Spark基础原理
发布时间:2024年01月08日
Spark On Yarn
Spark On Yarn的本质
Spark专注于分布式计算,Yarn专注于资源管理,Spark将资源管理的工作交给了Yarn来负责
Spark On Yarn两种部署方式
Spark中有两种部署方式,Client和Cluster方式,默认是Client方式。这两种方式的本质区别,是Driver进程运行的地方不一样。
Client部署方式: Driver进程运行在你提交程序的那台机器上
优点: 将运行结果和运行日志全部输出到了提交程序的机器上,方便查看结果
缺点: Driver进程和Yarn集群可能不在同一个集群中,会导致Driver和Executor进程间进行数据交换的时候,效率比较低
使用: 一般用在开发和测试中
Cluster部署方式: Driver进程运行在集群中某个从节点上
优点: Driver进程和Yarn集群在同一个集群中,Driver和Executor进程间进行数据交换的时候,效率比较高
缺点: 需要去18080或者8088页面查看日志和运行结果
使用: 一般用在生产环境使用
spark-submit命令
后续需要将自己编写的Spark程序提交到相关的资源平台上,比如说: local yarn spark集群(standalone)
? Spark为了方便任务的提交操作,专门提供了一个用于进行任务提交的脚本文件: spark-submit
? spark-submit在提交的过程中,设置非常多参数,调整任务相关信息。如果忘记了,可以使用spark-submit --help进行查看
- 基本参数设置

- Driver的资源配置参数

- executor的资源配置参数

PySpark程序与Spark交互流程
client on Spark集群(standalone)
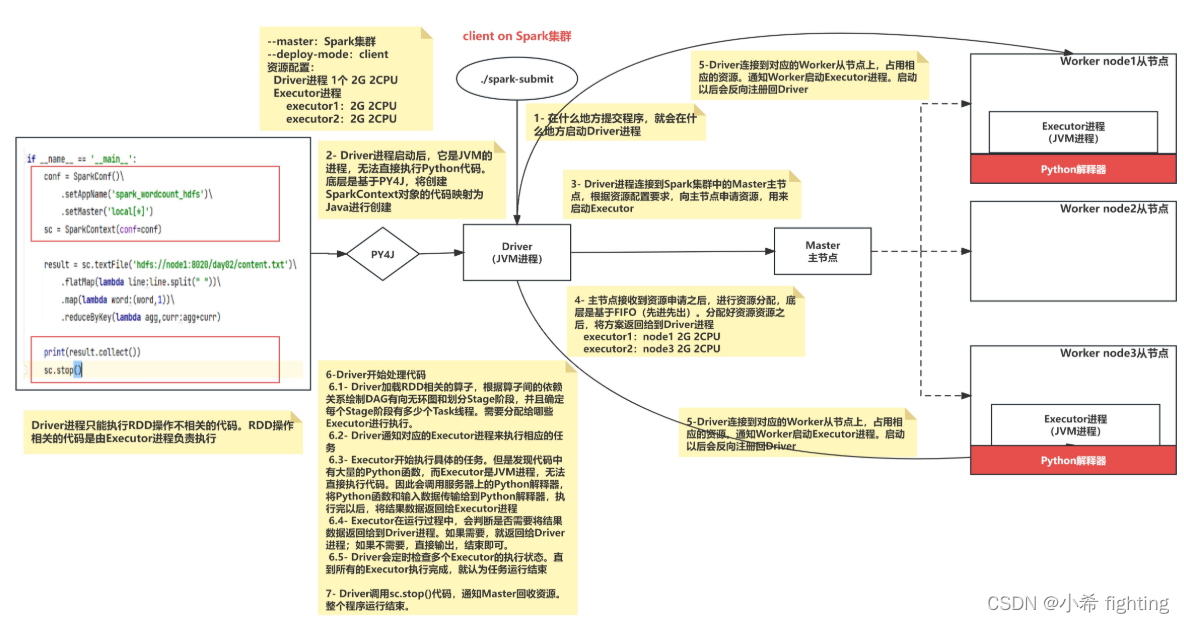
1- 在什么地方提交程序,就会在什么地方启动Driver进程
2- Driver进程启动后,它是JVM的进程,无法直接执行Python代码。底层是基于PY4J,将创建SparkContext对象的代码映射为Java进行创建
3- Driver进程连接到Spark集群中的Master主节点,根据资源配置要求,向主节点申请资源,用来启动Executor
4- 主节点接收到资源申请之后,进行资源分配,底层是基于FIFO(先进先出)。分配好资源资源之后,将方案返回给到Driver进程
executor1:node1 2G 2CPU
executor2:node3 2G 2CPU
5-Driver连接到对应的Worker从节点上,占用相应的资源。通知Worker启动Executor进程。启动以后会反向注册回Driver
6-Driver开始处理代码
6.1- Driver加载RDD相关的算子,根据算子间的依赖关系绘制DAG有向无环图和划分Stage阶段,并且确定每个Stage阶段有多少个Task线程。需要分配给哪些Executor进行执行。
6.2- Driver通知对应的Executor进程来执行相应的任务
6.3- Executor开始执行具体的任务。但是发现代码中有大量的Python函数,而Executor是JVM进程,无法直接执行代码。因此会调用服务器上的Python解释器,将Python函数和输入数据传输给到Python解释器,执行完以后,将结果数据返回给Executor进程
6.4- Executor在运行过程中,会判断是否需要将结果数据返回给到Driver进程。如果需要,就返回给Driver进程;如果不需要,直接输出,结束即可。
6.5- Driver会定时检查多个Executor的执行状态。直到所有的Executor执行完成,就认为任务运行结束
7- Driver调用sc.stop()代码,通知Master回收资源。整个程序运行结束。
cluster on Spark集群
区别点: Driver进程就不是运行在提交任务的那台机器上了,而是在Spark集群中随机选择一个Worker从节点来启动和运行Driver进程
1- 将任务提交给到Spark集群的主节点Master
2- 主节点接收到任务信息以后,根据Driver的资源配置要求,在集群中随机选择(在资源充沛的众多从节点中随机选择)一个Worker从节点来启动和运行Driver进程
3- Driver进程启动以后,执行main函数,首先创建SparkContext对象。底层是基于PY4J,将创建SparkContext对象的代码映射为Java进行创建
4- Driver进程连接到Spark集群中的Master主节点,根据资源配置要求,向主节点申请资源,用来启动Executor
5- 主节点接收到资源申请之后,进行资源分配,底层是基于FIFO(先进先出)。分配好资源资源之后,将方案返回给到Driver进程
executor1:node1 2G 2CPU
executor2:node3 2G 2CPU
6-Driver连接到对应的Worker从节点上,占用相应的资源。通知Worker启动Executor进程。启动以后会反向注册回Driver
7-Driver开始处理代码
7.1- Driver加载RDD相关的算子,根据算子间的依赖关系绘制DAG有向无环图和划分Stage阶段,并且确定每个Stage阶段有多少个Task线程。需要分配给哪些Executor进行执行。
7.2- Driver通知对应的Executor进程来执行相应的任务
7.3- Executor开始执行具体的任务。但是发现代码中有大量的Python函数,而Executor是JVM进程,无法直接执行代码。因此会调用服务器上的Python解释器,将Python函数和输入数据传输给到Python解释器,执行完以后,将结果数据返回给Executor进程
7.4- Executor在运行过程中,会判断是否需要将结果数据返回给到Driver进程。如果需要,就返回给Driver进程;如果不需要,直接输出,结束即可。
7.5- Driver会定时检查多个Executor的执行状态。直到所有的Executor执行完成,就认为任务运行结束
8- Driver调用sc.stop()代码,通知Master回收资源。整个程序运行结束。
client on Yarn集群
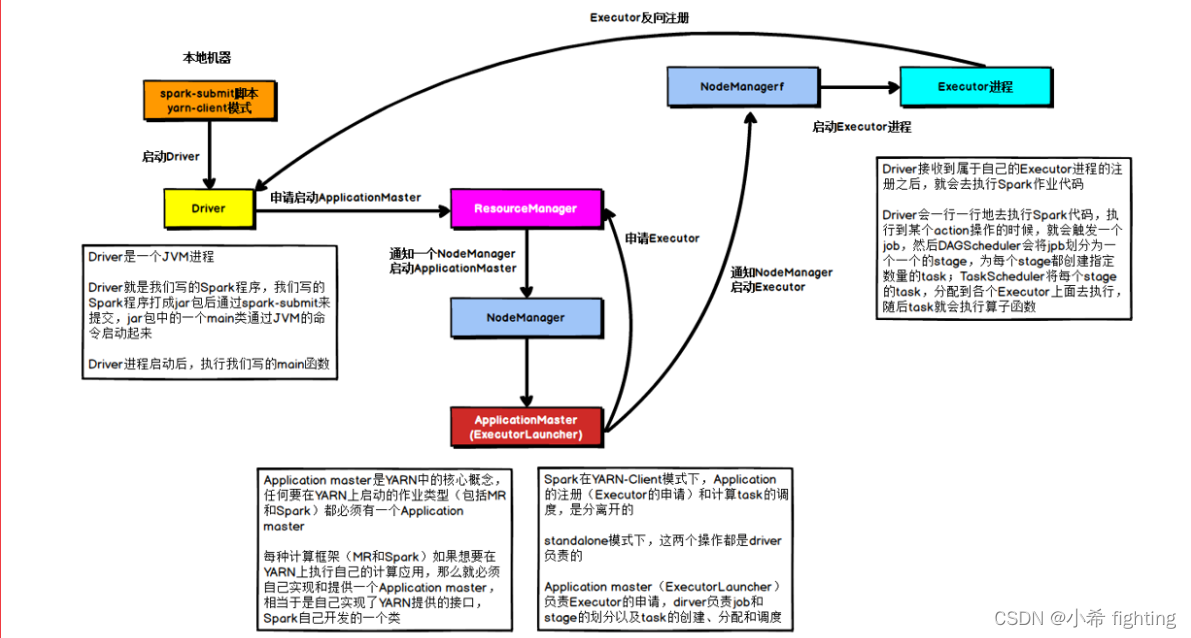
区别点: 将Driver进程中负责资源申请的工作,转交给到Yarn的ApplicationMaster来负责。Driver主要负责任务的分配、任务的管理工作。
1- 首先会在提交的节点启动一个Driver进程
2- Driver进程启动以后,执行main函数,首先创建SparkContext对象。底层是基于PY4J,将创建SparkContext对象的代码映射为Java进行创建
3- 连接Yarn集群的主节点(ResourceManager),将需要申请的资源封装为一个任务,提交给到Yarn的主节点。主节点收到任务以后,首先随机选择一个从节点(NodeManager)启动ApplicationMaster
4- 当ApplicationMaster启动之后,会和Yarn的主节点建立心跳机制,告知已经启动成功。启动成功以后,就进行资源的申请工作,将需要申请的资源通过心跳包的形式发送给到主节点。主节点接收到资源申请后,开始进行资源分配工作,底层是基于资源调度器来实现(默认为Capacity容量调度器)。当主节点将资源分配完成以后,等待ApplicationMaster来拉取资源。ApplicationMaster会定时的通过心跳的方式询问主节点是否已经准备好了资源。一旦发现准备好了,就会立即拉取对应的资源信息。
5- ApplicationMaster根据拉取到的资源信息,连接到对应的从节点。占用相应的资源,通知从节点启动Executor进程。从节点启动完Executor之后,会反向注册回Driver进程
6-Driver开始处理代码
6.1- Driver加载RDD相关的算子,根据算子间的依赖关系绘制DAG有向无环图和划分Stage阶段,并且确定每个Stage阶段有多少个Task线程。需要分配给哪些Executor进行执行。
6.2- Driver通知对应的Executor进程来执行相应的任务
6.3- Executor开始执行具体的任务。但是发现代码中有大量的Python函数,而Executor是JVM进程,无法直接执行代码。因此会调用服务器上的Python解释器,将Python函数和输入数据传输给到Python解释器,执行完以后,将结果数据返回给Executor进程
6.4- Executor在运行过程中,会判断是否需要将结果数据返回给到Driver进程。如果需要,就返回给Driver进程;如果不需要,直接输出,结束即可。
6.5- Driver会定时检查多个Executor的执行状态。直到所有的Executor执行完成,就认为任务运行结束。同时ApplicationMaster也会接收到各个节点的执行完成状态,然后通知主节点。任务执行完成了,主节点回收资源,关闭ApplicationMaster,并且通知Driver。
7- Driver执行sc.stop()代码。Driver进程退出
cluster on Yarn集群
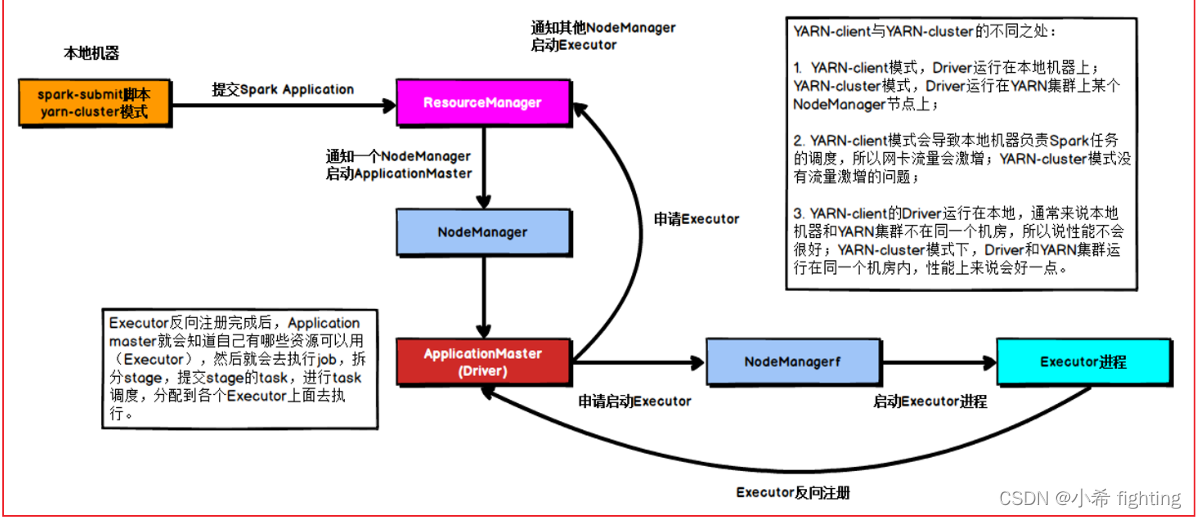
区别点: 在集群模式下,Driver进程的功能和ApplicationMaster的功能(角色)合二为一了。Driver就是ApplicationMaster,ApplicationMaster就是Driver。既要负责资源申请,又要负责任务的分配和管理。
1- 首先会将任务提交给Yarn集群的主节点(ResourceManager)
2- ResourceManager接收到任务信息后,根据Driver(ApplicationMaster)的资源配置信息要求,选择一个
nodeManager节点(有资源的,如果都有随机)来启动Driver(ApplicationMaster)程序,并且占用相对应资源
3- Driver(ApplicationMaster)启动后,执行main函数。首先创建SparkContext对象(底层是基于PY4J,识
别python的构建方式,将其映射为Java代码)。创建成功后,会向ResourceManager进行建立心跳机制,告知已经
启动成功了
4- 根据executor的资源配置要求,向ResourceManager通过心跳的方式申请资源,用于启动executor(提交的任
务的时候,可以自定义资源信息)
5- ResourceManager接收到资源申请后,根据申请要求,进行分配资源。底层是基于资源调度器来资源分配(默认
为Capacity容量调度)。然后将分配好的资源准备好,等待Driver(ApplicationMaster)拉取操作
executor1: node1 2个CPU 2GB内存
executor2: node3 2个CPU 2GB内存
6- Driver(ApplicationMaster)会定时询问是否准备好资源,一旦准备好,立即获取。根据资源信息连接对应的
节点,通知nodeManager启动executor,并占用相应资源。nodeManager对应的executor启动完成后,反向注册
回给Driver(ApplicationMaster)程序(已经启动完成)
7- Driver(ApplicationMaster)开始处理代码:
7.1 首先会加载所有的RDD相关的API(算子),基于算子之间的依赖关系,形成DAG执行流程图,划分stage阶
段,并且确定每个阶段应该运行多少个线程以及每个线程应该交给哪个executor来运行(任务分配)
7.2 Driver(ApplicationMaster)程序通知对应的executor程序, 来执行具体的任务
7.3 Executor接收到任务信息后, 启动线程, 开始执行处理即可: executor在执行的时候, 由于RDD代
码中有大量的Python的函数,Executor是一个JVM程序 ,无法解析Python函数, 此时会调用Python解析器,执
行函数, 并将函数结果返回给Executor
7.4 Executor在运行过程中,如果发现最终的结果需要返回给Driver(ApplicationMaster),直接返回
Driver(ApplicationMaster),如果不需要返回,直接输出 结束即可
7.5 Driver(ApplicationMaster)程序监听这个executor执行的状态信息,当Executor都执行完成后,
Driver(ApplicationMaster)认为任务运行完成了
8- 当任务执行完成后,Driver执行sc.stop()通知ResourceManager执行完成,ResourceManager回收资源,
Driver程序退出即可
文章来源:https://blog.csdn.net/qq_50215015/article/details/135451897
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 华南理工大学数字信号处理实验考试(薛y老师)
- 代码随想录刷题题Day24
- vue3项目中使用vite-plugin-svg-icons插件
- MYSQL单表删除重复的数据方法
- UDS诊断(ISO14229-1) 31服务
- 【数据库原理】(19)在实际数据库设计中关系规范化的应用
- 前端JavaScript篇之实现有序数组原地去重方法有哪些?
- MongoDB文档操作
- CoTracker 环境配置&与ORB 特征点提取结合实现视频特征点追踪
- 腾讯云怎么领取免费云服务器?