深度学习-多层感知器-建立MLP实现非线性二分类-MLP实现图像多分类
多层感知器(Multi-Layer Perceptron)(人工神经网络)
多层感知器模型框架

MLP用于非线性分类预测
在不增加高次项数据的情况下,如何通过MLP实现非线性分类预测





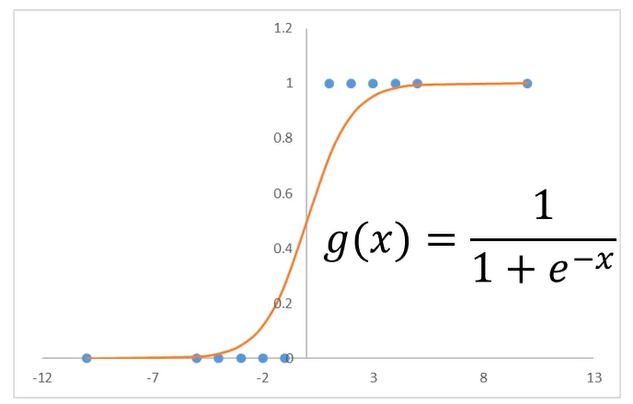
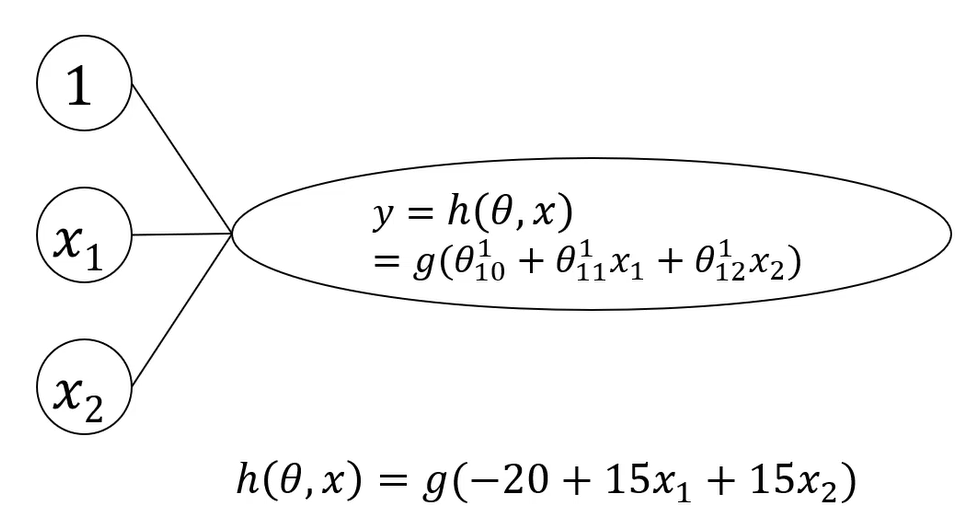

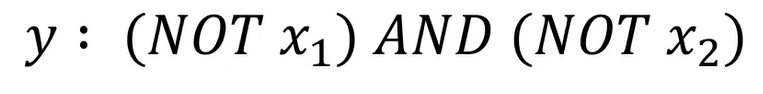

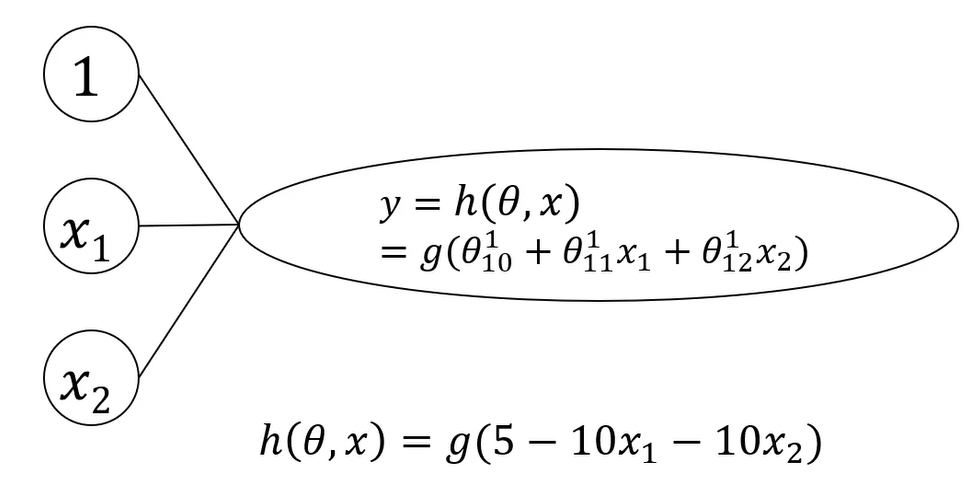







MLP模型框架

MLP实现多分类预测


实战准备
Keras
Keras是一个用Python编写的用于神经网络开发的应用接口,调用开接口可以实现神经网络、卷积神经网络、循环神经网络等常用深度学习算法的开发
特点:
- 集成了深度学习中各类成熟的算法,容易安装和使用,样例丰富,教程和文档也非常详细
- 能够以TensorFlow,或者Theano作为后端运行
Keras or Tensorflow
Tensorflow是一个采用数据流图,用于数值计算的开源软件库,可自动计算模型相关的微分导数:非常适合用于神经网络模型的求解。
Keras可看作为tensorflow封装后的一个接口(Keras作为前端,TensorFlow作为后端。
Keras为用户提供了一个易于交互的外壳,方便进行深度学习的快速开发
Keras建立MLP模型
# 建立一个Sequential顺序模型
from keras.models import Sequential
model = Sequential()
# 通过.add()叠加各层网络
from keras.layers import Dense
model.add(Dense(units=3,activation='sigmoid',input_dim=3))
model.add(Dense(units=1,activation='sigmoid'))
# 通过.compile()配置模型求解过程参数
model.compile(loss='categorical_crossentropy',optimizer='sgd'])
# 训练模型
model.fit(x_train,y_train,epochs=5)

实战-建立MLP实现非线性二分类

任务:基于data.csv数据,建立mlp模型,计算其在测试数据上的准确率,可视化模型预测结果︰
- 进行数据分离:
test_size=0.33,random_state=10
- 模型结构:一层隐藏层,有20个神经元

建立MLP模型,查看模型结构
from keras.models import Sequential
from keras.layers import Dense,Activation
mlp = Sequential()
mlp.add(Dense(20,input_dim=2,activation='sigmoid'))
mlp.add(Dense(1,activation='sigmoid'))
mlp.summary()
配置模型参数
mlp.compile(optimizer='adam',loss='binary_crossentropy')
模型训练
mlp.fit(X_train,y_train,epochs=3000)
结果预测
y_test_predict = mlp.predict_classes(X_test)
把预测结果转换为可用于索引的Series类型
y_range_predict = pd.Series([i[0] for i in y_range_predict])
实战:MLP实现图像多分类

任务:基于mnist数据集,建立mlp模型,实现0-9数字的十分类:
- 实现mnist数据载入,可视化图形数字
- 完成数据预处理:图像数据维度转换与归一化、输出结果格式转换
- 计算模型在预测数据集的准确率
- 模型结构:两层隐藏层,每层有392个神经元
mnist数据集介绍
机器学习领域中非常经典的一个数据集,由60000个训练样本和10000个测试样本组成,每个样本都是一张28*28像素的灰度手写数字图片。
- 官方网站: http://yann.lecun.com/exdb/mnist/
- 一共4个文件,训练集、训练集标签、测试集、测试集标签
加载mnist数据集
from keras.datasets import mnist
(X_train,y_train),(X_test,y_test) = mnist.load_data()
可视化图片
img1=X_train[0]
fig1=plt.figure(figsize=(3,3))
plt.imshow(img1)
转换输出结果格式
from keras.utils import to_categorical
y_train_format = to_categorical(y_train)
转换输入数据维度
feature_size = (img1.shape[0])*(img1.shape[1])
X_train_format = X_train.reshape(X_train.shape[0],feature_size)
模型建立
mlp = Sequential()
mlp.add(Dense(units=392,activation='sigmoid',input_dim=feature_size))
mlp.add(Dense(units=392,activation='sigmoid'))
mlp.add(Dense(units=10,activation='softmax'))
模型训练参数
mlp.compile(loss='categorical_crossentropy',optimizer='adam'])
模型训练
mlp.fit(X_train_normal,y_train_format,epochs=10)
实战-建立MLP实现非线性二分类
任务:基于data.csv数据,建立mlp模型,计算其在测试数据上的准确率,可视化模型预测结果
- 进行数据分离test_size=0.33,random_state=10
- 模型结构:一层隐藏层,有20个神经元
加载数据
import pandas as pd
import numpy as np
data = pd.read_csv('data.csv')
data.head()
赋值
X = data.drop(['y'],axis=1)
y = data.loc[:,'y']
X.head()
数据可视化
from matplotlib import pyplot as plt
fig1 = plt.figure(figsize=(5,5))
passed=plt.scatter(X.loc[:,'x1'][y==1],X.loc[:,'x2'][y==1])
failed=plt.scatter(X.loc[:,'x1'][y==0],X.loc[:,'x2'][y==0])
plt.legend((passed,failed),('passed','failed'))
plt.xlabel('x1')
plt.ylabel('x2')
plt.title('raw data')
plt.show()

数据分离
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.33,random_state=10)
print(X_train.shape,X_test.shape,X.shape)
建立模型
from keras.models import Sequential
from keras.layers import Dense, Activation
mlp = Sequential()
mlp.add(Dense(units=20, input_dim=2, activation='sigmoid'))
mlp.add(Dense(units=1,activation='sigmoid'))
mlp.summary()

配置
mlp.compile(optimizer='adam',loss='binary_crossentropy')
训练
mlp.fit(X_train,y_train,epochs=3000)

计算模型预测准确率
y_train_predict = mlp.predict_classes(X_train)
from sklearn.metrics import accuracy_score
accuracy_train = accuracy_score(y_train,y_train_predict)
print(accuracy_train)

测试数据集准确率
y_test_predict = mlp.predict_classes(X_test)
accuracy_test = accuracy_score(y_test,y_test_predict)
print(accuracy_test)

查看数据格式
print(y_train_predict[0:10])
生成点集 预测
xx, yy = np.meshgrid(np.arange(0,1,0.01),np.arange(0,1,0.01))
x_range = np.c_[xx.ravel(),yy.ravel()]
y_range_predict = mlp.predict_classes(x_range)
print(type(y_range_predict))
转换格式
y_range_predict_form = pd.Series(i[0] for i in y_range_predict)
print(y_range_predict_form)
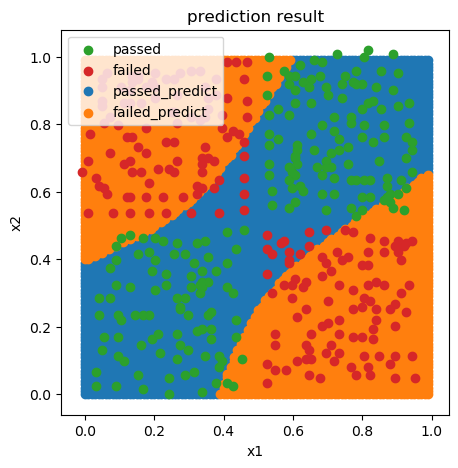
可视化
fig2 = plt.figure(figsize=(5,5))
passed_predict=plt.scatter(x_range[:,0][y_range_predict_form==1],x_range[:,1][y_range_predict_form==1])
failed_predict=plt.scatter(x_range[:,0][y_range_predict_form==0],x_range[:,1][y_range_predict_form==0])
passed=plt.scatter(X.loc[:,'x1'][y==1],X.loc[:,'x2'][y==1])
failed=plt.scatter(X.loc[:,'x1'][y==0],X.loc[:,'x2'][y==0])
plt.legend((passed,failed,passed_predict,failed_predict),('passed','failed','passed_predict','failed_predict'))
plt.xlabel('x1')
plt.ylabel('x2')
plt.title('prediction result')
plt.show()
实战二:MLP实现图像多分类
基于mnist数据集,建立mlp模型,实现0-9数字的十分类task::
- 实现mnist数据载入,可视化图形数字
- 完成数据预处理:图像数据维度转换与归一化、输出结果格式转换
- 计算模型在预测数据集的准确率
- 模型结构:两层隐藏层,每层有392个神经元
载入数据
from keras.datasets import mnist
(X_train,y_train),(X_test,y_test) = mnist.load_data()
查看数据类别和维度
print(type(X_train),X_train.shape)

可视化一个数据
img1 = X_train[0]
%matplotlib inline
from matplotlib import pyplot as plt
fig1 = plt.figure(figsize=(3,3))
plt.imshow(img1)
plt.title('image size: 28 X 28')
plt.show()
创建一个新数组
feature_size = img1.shape[0]*img1.shape[1]
X_train_format = X_train.reshape(X_train.shape[0],feature_size)
X_test_format = X_test.reshape(X_test.shape[0],feature_size)
print(X_train_format.shape)
归一化
X_train_normal = X_train_format/255
X_test_normal = X_test_format/255
输出结果转换
from keras.utils import to_categorical
y_train_format = to_categorical(y_train)
y_test_format = to_categorical(y_test)
print(y_train_format[0])

查看转换效果
print(X_train_normal.shape,y_train_format.shape)

设置模型
from keras.models import Sequential
from keras.layers import Dense, Activation
mlp = Sequential()
mlp.add(Dense(units=392,activation='relu',input_dim=784))
mlp.add(Dense(units=392,activation='relu'))
mlp.add(Dense(units=10,activation='softmax'))
mlp.summary()

模型配置
mlp.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['categorical_accuracy'])
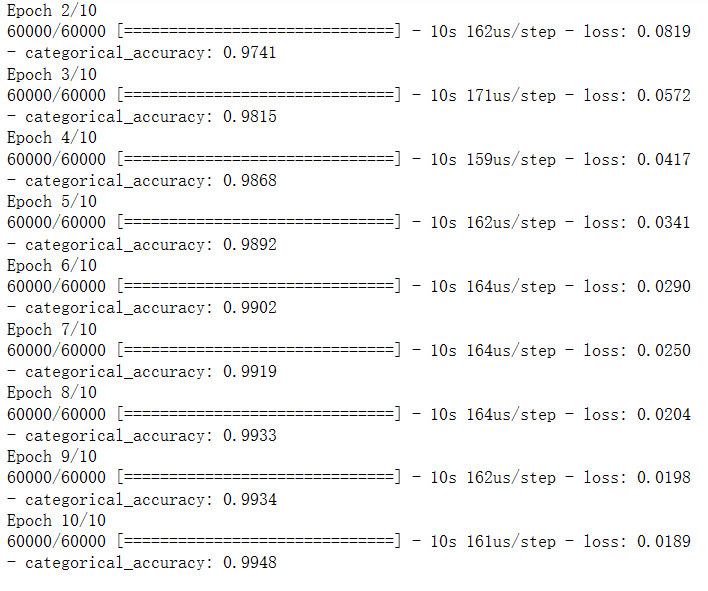
训练
mlp.fit(X_train_normal,y_train_format,epochs=10)
评估模型
y_train_predict = mlp.predict_classes(X_train_normal)
print(type(y_train_predict))
print(y_train_predict[0:10])
from sklearn.metrics import accuracy_score
accuracy_train = accuracy_score(y_train,y_train_predict)
print(accuracy_train)
y_test_predict = mlp.predict_classes(X_test_normal)
accuracy_test = accuracy_score(y_test,y_test_predict)
print(accuracy_test)

查看结果、
img2 = X_test[100]
fig2 = plt.figure(figsize=(3,3))
plt.imshow(img2)
plt.title(y_test_predict[100])
plt.show()

img2 = X_test[19]
fig2 = plt.figure(figsize=(3,3))
plt.imshow(img2)
plt.title(y_test_predict[19])
plt.show()

# coding:utf-8
import matplotlib as mlp
font2 = {'family' : 'SimHei',
'weight' : 'normal',
'size' : 20,
}
mlp.rcParams['font.family'] = 'SimHei'
mlp.rcParams['axes.unicode_minus'] = False
a = [i for i in range(1,10)]
fig4 = plt.figure(figsize=(5,5))
for i in a:
plt.subplot(3,3,i)
plt.tight_layout()
plt.imshow(X_test[i])
plt.title('predict:{}'.format(y_test_predict[i]),font2)
plt.xticks([])
plt.yticks([])

环境版本
| numpy | 1.20.3 |
|---|---|
| matplotlib | 3.4.3 |
| pandas | 1.3.4 |
| keras | 2.6.0 |
| scikit-learn | 0.24.2 |
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!