchain.com/docs/use_cases/question_answering/#indexing
[10]?DocumentLoaders:?https://python.langchain.com/docs/modules/data_connection/document_loaders/
[11]?文本分割器:?https://python.langchain.com/docs/modules/data_connection/document_transformers/
[12]?VectorStore:?https://python.langchain.com/docs/modules/data_connection/vectorstores/
[13]?Embeddings:?https://python.langchain.com/docs/modules/data_connection/text_embedding/
[14]?直接链接到检索与生成:?https://python.langchain.com/docs/use_cases/question_answering/#retrieval-and-generation
[15]?Retriever:?https://python.langchain.com/docs/modules/data_connection/retrievers/
[16]?ChatModel:?https://python.langchain.com/docs/modules/model_io/chat_models
[17]?LLM:?https://python.langchain.com/docs/modules/model_io/llms/
[18]?安装的直接链接:?https://python.langchain.com/docs/use_cases/question_answering/#setup
[19]?依赖的直接链接:?https://python.langchain.com/docs/use_cases/question_answering/#dependencies
[20]?ChatModel:?https://python.langchain.com/docs/integrations/chat/
[21]?LLM:?https://python.langchain.com/docs/integrations/llms/
[22]?Embeddings:?https://python.langchain.com/docs/integrations/text_embedding/
[23]?VectorStore:?https://python.langchain.com/docs/integrations/vectorstores/
[24]?Retriever:?https://python.langchain.com/docs/integrations/retrievers
[25]?直接链接到LangSmith:?https://python.langchain.com/docs/use_cases/question_answering/#langsmith
[26]?LangSmith:?https://smith.langchain.com/
[27]?LANGSMITH?trace:?[LangSmith](https://smith.langchain.com/public/1c6ca97e-445b-4d00-84b4-c7befcbc59fe/r)
[28]?BeautifulSoup文档:?https://beautiful-soup-4.readthedocs.io/en/latest/#beautifulsoup
[29]?直达链接至更深入:?https://python.langchain.com/docs/use_cases/question_answering/#go-deeper
[30]?文档:?https://python.langchain.com/docs/modules/data_connection/document_loaders/
[31]?集成:?https://python.langchain.com/docs/integrations/document_loaders/
[32]?直达更深入了解:?https://python.langchain.com/docs/use_cases/question_answering/#go-deeper-1
[33]?直达深入了解:?https://python.langchain.com/docs/use_cases/question_answering/#go-deeper-2
[34]?文档:?https://python.langchain.com/docs/modules/data_connection/text_embedding
[35]?集成:?https://python.langchain.com/docs/integrations/text_embedding/
[36]?文档:?https://python.langchain.com/docs/modules/data_connection/vectorstores/
[37]?集成:?https://python.langchain.com/docs/integrations/vectorstores/
[38]?直接链接到步骤?4.?检索:?https://python.langchain.com/docs/use_cases/question_answering/#step-4.-retrieve
[39]?文档:?https://python.langchain.com/docs/modules/data_connection/retrievers/
[40]?生成输入问题的变体:?https://python.langchain.com/docs/modules/data_connection/retrievers/MultiQueryRetriever
[41]?嵌入的变体:?https://python.langchain.com/docs/modules/data_connection/retrievers/multi_vector
[42] 元数据筛选器:?https://python.langchain.com/docs/use_cases/question_answering/document-context-aware-QA
[43]?整合:?https://python.langchain.com/docs/integrations/retrievers/
[44]?链接在这里:?https://smith.langchain.com/hub/rlm/rag-prompt
[45]?LCEL?Runnable:?https://python.langchain.com/docs/expression_language/
[46]?LANGSMITH?追踪:?https://smith.langchain.com/public/1799e8db-8a6d-4eb2-84d5-46e8d7d5a99b/r
[47]?Go?deeper的直接链接:?https://python.langchain.com/docs/use_cases/question_answering/#go-deeper-4
[48]?选择LLMs的直接链接:?https://python.langchain.com/docs/use_cases/question_answering/#choosing-llms
[49]?文档:?https://python.langchain.com/docs/modules/model_io/chat/
[50]?集成:?https://python.langchain.com/docs/integrations/chat/
[51]?文档:?https://python.langchain.com/docs/modules/model_io/llms
[52]?集成:?https://python.langchain.com/docs/integrations/llms
[53]?这里:?https://python.langchain.com/docs/use_cases/question_answering/local_retrieval_qa
[54]?自定义提示的直接链接:?https://python.langchain.com/docs/use_cases/question_answering/#customizing-the-prompt
[55]?此RAG提示:?https://smith.langchain.com/hub/rlm/rag-prompt
[56]?LangSmith:?https://smith.langchain.com/public/da23c4d8-3b33-47fd-84df-a3a582eedf84/r
[57]?直接链接到添加来源:?https://python.langchain.com/docs/use_cases/question_answering/#adding-sources
[58]?LangSmith?trace:?https://smith.langchain.com/public/007d7e01-cb62-4a84-8b71-b24767f953ee/r
[59]?添加记忆的直接链接:?https://python.langchain.com/docs/use_cases/question_answering/#adding-memory
[60]?LANGSMITH?跟踪:?https://smith.langchain.com/public/b3001782-bb30-476a-886b-12da17ec258f/r
[61]?如何添加消息历史记录(内存):?https://python.langchain.com/docs/expression_language/how_to/message_history
[62]?直达下一步骤链接:?https://python.langchain.com/docs/use_cases/question_answering/#next-steps
[63]?Retrievers:?https://python.langchain.com/docs/modules/data_connection/retrievers/
[64]?Indexing?API:?https://python.langchain.com/docs/modules/data_connection/indexing
[65]?LangChain模板:?https://python.langchain.com/docs/templates/#-advanced-retrieval
[66]?LangServe:?https://python.langchain.com/docs/langserve
[67]?在LangSmith上评估RAG应用程序:?https://github.com/langchain-ai/langsmith-cookbook/blob/main/testing-examples/qa-correctness/qa-correctness.ipynb
复制搜一搜分享收藏划线
人划线
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- HNU-数据挖掘-实验2-数据降维与可视化
- 【算法每日一练]-图论(保姆级教程篇14 )#会议(模板题) #医院设置 #虫洞 #无序字母对 #旅行计划 #最优贸易
- mysql修复VIEWRESIDENTHIST 数据
- openpose环境搭建
- 初识Java并发,一问读懂Java并发知识文集(4)
- 仓储1、10、11、15代电子标签接口文档-V2.0
- 项目整合管理-8.2制定项目管理计划
- 生成小程序页面二维码的PHP代码
- Docker中swarm管理工具
- .net core 6 集成和使用 mongodb