【面试八股文】每日一题:hashmap源码面试21连问?
1、hash概念??
任意长度的输入->固定长度的输出
2、hash冲突???
抽屉原理??无法避免
3、稍微好一些的hash算法,应该考虑的点
要尽可能的分散,因为在table中slot大部分都处于空闲状态时,要尽可能降低hash冲突
4、数据结构
jdk8为例 数组+链表+红黑树??
每个数据单元都是一个node结构
node结构中有key、value、hash、next
next字段就是发生hash冲突的时候,当前桶位中的node与冲突的node连成一个链表要用的字段
5、创建hashmap的时候,没有指定散列表数组长度,初始长度为?
16
jdk7
public HashMap() {
????????this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
jdk8
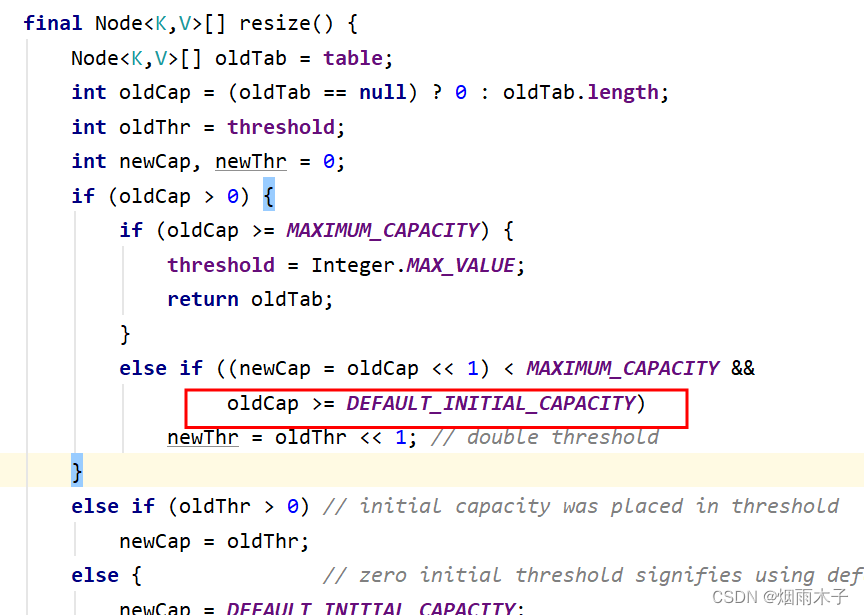
6、说说负载因子
默认为0.75,负载因子作用是计算扩容阈值用的,比如说使用无参构造方法创建的hashmap对象,默认情况下,扩容阈值就是16*0.75 =12
7、链表转化为红黑树需要达到什么条件
有两个指标,一个是链表长度达到8,还有一个是当前散列表数组长度已经达到64,否则的话就算slot内部链表长度已经达到8,它也不会转树,它仅仅会发生一次resize,散列表扩容
8、node对象内部有一个hash字段,hash字段的值是key对象的hashcode()返回值吗?
不是的,是h=key.hashcode() 而成加工得到的
hash=h^(h>>>16)
9、为啥要hash=h^(h>>>16)?
第一点,散列表的长度必须是2的次方数,比如16,32,64....
寻址算法是hash&(table.length-1)
(n-1) 与hash 会更加散列
如果用n与hash??会只有两种结果
10、为什么采用高低位异或?
采用高低位异或,主要是优化hash算法
因为hashmap散列表大多数情况下,它不会特别大
也就是说table.length-1得到的二进制数,实际有效位很有限
一般都在低16位内,这样的话,hash值高16位就等于完全浪费了,没起到作用
11、put写数据流程?
一共四种情况把
第一种? slot==null
把当前put方法传进来的key和value包装成一个node对象,放入slot就可以
第二种? slot!=null? 并且它引用的node还没有链化
需要先对比node对象的key和当前put对象的key是否完全相等,如果完全相等,这个操作就是替换操作。否则的话就是hash冲突了,然后在slot->node后面追加一个node就可以了,采用尾插法。
第三种? slot内的node已经链化
迭代查找node,需要先对比node对象的key和当前put对象的key是否完全相等,如果完全相等,这个操作就是替换操作。否则的话就是hash冲突了,然后在slot->node后面追加一个node就可以了,采用尾插法。还需要检查一下链表长度,有没有达到树化阈值。达到的话调用一个树化方法
第四种? 冲突很严重的情况下,链已经转化为红黑树了
12、说一下,红黑树写入操作的第一部分把,就是说找到它父节点的流程把
先从treenode说起,它继承了node结构,在node基础上增加了几个字段,指向父节点parent,指向左子节点、指向右子节点的right.红黑树的插入操作,首先是找到一个合适的插入点,就是找到插入节点的父节点,红黑树满足二叉树排序树的所有特性,这个找父节点的操作和二叉排序树完全一致,每次向下查找一层就可以排除一半的数据,左子树或者右子树为null,说明整个树中,它没有发现node-key与当前put-key一致的treenode,此时探测节点就是插入父节点所在了,然后当前插入节点插入到父节点的左子树或者右子树,然后根据这个插入节点的hash值和父节点hash值大小决定左右的,插入会打破平衡,还需要一个红黑树的平衡算法。第二种情况是向下探测过程中?发现node-key与当前put-key一致的treenode,这届repalce
13红黑树的原则?
构成树的节点有一个颜色属性,要么黑,要么红
第二个 根节点必须是黑色的
第三条? 从叶节点到根节点的路径上,它每条路径黑色节点它一定一致,俗称黑高
第四条? 不能有两个红色节点相连,也可以推导出两个子节点一定是黑色节点
叶子节点一定是黑色的 (叶子节点=NIL节点)
还有一点,一定是红插,就是新的节点一定是红色的,红插的话有优势,碰到父节点是黑色的话,树不会失衡,如果是黑插,就一定会失衡(树违法红黑树规则)
14、左旋和右旋
15、jdk8 hashmap 为什么要引入红黑树?
主要解决hash冲突导致链化严重的问题
jdk7的时候,当这个slot链化非常严重的时候,影响get查询效率,本身散列表最理想的查询效率为
o(1),链化严重会导致查询退化为o(n),所以才引入红黑树,一颗特殊的二叉排序树,
16、为什么链化后性能就变低了?
因为链表毕竟不是数组,它从内存角度来看,它没有连续着,查询的时候,如果在某位,必须一个一个next 过去,非常耗费性能
17、什么情况下触发扩容呢?
写数据之后,可能会触发扩容,hashmap结构内,有个记录当前数据量的字段。数据量字段达到扩容阈值的话,它就会触发扩容
18、扩容后会扩容多大,这块算法咋样?
扩容规则是这样的,因为table数组长度必须是2的次方数,扩容其实是,每次都是按照上一次tablesize位移运算得到的,做一次左移运算16<<1=32
19、为什么采用位移运算、咋不直接乘以2?
主要因为性能吧,因为cpu毕竟它不支持乘法运算,所有的乘法运算最终都是在指令层面为了加法实现的,效率很低,如果用位运算的话对cpu来说就非常的简单高效,效率很高。
20、那创建新的扩容后的table数组,老数据怎么迁移?
迁移其实就是,挨个桶位推进迁移,一个桶位一个桶位的处理,主要还是看当前处理桶位的数据状态吧
大概分了四种状态:
一共四种情况把
第一种? slot==null
不用处理
第二种? slot!=null? 并且它引用的node还没有链化
当迁移的时候发现slot中存储的这个node节点,它的next是null的时候,,说明这个slot还没有发生hash冲突,直接迁移就好了,根据新表的tablesize计算出它在新表的位置,然后存放过去就ok
第三种? slot内的node已经链化
迁移发现它这个next字段,这个node->next字段它不是null,说明这个slot发生过hash冲突,
这个时候需要把当前slot中保存的这个链表,拆成两个链表,分别是高位链和低位链,
所有的node->hash字段转化为二进制后,低位都是相同的,低位指的就是老表的tablesize-1 转化出来的二进制的有效位,如15就是1111,目前这个链表的低位一定是相同的,但是高位不一定,如下key.hashcode&newtable.length-1
元素放到index或index+oldtab.length
第四种? 冲突很严重的情况下,链已经转化为红黑树了
21、红黑树的扩容吧?
红黑树节点对象,这个treenode结构,依然保留了next字段,红黑树结构内部维护链表,查询的时候不用,但是新增或者删除的时候需要维护,这个链表就是说,方便split拆分这个红黑树时去用的,处理和普通的node链表一样,也就是根据高低位拆分成高位链和低位链,高位链要存放到新表,不同的是拆分出来的链表要看一下长度,若小于等于6,直接将treenode转化为普通的node链表,然后放到扩容后的新表就可以了,如果拆分出来的链表>6,还是需要把链表升级成红黑树的(其实就是重建红黑树)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 209. 长度最小的子数组
- SwinTransformer
- 【C++】POCO学习总结(十八):XML
- 【Java基础概述-7】详说Java中的异常Throwable。
- 统计数字字符个数
- KT148A语音芯在智能锁语音提示的优势在哪里成本还是性能
- 杨中科 EFCORE 第四部分 命令详解56-61
- 人工智能 AI 如何让我们的生活更加便利
- Markdown学习
- 【安装配置vue最详细的方法】检查vue版本时,报错“‘vue’ 不是内部或外部命令,也不是可运行的程序或批处理文件”