机器学习或深度学习的数据读取工作(大数据处理)
发布时间:2023年12月25日
机器学习或深度学习的数据读取工作(大数据处理)主要是.split和re.findall和glob.glob运用。
读取文件的路径(为了获得文件内容)和提取文件路径中感兴趣的东西(标签)
1,“glob.glob”用于读取文件路径
2,“.split“用于字符串分割
3,”re.findall“用于获取字符串里的感兴趣的东西
文章目录
一、目标是什么?
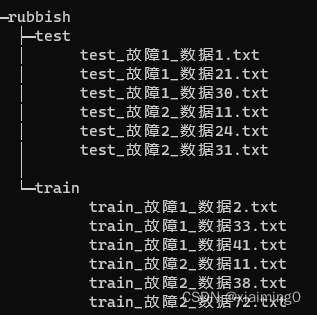
获取rubbish文件夹下以.txt结尾文件的路径,并提取文件名里面指定的内容(本次实验是获取文件名(test_故障1_数据1.txt)里“数据”后面的数字)。
二、实验代码
2.1 获取全部路径(包含文件名的路径)
2.1.1 获取全部路径错误代码如下(示例):
import numpy as np
import glob
import re
# 1,错误获取路径
data_path_error = glob.glob(r'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish/*/*.txt')
data_path_error.sort()
2.1.2 获取全部路径错误代码结果:
# ['C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障1_数据1.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障1_数据21.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障1_数据30.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障2_数据11.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障2_数据24.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障2_数据31.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障1_数据2.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障1_数据33.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障1_数据41.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障2_数据11.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障2_数据38.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障2_数据72.txt']
路径下既有单斜杠(“/”)又有所斜杠(“\”),python的很多读取函数识别不了。
2.1.3 获取全部路径正确代码:
# 1,正确获取路径
data_path_right = glob.glob('C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\*\\*.txt')
data_path_right.sort()
2.1.4 获取全部路径正确代码结果
# ['C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据1.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据21.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据30.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据11.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据24.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据31.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据2.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据33.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据41.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据11.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据38.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据72.txt']
2.2 分别获取训练集和测试集的文件路径
代码如下(示例):
# 2,分别获取训练集和测试集的文件路径
# 2.1,获取文件名
file_name = [x.split('\\')[-1] for x in data_path_right]
file_name_temp = [x.split('_')[0] for x in file_name]
# 2.1,将训练集和测试集分开
# 2.1.1,获取训练集和测试集大小
test_size = 0
train_size = 0
for i in file_name_temp:
if i == "test":
test_size = test_size + 1
elif i == "train":
train_size = train_size + 1
# 2.1.2,获取训练集和测试集文件路径
train_path = np.empty((train_size), dtype=object)
test_path = np.empty((test_size), dtype=object)
test_size_index = 0
train_size_index = 0
for i_index, i in enumerate(file_name_temp):
if i == "test":
test_path[test_size_index] = data_path_right[i_index]
test_size_index = test_size_index + 1
elif i == "train":
train_path[train_size_index] = data_path_right[i_index]
train_size_index = train_size_index + 1
train_path = list(train_path)
# ['C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据2.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据33.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据41.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据11.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据38.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据72.txt']
test_path = list(test_path)
# ['C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据1.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据21.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据30.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据11.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据24.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据31.txt']
2.3 获取文件名里面指定的内容
test_fault_severity = [x.split('\\')[-1] for x in test_path]
test_fault_severity = [x.split('_')[-1] for x in test_fault_severity]
test_fault_severity = [x.split('.')[0] for x in test_fault_severity]
test_fault_severity = [re.findall(r'\d+', path)[0] for path in test_fault_severity]
print(test_fault_severity)
结果:
[‘1’, ‘21’, ‘30’, ‘11’, ‘24’, ‘31’]
3 全部代码
import numpy as np
import glob
import re
# 1,错误获取路径
data_path_error = glob.glob(r'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish/*/*.txt')
data_path_error.sort()
# ['C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障1_数据1.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障1_数据21.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障1_数据30.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障2_数据11.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障2_数据24.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\test\\test_故障2_数据31.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障1_数据2.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障1_数据33.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障1_数据41.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障2_数据11.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障2_数据38.txt',
# 'C:/Users/houweiming/Desktop/faut_data/code_public_dataset/rubbish\\train\\train_故障2_数据72.txt']
# 1,正确获取路径
data_path_right = glob.glob('C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\*\\*.txt')
data_path_right.sort()
# ['C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据1.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据21.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据30.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据11.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据24.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据31.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据2.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据33.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据41.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据11.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据38.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据72.txt']
# 2,分别获取训练集和测试集的文件路径
# 2.1,获取文件名
file_name = [x.split('\\')[-1] for x in data_path_right]
file_name_temp = [x.split('_')[0] for x in file_name]
# 2.1,将训练集和测试集分开
# 2.1.1,获取训练集和测试集大小
test_size = 0
train_size = 0
for i in file_name_temp:
if i == "test":
test_size = test_size + 1
elif i == "train":
train_size = train_size + 1
# 2.1.2,获取训练集和测试集文件路径
train_path = np.empty((train_size), dtype=object)
test_path = np.empty((test_size), dtype=object)
test_size_index = 0
train_size_index = 0
for i_index, i in enumerate(file_name_temp):
if i == "test":
test_path[test_size_index] = data_path_right[i_index]
test_size_index = test_size_index + 1
elif i == "train":
train_path[train_size_index] = data_path_right[i_index]
train_size_index = train_size_index + 1
train_path = list(train_path)
# ['C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据2.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据33.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障1_数据41.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据11.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据38.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\train\\train_故障2_数据72.txt']
test_path = list(test_path)
# ['C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据1.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据21.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障1_数据30.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据11.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据24.txt',
# 'C:\\Users\\houweiming\\Desktop\\faut_data\\code_public_dataset\\rubbish\\test\\test_故障2_数据31.txt']
# 3,分别获取训练集和测试集的故障类型
test_fault_severity = [x.split('\\')[-1] for x in test_path]
test_fault_severity = [x.split('_')[-1] for x in test_fault_severity]
test_fault_severity = [x.split('.')[0] for x in test_fault_severity]
test_fault_severity = [re.findall(r'\d+', path)[0] for path in test_fault_severity]
print(test_fault_severity)
print("HELLO WORLD!")
注意事项
1,.split解释
# x.split('\\')
# 将字符串分割成一个列表,并以指定的分隔符进行分割。在这个例子中,我们使用“\\”作为分隔符。
2,.findall解释
# def findall(pattern, string, flags=0):
# string中所有与pattern匹配的全部字符串,返回形式为列表,如果pattern中含有分组,返回分组的匹配结果。如果有pattern中有多个分组,则返回元组列表。
# 例子:
# import re
# kk = re.compile(r'\d+')
# kk.findall('one1two2three3four4')
# #[1,2,3,4]
文章来源:https://blog.csdn.net/xiaiming0/article/details/135175708
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!