Druid 分析jpa批量插入
Druid是阿里巴巴开发的号称为监控而生的数据库连接池,在功能、性能、扩展性方面,都超过其他数据库连接池,包括DBCP、C3P0、BoneCP、Proxool、JBoss DataSource等,秒杀一切。
Druid 可以很好的监控 DB 池连接和 SQL 的执行情况,天生就是针对监控而生的 DB 连接池。
Druid 是一个 JDBC 组件,它包括三部分:?
-
DruidDriver 代理 Driver,能够提供基于 Filter-Chain 模式的插件体系。?
-
DruidDataSource 高效可管理的数据库连接池。?
-
SQLParser?
Druid 可以做什么??
? ? ? ? 可以监控数据库访问性能,Druid 内置提供了一个功能强大的 StatFilter 插件,能够详细统计 SQL 的执行性能,这对于线上分析数据库访问性能有帮助。?
? ? ? ? 替换?DBCP?和?C3P0。Druid 提供了一个高效、功能强大、可扩展性好的数据库连接池。?
? ? ? ? 数据库密码加密。直接把数据库密码写在配置文件中,这是不好的行为,容易导致安全问题。DruidDruiver 和 DruidDataSource 都支持 PasswordCallback。?
? ? ? ?SQL 执行日志,Druid 提供了不同的 LogFilter,能够支持?Common-Logging、Log4j?和 JdkLog,你可以按需要选择相应的 LogFilter,监控你应用的数据库访问情况。?
? ? ? ? 扩展 JDBC,如果你要对 JDBC 层有编程的需求,可以通过 Druid 提供的 Filter-Chain 机制,很方便编写 JDBC 层的扩展插件。?
? ? ? ? 今天在对大批量数据(万级别)插入做性能优化时,需要用到Druid的SQL监控功能,在此记录一下。
我们都知道jpa提供saveAll处理批量插入,代码如下
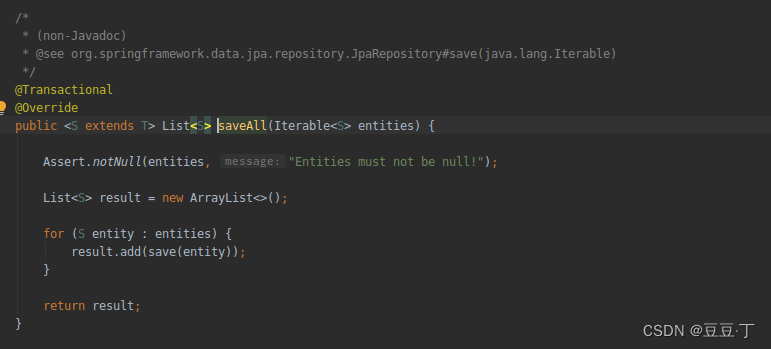
重代码上看似乎是一个一个的save,其实不然,查看源码(这里不细说了),jpa每次save都会先添加到action queue,在flush的时候,再通过insert action构造statement的batch操作,然后到达一个批量的时候才perform,达到一个batch的时候会调用executeBatch()。
也就是说,最终还是使用了jdbc statement的executeBatch的调用模式
如何使用批量处理,添加如下配置
spring.datasource.url = jdbc:postgresql://xxxx:5432/juslink_warehouse_order_ubnt?reWriteBatchedInserts=true
#Jpa批量更新配置
spring.jpa.properties.hibernate.jdbc.batch_size = 200
spring.jpa.properties.hibernate.jdbc.batch_versioned_data = true
spring.jpa.properties.hibernate.order_inserts = true使用Druid需要添加依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
</dependency>加入配置:
spring.datasource.druid.stat-view-servlet.enabled=true
spring.datasource.druid.filter.stat.enabled=trueDruid的监控界面如图:

下面来看看开启批处理和未开启时1万条数据插入的情况:
未开启测试结果
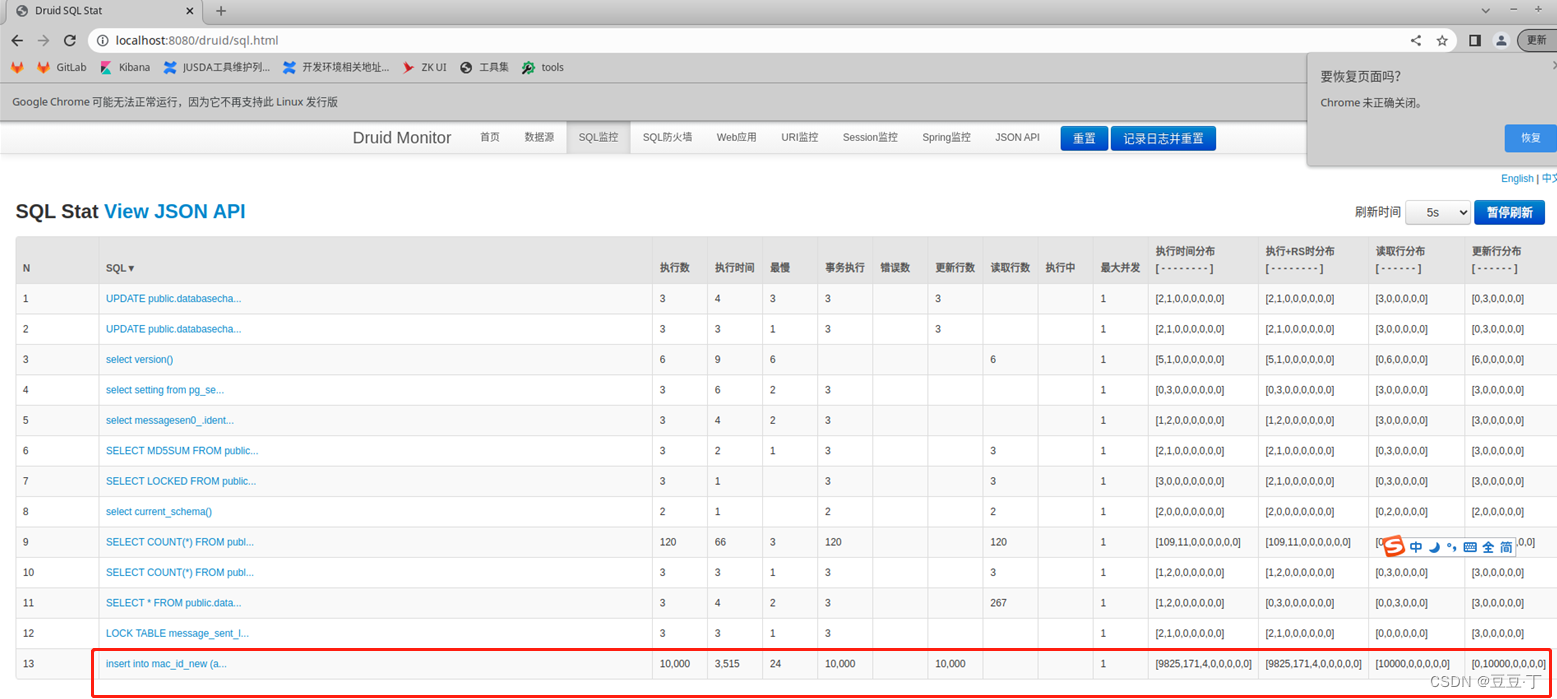
开启测试结果

结论:从上面两张实验图中可以看出,未开启批量处理,插入1万条数据用时在3.5s;开启批量处理后,耗时为0.45s,开启之后整体效率提升了大约7~8倍
批量操作的数量需要经过多次测试取最优值
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- CAPL入门到精通之CAPL Functions(四) 上 - 字符串函数介绍(部分)
- 【Python百宝箱】离经叛道:探索离群值的科学与艺术
- 聚道云连接器实现泛微OA与金蝶EAS对接,助力企业实现数字化转型
- 如何给图数据库 NebulaGraph 新增一种数据类型,以 Binary 为例
- Qt Q_DECL_OVERRIDE
- 2023年终总结
- 计算图与动态图机制
- thumbnailator压缩图片添加水印cmyk格式图片转换,图片位深度,gif图片
- 【计算机网络】网络基础
- c语言:求1/2+2/3+3/4+……n-1/n的和|练习题