高级分布式系统-第15讲 分布式机器学习--联邦学习
联邦学习
两种常见的架构:客户-服务器架构和对等网络架构

联邦学习在传统的分布式机器学习基础上的变化。
传统的分布式机器学习:在数据中心或计算集群中使用并行训练,因为有高速通信连接,所以通信开销相对很小,计算开销将会占主导地位。
联邦学习:通信需要依靠互联网,甚至是无线网络,所以通信代价是占主导地位的。
减少通信轮次的方法
? 增加并行度:加入更多的参与方,让它们在通信轮次间各自独立地进行模型训练。
? 增加每一个参与方中的计算:每一个参与方可以在两个通信轮次之间进行更复杂的计算。
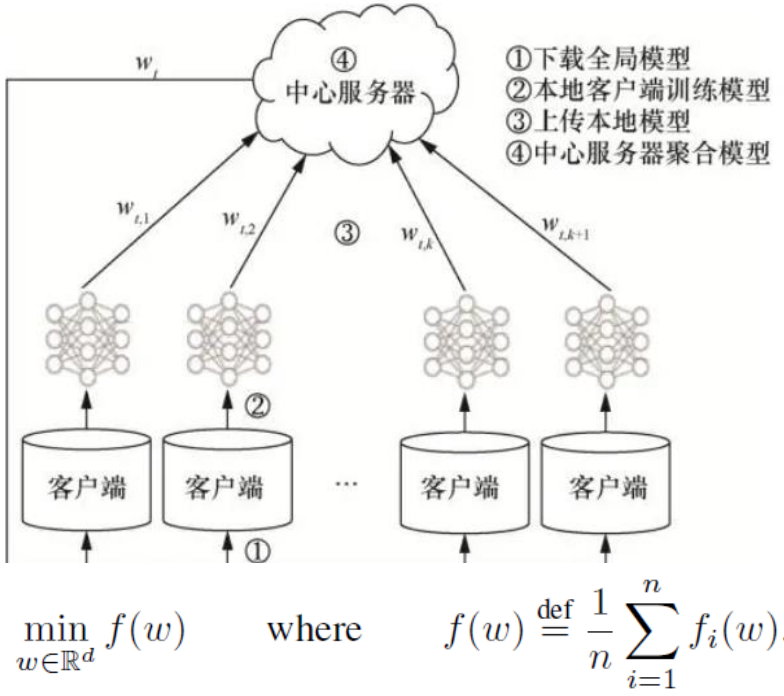
最经典的联邦学习算法——FedAvg
1、服务器初始化训练模型,并随机选择所有客户端中的一部分将模型广播给被选择的用户。
2、被选择的客户端先将接受到的模型作为初始化模型,在利用本地数据进行训练,然后将结果上传给服务器。
3、服务器聚合收到的模型,然后再随机选择所有客户端中的一部分,将模型广播给被选择的用户。
4、重复2和3,直至模型收敛。
FedAvg存在的两个缺陷:
? 设备异质性:不同的设备间的通信和计算能力是有差异的。在FedAvg中,被选中的客户端在本地都训练相同的epoch,虽然作者指出提升epoch可以有效减小通信成本,但较大的epoch下,可能会有很多设备无法按时完成训练。无论是直接drop掉这部分客户端的模型还是直接利用这部分未完成的模型来进行聚合,都将对最终模型的收敛造成不好的影响。
? 数据异质性:不同设备中数据可能是非独立同分布的。如果数据是独立同分布的,那么本地模型训练较多的epoch会加快全局模型的收敛;如果不是独立同分布的,不同设备在利用非IID的本地数据进行训练并且训练轮数较大时,本地模型将会偏离初始的全局模型。
FedProx——FedAvg的改进

异步与同步联邦学习的结合
Resource-Efficient Federated Learning with Hierarchical Aggregation in Edge Computing(IEEE INFOCOM 2021)
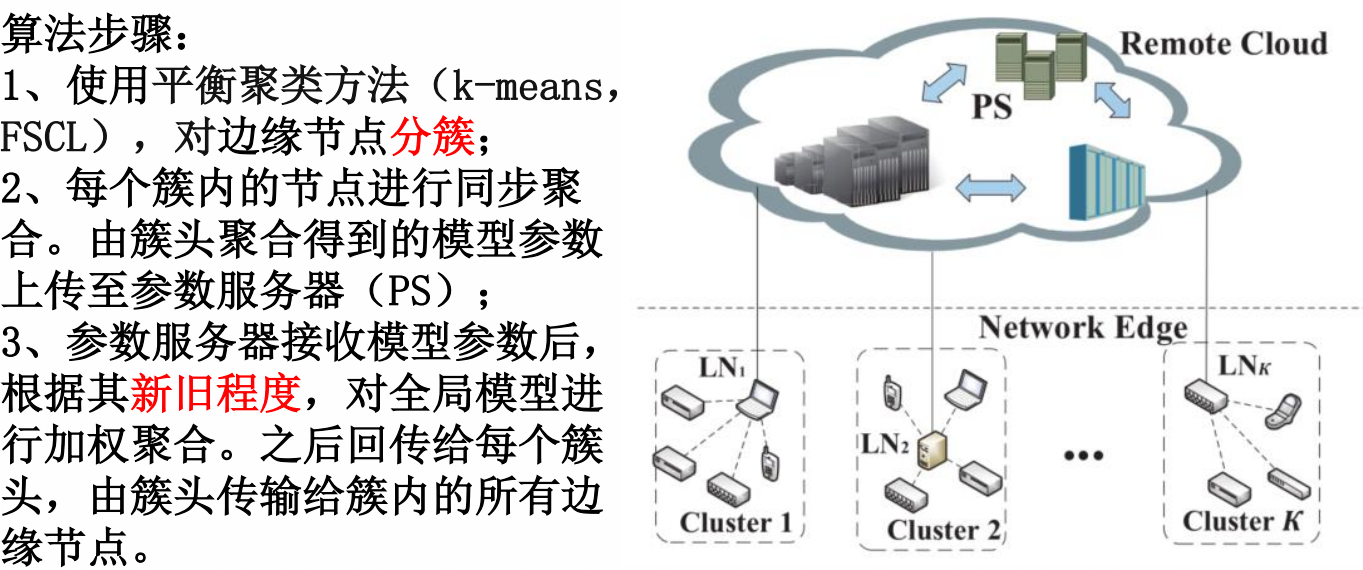
联邦学习算法的优化分类方法

联邦学习涉及的应用研究

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 5_js数组常用函数与let与const关键字
- 一文读懂量化交易中的算法交易使用!
- Java零基础学习18:字符串
- 五个常见的 jQuery 面试题
- 怎样制作一本旅游电子相册呢?
- 使用Python管理MySQL数据库,有录播直播私教课视频教程
- 【ros2 control 机器人驱动开发】简单双关节机器人学习-example 1
- springboot基于WEB的旅游推荐系统设计与实现
- Shell脚本的条件语句-------if语句与case语句
- 全面的开发者文档和用户目标解析:API 文档指南和开发者旅程