【Linux】进程周边004之进程的调度与切换(领略Linux系统进程调度算法的神奇)
?
👀樊梓慕:个人主页
?🎥个人专栏:《C语言》《数据结构》《蓝桥杯试题》《LeetCode刷题笔记》《实训项目》《C++》《Linux》
🌝每一个不曾起舞的日子,都是对生命的辜负
目录
2.1Linux系统的进程调度算法如何实现兼顾进程优先级的设计
2.4Linux系统的进程调度算法如何实现兼顾进程饥饿的设计
前言
上篇文章我们最后提到了进程的并发:多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发。
那么Linux是如何完成进程的调度与切换的呢?
本篇文章博主会与大家共同学习Linux下进程的调度与切换。
?欢迎大家📂收藏📂以便未来做题时可以快速找到思路,巧妙的方法可以事半功倍。?
=========================================================================
GITEE相关代码:🌟fanfei_c的仓库🌟
=========================================================================
1.进程切换
我们知道一个CPU在同一时间只能运行一个进程,而并发实际上就是利用时间片,让每个进程在CPU上只能运行一个时间片的时间,然后就被切换到另一个进程,所以我们计算机虽然看起来似乎是非常流畅的运行每个进程,而实际上则是一卡一卡的运行的,只不过这个时间非常短,我们感觉不到罢了。
那进程首次调度完成被切换走,当CPU二次调度该进程时,是如何记得上次执行到哪里了呢?
CPU中存在有大量的寄存器,进程运行产生的临时数据都被保存在这些寄存器中,这些临时数据被称为进程的硬件上下文,当时间片消耗完的时候,进程会保存这些上下文,现阶段大家可以理解为保存到PCB中,当进程被二次调度时,进程会将曾经保存的硬件上下文进行恢复(将之前保存的硬件上下文覆盖到CPU的寄存器中)。
- 虽然CPU中的寄存器只有一套,但是寄存器内部保存的数据可以有多套。
- CPU是被所有进程共享的,但内部的数据却是进程私有的。
大家可以理解为:在任意一个时刻,CPU中的数据只属于一个进程。
所以看起来,我们用的是同一个设备,但实际上进程之间是具有独立性的。
独立性:进程运行需要独享各种资源,多进程运行期间互不干扰。
2.进程调度
上篇文章我们讲到了优先级的概念,那Linux是如何在兼顾进程优先级、饥饿、效率来实现进程调度的算法呢?
实际上操作系统想要实现一个进程调度算法并不容易,而Linux对于进程调度的算法设计非常优秀,我们一起来学习一下吧:
之前我们学习进程状态时,有关进程排队中CPU运行队列有过这样一张图:
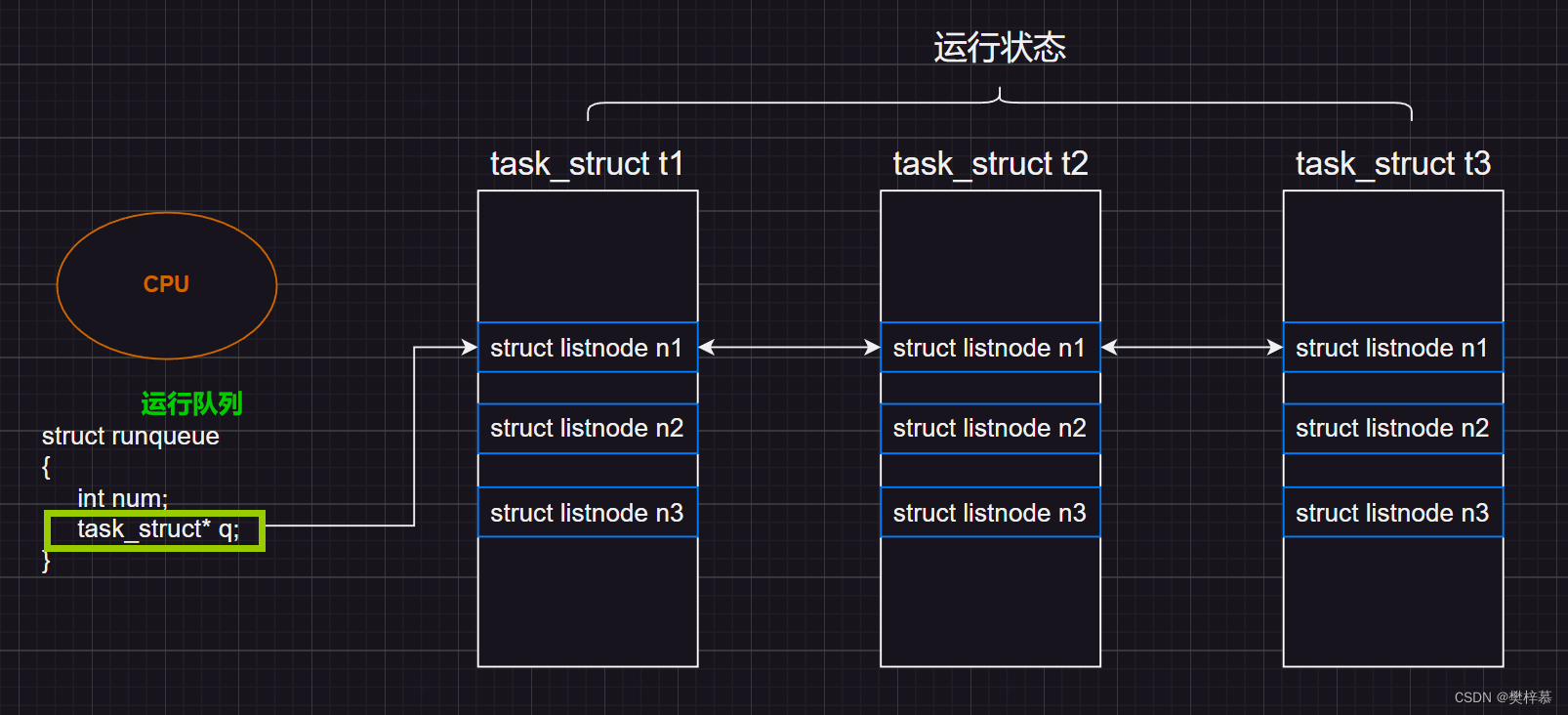
今天我们来细化一下运行队列中的成员:

这是Linux系统下对运行队列的设计。
不考虑其他成员,我们只看圈出来的两个部分:
蓝色部分为活动队列,红色部分为过期队列,他们两个你可以认为是完全相同的两个结构。
2.1Linux系统的进程调度算法如何实现兼顾进程优先级的设计
该数组中一个元素就是一个进程队列,相同优先级的进程按照FIFO(先进先出)规则进行排队调度,所以,数组下标就是优先级!
但我们之前学习优先级时不是说进程优先级范围为[60,99]么,一共40个优先级,为什么这里有140个优先级呢?
首先这里我们只考虑100~139,这部分被称为普通优先级,100就对应着60,139就对应着99,而剩下0~99的部分为实时优先级。
🔎什么是实时优先级?🔍
- 分时操作系统必须以时间片为周期调度不同的进程,是为了确保公平,避免进程饥饿,比如现在的互联网,在互联网的视角中,所有用户都是公平的,不能因为谁的优先级高就仅服务谁,所有用户的优先级都差不太多,不会出现谁的优先级非常高的情况。
- 还有另外一种为实时操作系统则相反,在运行某个进程时,必须跑完,严格按照队列先后顺序进行,如果有更高优先级的进程,允许插队,即实时操作系统必须对用户有高响应这一特性,比如车载系统,绝对不能使用基于时间片轮转的分时操作系统,而必须采用实时操作系统,刹车的指令优先级非常高,在用户需要刹车时他不会考虑音乐播放器进程会不会饥饿。
- 所以我们必须保证一些进程实时尽快的被处理,所以也就有了实时优先级的概念,而0~99这些优先级就是为了这一部分而准备的。
?所以我们运行队列中queue[140]的构成大概为这样子:
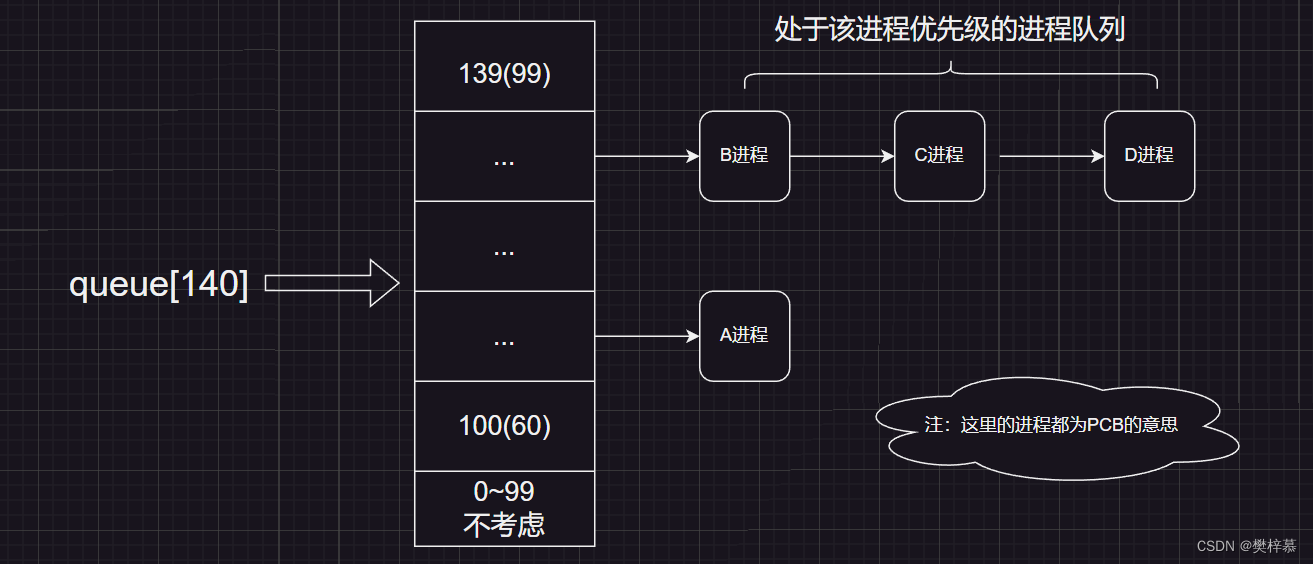
之前我们以为运行队列就是一个队列,但实际上操作系统要给我们维护40个队列,每个队列都代表着不同的优先级。
2.2Linux系统的进程调度算法如何实现兼顾效率的设计
每次CPU运行进程,难道都要从开始向上遍历找不为空的队列么,那也太麻烦了。
所以就有了bitmap[5]这个成员,该成员是int类型的数组,int类型占32个bit,所以5个int就是160个bit,而queue为140,多出来的20我们不管,那是不是检测哪个优先级队列中有进程就能够转化乘检测对应的比特位是否为1了呢!?
位操作的速度可比遍历快多了。
比如:如果数组中某个元素为0,则证明该32个比特位都为0,也就证明该32个队列都为空,如果某个元素不为0,那该问题就转化为了如何从一个整形中提取出最低位的不为0的比特位。
所以该算法在系统中查找一个最合适调度的进程的时间复杂度是一个常数,不会随着进程的增多而导致时间成本增加,被称为O(1)调度算法。
2.3nr_active
表示该运行队列共有多少个活跃进程。
2.4Linux系统的进程调度算法如何实现兼顾进程饥饿的设计
假设在运行队列里存在有很多优先级为139的进程等待执行,但此时不断产生更高优先级的进程,也就导致优先级为139的进程进程饥饿的问题了。
2.4.1理论上讲解
那Linux系统是如何处理进程饥饿的呢?
Linux系统搞了两个一摸一样的结构就是为了处理进程饥饿。
一个称之为活跃队列,一个称之为过期队列。
CPU只会执行活跃队列中的进程,而新产生的进程会被操作系统添加到过期队列,不论这个新进程的优先级高低,等活跃队列中的进程都被执行完成了后,此时过期队列摇身一变成为活跃队列,而活跃队列变为过期队列,周而复始,也就解决了进程饥饿的问题。
注意:如果某个处在活跃队列中的进程的时间片消耗完,该进程就会从活跃队列中剥离,然后被添加到过期队列。
2.4.2如何实现的?
我们将蓝色框与红色框定义为两个结构体:
struct q//这两个结构体相同,这里就写一个大家理解就行
{
int nr_active;
int bitmap[5];
task_struct queue[140];
}再定义一个数组struct q array[2];
该数组用来存放这两个结构体。
再定义两个成员*active与*expired:
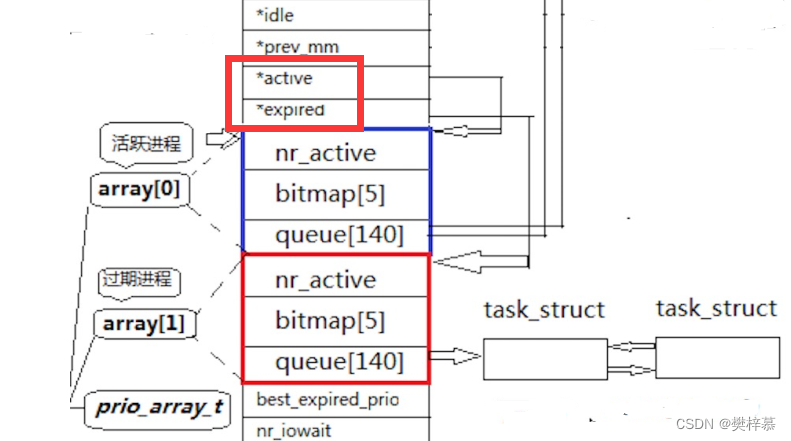
这两个指针分别指向数组中的内容,即:
struct q *active=&array[0];
struct q *expired=&array[1];?每当活跃队列为空时,就会交换这两个指针变量的内容,使之指向对方原来指向的内容,这也就完成了活跃队列变为过期队列,过期队列变为活跃队列的操作:
swap(&active,&expired);所以Linux系统对于进程调度的设计是不是非常巧妙呢!??
=========================================================================
如果你对该系列文章有兴趣的话,欢迎持续关注博主动态,博主会持续输出优质内容
🍎博主很需要大家的支持,你的支持是我创作的不竭动力🍎
🌟~ 点赞收藏+关注 ~🌟
=========================================================================
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SQL Server命令大全
- 探索鸿蒙:了解华为鸿蒙操作系统的基础课程
- 鸿蒙原生应用再添新丁!同花顺入局鸿蒙
- 软件测试/测试开发丨Pytest结合数据驱动-Excel
- 4. seaborn-线性关系可视化
- 触发艺术引擎,打开灵魂共鸣——昆明中致远虹桥保时捷中心“精彩共驰”青年艺术家联展重磅开展
- 环信IM Demo登录方式如何修改为自己项目的?
- uView SwipeAction 滑动单元格
- 数据结构学习 jz46把数字翻译成字符串
- Statistics with Python知识总结:库、统计图