【AIGC】2023年生成式AI发展综述

??2023年是人工智能内容生成(AIGC)技术飞速发展的一年。从年初ChatGPT一炮打响,大家纷纷加入到大模型研究之中。期间 Midjourney和Stable Diffusion AI绘画技术持续火热,基于AIGC类的应用也如雨后春笋般遍地开花 。
?? 人工智能生成内容 (AIGC) 标志着一个变革时代的到来,它 利用机器学习以有限的人力输入来创建或更改内容。这一趋势跨越了各种媒体形式——文本、图像、电影和音频等,在媒体制作、分发和接收方面引入了新的创新方式 。AIGC 不仅仅局限于内容自动化;它还增强了人类的创造力,提供了一系列内容定制的机会。
??本文将从以下六个部分简要回顾20203年AIGC人工智能技术发展情况。

一、文本生成 & 智能问答
?? AI文本生成技术,是根据用户需求生成特定任务下的文案,包括 营销文案、营销邮件、文章撰写、润色、翻译、校对、总结、编辑、代码生成、角色扮演、工具助手 等等,大大提升文案创作或编辑人员的工作效率。相比于普通聊天机器人而言,AI文本生成内容更加专业,很多时候可以代替人工完成一些初步工作。
??AI文本生成技术的典型代表是OpenAI的ChatGPT,其可谓是从年初火到年尾,目前热度仍然不减。其技术和使用效果也在不断进行迭代更新。其技术基础年初时为GPT3,后陆续更新推出GPT3.5、GPT4和GPTs(基于ChatGPT的定制化场景应用),GPT4.5则推迟到了今年。其API上下文的长度也由4K扩展到16K、32K、64K。微软也于2月8日凌晨推出了由OpenAI提供技术支持的新版搜索引擎必应和Edge浏览器,整合了ChatGPT的最新技术(即GPT-4),并且接入到Newbing当中。

??Anthropic公司随后推出 Claude,并且一直被称为“ChatGPT唯一的竞争对手”。Anthropic 的创始团队成员,大多为 OpenAI 的早期及核心员工,深度参与过OpenAI的多项课题,比如GPT-3、神经网络里的多模态神经元、引入人类偏好的强化学习等。今年11月22日发布的Claude 2.1支持20万个Token,不仅是Claude 2.0的两倍,也已超越OpenAI GPT-4 Turbo的12.8万个Token,相当于15万个文本或是500页的文件。
??5月11日 Google I/O 开发者大会发布大语言模型 PaLM2(Pathways Language Model 2),称在部分任务上超越 GPT-4。作为人工智能界的带头大哥,Google在该领域的风头今年一直没能超过OpenAI。12月6日,谷歌CEO桑达尔?皮查伊官宣Gemini 1.0版正式上线。据说Gemini有万亿参数,训练动用的算力是GPT-4的五倍。另外,在这年底冲刺阶段,微软于12月13日发布27亿参数的语言模型Phi-2,据称可与规模大25倍的大模型相媲美,该模型目前已加入Azure AI Studio。
?? LLaMA(Large Language Model Meta AI),由 Meta AI 发布的一个开源且高效的大型基础语言模型,共有 7B、13B、33B、65B(650 亿)四种版本。其数据集来源都是公开数据集,无任何定制数据集,保证了其工作与开源兼容和可复现,整个训练数据集在 token 化之后大约包含 1.4T 的 token。LLaMA因为源码泄露引来了大量开发者的关注,早期大模型研发工作有很大一部分都是基于LLaMA进行微调的。例如LLaMA(羊驼)、Vicuna(小羊驼)等。
?? 国内AI文本生成大模型主要有清华智谱AI的ChatGLM、百度的文言一心、科大讯飞的星火认知大模型、百川大模型、阿里的通义千问大模型 等。据不完全统计,今年1-7月国内共发布了64个大模型,截至目前叫得出名字的国产大模型已接近200家。其中,ChatGLM是国内最早开源的模型之一,早在今年3月份就已经发布,从ChatGLM发展到ChatGLM2和ChatGLM3。相关的开源生态也做得非常完善,例如微调、C++加速、模型量化以及移动端部署等等。
??ChatGPT类大模型,均支持分布式和强化学习训练。类似Chat GLM等开源大模型也提供了微调方式。另外,OpenAI也提供了模型微调API接口,目前支持到GPT3.5。模型训练微调和训练的应用之一是能够得到自定义知识库,根据知识库进行问答。目前,微调自己的知识库,主要有两种方案:
1.对知识库进行向量化,根据用户问题来检索知识库,然后将命中的知识库和用户问题合并到prompt提示词中,然后输入到大模型。这种方法比较方便,但是每次输入到模型的上下文内容会很长,而且模型运行或者API调用成本会随着内容增加而增加。该方法虽然省去了模型训练成本,但是调用成本会增加。
2.根据已有知识库训练或微调大模型,让模型本身掌握当前知识。那么模型使用时只需要输入问题或者任务内容,无需将知识库加入到输入。这种做法会降低调用成本,但需要增加模型训练成本。第二种方法应该更加有效,但是难度会偏大,包括数据制作和模型训练等。
二、AI绘画
??2022年,Midjourney的一幅AI绘画《太空歌剧院》诞生让AIGC绘画变得流行起来。与此同时,Stability.ai和Jasper.ai(元宇宙和数字媒体工具开发商)在当前市场环境下完成了大规模融资,估值分别为10亿美元和15亿美元。这两件事的叠加起到了催化剂的作用,点燃了市场对AIGC的热情。AI绘画实际上从OpenAI的DALLE 2开始就在AI圈流行起来,但真正流行是从开源版本的出现开始的。
AI绘画有着大量应用场景:绘画软件集成(PhotoShop等)、办公软件(Office、WPS等)、设计工作室、游戏角色设计、室内设计、建筑设计等。

??最早出现在大众面前的Disco Diffusion(Midjourney的前身)主要被插画师和AI工具爱好者使用。他们的目标是创建一个开源和共创的模型,最终将人工智能生成的图像推向普通人。Stability AI 的模型Stable Diffusion可以理解为DALLE 2的开源版本,用户可以基于开源模型创建自己的定制模型。这彻底降低了AI生成图像的门槛。日活跃用户已超过1000万,Stable Diffusion的开源也极大促进了AI绘画市场发展。

??
??其原理主要使用了概率扩散模型DDPM,如下图所示。详情请见博主的DALLE2解析博客。
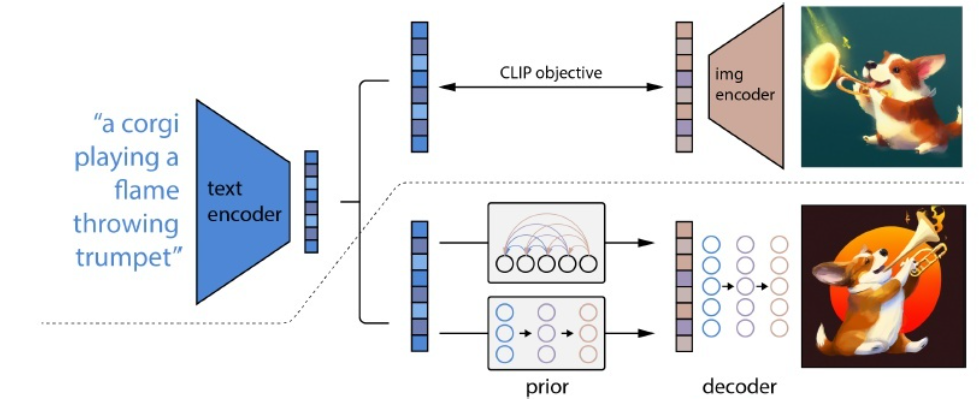
??今年2月份ControlNet 正式发布开源版本,它可以与Stable Diffusion结合实现可控的AI绘画设计,从而进一步推动了该方向上的发展。例如:AI室内装修设计、风格迁移设计样例。
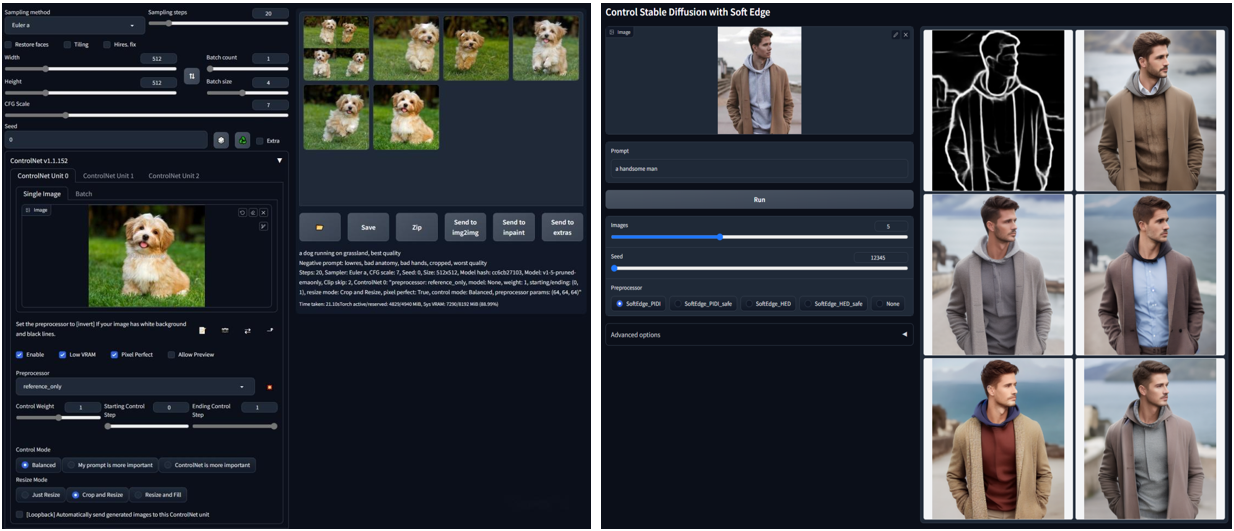
??7月初,Stable Diffusion发布了XL版及两个模型。目前ControlNet也已支持XL版Stable Diffusion。XL版本提升了绘画质量和分辨率(512提升到1024)。
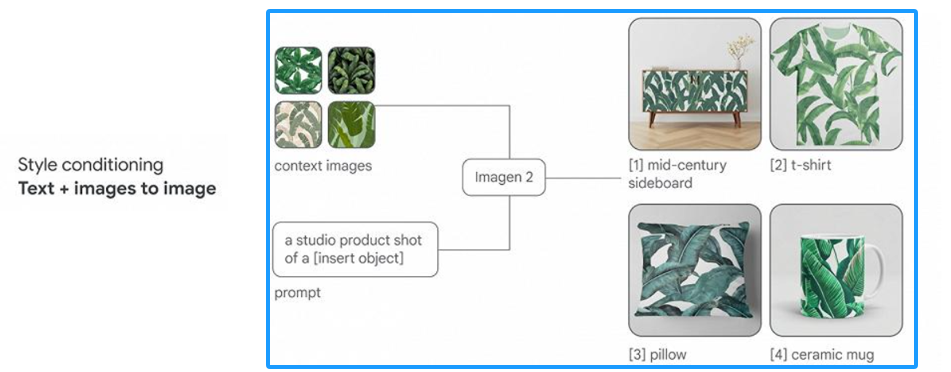
??相比SD,Midjourney和DALL并未开源,需要付费使用。从当前现状来看, Midjourney表现效果最佳 。Stable Diffusion灵活可控,开源模型和资料较多。DALL-E2发布较早,绘画效果一般。但今年9月份左右Dall-E3发布,并且集成到了ChatGPT之中,效果比较不错,生成的图片清晰度都有非常大的提升。目前,OpenAI也单独提供了DALL-E3的调用接口。12月13日, 谷歌Deepmind推出人工智能图像生成器Imagen 2 ,号称是DALL-E3的最强竞品。据介绍,Imagen 2可以生成迄今为止所有Google模型中质量最高、最逼真的图像,同时严格遵循用户提示。
??除了基于扩散模型之外,基于生成式对抗网络(GAN)的 DragGAN 在今年五月中旬也引起了广泛关注。它可实现运动监督和精确点跟踪,对像素进行精确控制,从而编辑动物、汽车、人类、风景等多种类别的姿态、形状、表情和布局。

三、音频生成
??随着AI文本生成和AI绘画生成在2023年爆火,AI音频生成技术也引起了巨大关注。该技术不仅能简化音乐创作流程,更可以提升音乐创作的深度和广度,为创作者和用户带来更多可能性和选择。受限于热度和成熟度,仅诞生了为数不多的几个模型:
??今年1月份, 谷歌首次公开MusicLM模型 。MusicLM是一种以文本为条件的音频生成模型,其主要目标是生成高保真度的音乐。它采用层次化的序列到序列方法,可以生成几分钟长且一致的音乐片段。谷歌实验表明,MusicLM 在音频质量和对文本描述的遵守方面都优于以前的系统。现在,GitHub上已经开源了Pytorch版本的MusicLM,以下是生成的demo。
https://google-research.github.io/seanet/musiclm/examples/audio_samples/rich-descriptions/arcade/audio.wav
??今年8月2日,Meta facebookresearch 正式开源了AudioCraft 的AI音频和音乐生成工具。该工具声称可以直接从文本描述和参考音乐生成高质量的音频和音乐。AudioCraft包含MusicGen、AudioGen和EnCodec三个模型,分别实现音乐生成、音频生成和自定义音频模型构建。其效果可以直接在Hugging Face网页上体验,或者根据GitHub上的开源程序部署到本地进行体验。
https://dl.fbaipublicfiles.com/audiocraft/webpage/public/assets/audios/musicgen_mono/sample_001.mp3
??同样在今年8月份,AudioLDM 2 论文和模型程序也开源了。它是一个基于文本生成音频的模型,能够快速生成高质量的音频,包括节奏、音效和基本对话。该模型引入了一种通用的音频表示法称为 “音频语言”(LOA)。在生成过程中,它使用GPT-2模型将任何模态转化为LOA,并使用以LOA为条件的潜在扩散模型进行自监督音频生成学习。论文中实验表明,在文本到音频、文本到音乐和文本到语音等主要基准上,与以前的方法相比,其性能达到了最新水平。
https://audioldm.github.io/audioldm2/demos/ttm_headline_nine_audio/A_catchy_trap_beat_with_EDM_Synthesizers_in_the_mix,_creating_a_unique_electronic_sound_with_ethereal_quality.flac
??以上模型,一般对提示词描述需要非常准确或者比较专业。这一点不如AI文本和AI绘画使用起来方便。另一方面,生成时间也会明显增加,通常需要几分钟之久,而AI文本可以采用流式方式实时输出,AI绘画一般也不到1分钟。其次,生成的内容强项在于乐器或英文相关,生成歌曲类或者中文内容比较困难。
四、视频生成
?? 网络时代,视频在流量吸引、内容传播、广告营销等方面展现出了强大的能力。随着底层技术不断拓展能力,AIGC的应用自然也从文本、图像发展到了视频领域。AIGC在视频编辑中的应用主要分为两类:
第1类:视频属性的编辑,如视频质量恢复、删除画面中特定主体、自动添加具体内容、自动美化、视频特效等。Runway公司从图片剪辑的角度切入视频剪辑;而Descript公司则从声音剪辑的角度切入视频剪辑。切入点不同,但目的都是为了提高内容创作者的工作效率,让他们更专注于创意的产生。
第2类是:视频自动编辑。与上面提到的生成不同,自动编辑的逻辑是寻找并合成符合条件的素材。从某种程度上来说,它是自动生成的一个过渡方案。目前,很多视频编辑或应用软件(如剪映)等都支持一键成片或根据文字脚本生成视频。更进一步的做法是,用户先根据AI文本或绘画设计出原始视频脚本或图片素材,然后导入视频生成软件完成视频创作。
?? 以视频生成头部公司Runway为例, Gen-2是Runway公司 最初于2023年3月推出,允许用户输入文本提示生成四秒长视频。8月,该公司添加了一个选项,可以将 Gen-2 中人工智能生成的视频延长至 18 秒。9月,Runway 进一步更新 Gen-2,推出了统称为“导演模式”的新功能,允许用户在 Runway AI 生成的视频中选择“摄像机”运动的方向和强度/速度。11月,Runway 宣布发布 Gen-2 更新,为视频结果的保真度和一致性带来重大改进。Runway在12月12日晚间宣布,他们目前的Gen-2等视频生成系统可以视为早期通用世界模型的一种体现,对于物理和运动有着一定程度的理解,但在处理复杂的摄像机或物体运动等问题上仍存在挑战。为了构建更为通用的世界模型,Runway正在进行多项公开研究,其中包括生成环境地图、在环境中的导航和互动、捕捉世界和居民的动态,以及建立更逼真的人类行为模型等方面的研究。
?? 以下是demo:

??、在ChatGPT刷屏之际,谷歌AI推出了Phenaki 。只需提供一段提示词,这个文本转视频(Text-to-Video)模型就能生成长达两分钟的视频。今年10月份,Github上也开源了Pytorch版本的Phenaki模型。

?? 李飞飞携斯坦福联袂谷歌,12月12日正式推出了用于生成逼真视频的扩散模型W.A.L.T,据说效果媲美Gen-2比肩Pika。团队在已建立的视频(UCF-101 和 Kinetics-600)和图像(ImageNet)生成基准测试上实现了SOTA,而无需使用无分类器指导。而且其团队还训练了三个模型的级联,用于文本到视频的生成任务,包括一个基本的潜在视频扩散模型和两个视频超分辨率扩散模型,以每秒8帧的速度,生成512 x 896分辨率的视频。

?? 谷歌于12月20日提出的视频生成大模型上线,再次获得了人们的关注。这款名为VideoPoet 的大语言模型,被人们认为是革命性的zero-shot视频生成工具。它不仅能够以文字生成视频、以图像生成视频,还能根据需要进行风格迁移,根据文本指令的提示进行交互式视频编辑,可这能会给视频剪辑工作带来非常大的变革。

?? 视频生成比文本、绘画和语音更加复杂,所需要的算力也更大。因而,这种领域不太适合个人用户去对模型进行部署或优化。大部分用户主要是使用相关的软件工具和平台。可以看到,AI头部公司很少开源AI视频生成模型。
五、三维生成 & 数字人
提示:针对三维生成、稀疏重建,请关注作者的3D生成总结文章
5.1 通用三维生成
?? 相比2D内容的制作,3D内容的成本更高,制作周期更长。随着Diffusion模型和NeRF模型的发展,AI在3D内容生成的应用中迎来了快速发展。3D建模是一个近130亿的市场规模,3D场景的生成可以应用于游戏、VRAR和元宇宙。
?? 去年发布的3D生成模型有谷歌、加州大学伯克利分校的 DreamFusion、OpenAI的Point-E 、苹果的GAUDI和 英伟达的GET3D 等。GET3D目前已经开源。AI三维模型生成主要包括三种类型。一种是基于Text-to-3D,另一种是Image-to-3D;还有基于文本和输入点云来生成3D。其中,Point-E支持同时输入文本和点云。
?? 今年3月份英伟达发布了 Magic 3D ,属于文本到图像扩散模型。 它可以根据文本提示创建高质量的 3D 网格模型。Magic3D 采用两阶段过程:它使用低分辨率扩散创建粗略模型,然后系统使用稀疏 3D 哈希网格结构,并通过高效的可微渲染器进一步优化,以创建最终输出。Magic3D 可以在 40 分钟内创建高质量的 3D 网格模型。此外,该任务模型还有Shap-E 等。
??今年哥伦比亚大学5月发布的 zero 123 及其扩展版本 One-2-345,实现了单张图像的多视角生成、以及最终的mesh格式的输出。其利用了2D 扩散模型强大的多视角学习能力。

?? 2023 年8月香港中文大学、上海人工智能实验室、浙江大学发布的 PointLLM 旨在帮助PaLM和Llama等大型语言模型理解3D数据。人工智能研究人员可以在其数据集中充分利用点云(代表 3D 形状或对象的数据点)。
?? 8月底,字节跳动和加州大学圣地亚哥分校的研究人员开发了一种扩散模型 MVDream ,可以根据文本输入生成高质量的3D渲染。MVDream可以生成模型的多个视图,这些视图是几何一致的多视图图像。用户可使用 DreamBooth3D 等工具对该模型进行微调,以实现个性化3D生成。
?? 北大年底推出的DreamGaussian ,利用基于优化的通过分数蒸馏采样(SDS)进行的3D生成。

?? Scenario 是一家创建和设计游戏内 3D 资产的公司 。用户可以通过视频拍摄现实生活中的3D物体,然后在游戏中生成相应的模型。场景拥有大量游戏内3D资产数据。在稳定扩散的基础上,Scenario针对游戏开发者和游戏设计者推出了AIGC工具,专注于生成各种游戏资产。
?? 同时,随着NeRF模型的发展,3D建模在室内设计领域的应用迎来了快速发展。只需要几张内饰照片,即可利用NeRF模型快速生成3D内饰造型,并可通过文字指令切换整体风格。随着这项技术的进一步发展,41亿美元的室内设计软件市场或将迎来洗牌。
?? 虽然AI三维生成技术目前已经得到了很大发展,但是应用并不广泛,技术仍然存在局限性。文本和二维图像的结构化数据非常庞大,这也给大模型提供了很好的前提条件。而三维数据目前仍然是比较缺乏的,三维数据采集场景也相当有限。整体来看,三维领域的数据集主要集中在无人驾驶和室内模型上,因而场景是相当局限的。这也导致了很多模型在一些专用数据集和场景下取得不错效果,而扩展性和泛化性则受到了限制。
5.2 数字人
- SMPL 模型
?? 数字人模型始于 SMPL(Skinned Multi-Person Linear)人体模型,是德国马普所Michael J. Black领导下,于2015年SIGGRAPH Asia发表的一种骨架驱动的参数化人体模型。
?? SMPL模型简单易用,很容易集成到各种深度学习的Pipeline种,目前是最为主流的3D人体参数化模型。SMPL人体模型的特别之处是:它是从大量人体数据中学习得到的基于顶点(vertex-based)的加性人体模型,由体型参数 (Shape Components β) 与 姿态参数 (Pose Components θ) 控制3D Mesh的变形。

- SMPL家族:MANO and SMPL+H

?? MANO是从SMPL手部拓扑中创建的。同SMPL类似,MANO也有着template mesh, kinematic tree(手指运动树), 负责手粗细(Shape)和姿态(Pose)的参数以及joint regressor 回归矩阵、blend weights 蒙皮权重等等。
?? 出于细分的目的, 我们让SMPL只负责3D人体,MANO只负责3D手部,这样就把3D人体复刻和驱动的任务解耦合开来,并可以随时将其组合起来。
- SMPL家族:FLAME 和 SMPL-X
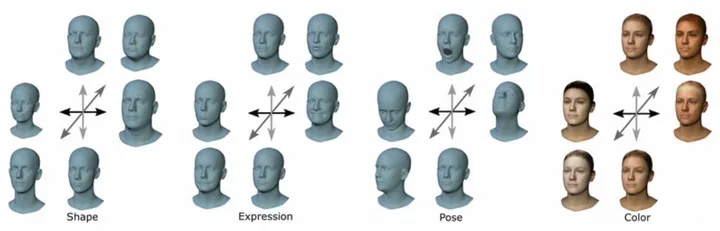
??FLAME,和MANO同样发表于2017年的Siggraph Asia会议,使用SMPL的思路创建了一个头部模型,该模型比现有的头部和面部模型更加准确和富有表现力,同时与标准图形软件保持兼容。
??与现有的模型相比,FLAME明确地模拟了头部姿势和眼球旋转。当然,FLAME也是可以无缝接入SMPL模型的,这就是现在主流的SMPL-X (SMPL + MANO + FLAME, 全称是SMPL eXpressive):

可以看出: 模型的细节逐渐变得丰富起来: 更细微的手部动作(中)和更细节的面部表情(右)
- 基于NeRF的3D人体重建
?? 随着NeRF[8]的飞速发展, 现在出现了很多基于NeRF来做的隐式参数化模型的论文, 这些论文开启了隐式人体建模的新篇章, 不过其问题是推理效果和训练成本都显著高于以SMPL为代表的显式参数化模型。
?? Video2Avatar[10]是一个ETH AIT Lab发表于CVPR2023的一篇论文, 用视频驱动数字人:

汇总下重要的几篇文章:

5. 应用方向
?? 身体的姿态估计(2/3D),可以用来提示体力活动时, 可能出现的姿态不对而导致的风险。被最广泛使用的,就是运动评估和优化环节,像苏炳添等短跑运动员,非常重视用姿态评估跑姿,并优化自己的跑步节奏和方式,用于提高成绩

??驱动3D虚拟形象(retargeting & motion):直接基于SMPL估计人体的主要关节的pose参数(rotation matrix), 然后将其映射到3D Avatar的关节上, 即可让3D虚拟人做出了真人同样的动作, 这种基于单张图片/视频即可完成的映射, 在SMPL出现之前是不行的, 只能依靠穿戴动作捕捉服来实现, 因此, SMPL的出现跨时代的降低了动作捕捉的成本!
??PoseVocab[9]是清华刘烨斌老师课题组发表的SIGGRAPH 2023年的一篇论文, 如图可以看出, 其可以通过多视角的RGB Videos来合成animatable human avatar(3D avatar), 并通过Pose来进行驱动, 这突破了前面的直接驱动3D虚拟形象的限制, 因为前者我们只关注pose的驱动, 而没有关注和解决形象本身的纹理, 材质等部分。

展望:通用人工智能趋势
?? AIGC 对媒体技术的影响是深远而广泛的。 然而,这个新领域也面临着一系列挑战,特别是在道德、监管和就业领域。平衡AIGC能力的利用与这些问题的管理对于媒体技术的道德进步至关重要。当我们踏上这一新征程时,人类创造力和人工智能之间的伙伴关系将继续重塑我们的故事以及我们分享故事的方式。
?? 知识型、创意型岗位的从业者受AIGC影响最直接,主要包括营销人员、销售人员、作家、图像工作者、视频工作者等。AIGC的生成形式可以包括基于素材的部分生成、基于指令的全自主生成生成和生成优化。 在内容上,除了文本、图像、音频、视频等常见的显性内容外,还包括行为逻辑、训练数据、算法策略等非显性内容。理想情况下,几乎所有职业都可以通过人工智能得到改善。
?? AIGC是人工智能生成内容,这只是人工智能技术快速发展的一个部分。更多模态的融合,更加智能的系统会是未来长期发展的方向。人工通用智能(AGI)代表着人类迈向智能革命的巅峰。随着科技的迅猛发展,我们正站在一种新型智能的边缘,这种智能将重新定义我们与技术互动的方式,并彻底改变我们生活、工作和社会的本质。
?? AGI指的是能够像人类一样执行各种智力任务的人工智能系统。这种智能系统不仅能够在特定领域内表现出色,还能够适应和学习新的任务和环境,具有类似人类智能的广泛适应性和推理能力。AGI是追求在多个领域都能表现出类似于人类智能的全面智能水平。今年下半年另一个热门AI概念“AI Agent”正是该领域的一个技术体现。另一方面,GPT系列模型也在通往AGI之中,预计明年更有更多高版本的GPT模型发布。
?? AGI代表着智能技术的新纪元。虽然它的出现带来了许多挑战,但也为人类带来了前所未有的机遇。我们需要积极拥抱这一变革,同时确保智能技术的发展是符合道德、可持续和人类利益的。只有这样,我们才能实现一个更加智能、更加包容和繁荣的未来。AGI的到来并不是一个偶然事件,而是人类智慧和技术进步的必然结果。让我们共同迎接这一智能时代的到来,并以智慧和责任引领未来的发展道路。
部分内容参考于博主<Coding的叶子>
d
\sqrt{d}
d?
1
0.24
\frac {1}{0.24}
0.241?
x
ˉ
\bar{x}
xˉ
x
^
\hat{x}
x^
x
~
\tilde{x}
x~
?
\epsilon
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java读取QR code
- 基于Java SSM框架实现共享充电宝管理系统项目【项目源码+论文说明】
- osg粒子继续学习2
- 第七回 林教头刺配沧州道 鲁智深大闹野猪林-FreeBSD/Linux图形界面安装配置
- 从源码分析 Spring 基于注解的事务
- 【餐饮创业系列】阳光小厨把子肉
- C语言插入排序算法及代码
- 【PlantUML】-类图-布局,如何改变元素位置
- 7-12 sdut-Collection-sort--C~K的班级(II)(java for PTA)
- 代码随想录算法训练营第二十五天|216.组合总和III 17.电话号码的字母组合