金融OCR领域实习日志(一)
一、OCR基础
任务要求:

工作原理
OCR(Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相)检查纸上打印的字符,经过检测暗、亮的模式肯定其形状,而后用字符识别方法将形状翻译成计算机文字的过程;即,针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并经过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。如何除错或利用辅助信息提升识别正确率,是OCR最重要的课题,ICR(Intelligent Character Recognition)的名词也随之产生。
一般技术流程为:

应用场景
根据OCR的应用场景而言,我们可以大致分成识别特定场景下的专用OCR以及识别多种场景下的通用OCR。就前者而言,证件识别以及车牌识别就是专用OCR的典型案例。针对特定场景进行设计、优化以达到最好的特定场景下的效果展示。那通用的OCR就是使用在更多、更复杂的场景下,拥有比较好的泛性。在这个过程中由于场景的不确定性,比如:图片背景极其丰富、亮度不均衡、光照不均衡、残缺遮挡、文字扭曲、字体多样等等问题,会带来极大的挑战。
**文档文字识别:**可以将图书馆、报社、博物馆、档案馆等的纸质版图书、报纸、杂志、历史文献档案资料等进行电子化管理,实现精准地保存文献资料。
**自然场景文字识别:**识别自然场景图像中的文字信息如车牌、广告干词、路牌等信息。对车辆进行识别可以实现停车场收费管理、交通流量控制指标测量、车辆定位、防盗、高速公路超速自动化监管等功能。
**票据文字识别:**可以对增值税发票、报销单、车票等不同格式的票据进行文字识别,可以避免财务人员手动输入大量票据信息,如今已广泛应用于财务管理、银行、金融等众多领域。
**证件识别:**可以快速识别身份证、银行卡、驾驶证等卡证类信息,将证件文字信息直接转换为可编辑文本,可以大大提高工作效率、减少人工成本、还可以实时进行相关人员的身份核验,以便安全管理。
以及金融领域具体应用场景:
**自动化文档处理:**通过OCR技术识别和提取文档关键信息后,利用关键信息进行文档分类、文档重命名、目录创建与归档工作
**发票识别:**文字检测+识别,根据发票内容信息特点提取所需的内容。
**合同分析:**通过OCR识别,智能结构化抽取合同关键信息,支持图片、PDF、word多种格式,可通过API接口传输至企业业务系统,协助企业工作人员完成自动填单、内容一致性检查,让合同审阅更高效。
★商业化方案及其优缺点
1.paddleOCR
飞桨首次开源文字识别模型套件PaddleOCR,目标是打造丰富、领先、实用的文本识别模型/工具库。最新开源的超轻量PP-OCRv3模型大小仅为16.2M。同时支持中英文识别;支持倾斜、竖排等多种方向文字识别;支持GPU、CPU预测;用户既可以通过PaddleHub很便捷的直接使用该超轻量模型,也可以使用PaddleOCR开源套件训练自己的超轻量模型。
-
优点
-
轻量模型,执行速度快
-
支持pip直接安装
-
ocr识别效果好,效果基本可以比肩大厂收费ocr(非高精版)
-
支持表格和方向识别
-
支持补充训练且很方便
-
-
缺点
-
部分符号识别效果一般,如 '|‘识别为’1’
-
对于部分加粗字体可能出现误识别,需要自己补充训练
-
偶尔会出现部分内容丢失的情况
-
源文档配套教程:安装使用说明
2.CnOCR
CnOCR 是 Python 3 下的文字识别(Optical Character Recognition,简称OCR)工具包,支持简体中文、繁体中文(部分模型)、英文和数字的常见字符识别,支持竖排文字的识别。自带了20+个训练好的识别模型,适用于不同应用场景,安装后即可直接使用。同时,CnOCR也提供简单的训练命令供使用者训练自己的模型。
- 优点
- 轻量模型,执行速度快,速度略快于paddle ocr
- 支持pip直接安装
- ocr识别效果好,识别效果比肩paddle ocr
- 支持训练自己的模型
- 缺点
- 部分符号识别效果差
- 部分场景下会出现空格丢失情况
- 模型补充训练没有paddle ocr方便
源文档配套教程:安装使用说明
3.chinese_lite OCR
超轻量级中文 ocr,支持竖排文字识别, 支持 ncnn、mnn、tnn 推理, 模型大小仅4.7M。
-
优点
-
轻量模型,执行速度快,速度优于CnOCR和Paddle OCR
-
ocr识别效果尚可,优于一般开源模型,但比不上CnOCR和Paddle OCR
-
作者提供了多种语言下的Demo
-
-
缺点
- 不支持pip安装
- 文本位置识别略差
- 不支持补充训练
- 类手写字体识别效果一般
- 部分场景下会出现误识别竖版文字的情况
例如:
姓 名: 张三
性 别: 男
年 龄: 19
户 籍: 北京
误识别为 '姓性年户'
原文配套:安装使用说明
4.EasyOCR
EasyOCR是一个用于从图像中提取文本的python模块。它是一种通用的OCR,可以读取自然场景文本和文档中的密集文本。我们目前正在支持80多种语言并不断扩展。
-
优点
-
支持pip安装,但需要自己手动下载模型
-
ocr识别效果尚可,优于一般开源模型
-
-
缺点
-
速度很慢,900 * 1200像素图片平均需要30s左右
-
不支持补充训练
-
5.Tesseract OCR
Tesserat OCR 是一款可在各种操作系统运行的 ,由Google开发的OCR引擎。它可以免费使用,并支持多种语言。虽然它没有一个官方的云工具,但是它可以集成到各种编程语言和应用程序中,因此可以很容易地创建自己的OCR云工具。
-
优点
- 支持补充训练
-
缺点
-
安装使用困难,不支持pip安装,官网下载配置教程(Tesseract-OCR 下载安装和使用)
-
中文识别效果差
-
6.Google Vision API
Google Cloud Vision API是谷歌提供的云端视觉分析服务,可以通过API调用来实现图像分析、OCR文字识别等功能。相比于Tesseract OCR,它具有更强大的图像分析能力和更便捷的使用方式。
总结
paddle ocr和cnocr,两者都能实现商业化精准度。其中cnocr执行速度快,速度略快于paddle ocr识别效果比肩paddle ocr,但paddle ocr模型补充训练方便
某些场景下,如小图片且对速度要求较高可以尝试使用chinese_lite ocr.
此外由部分stackoverflow用户反馈可知paddle和Tesseract的区别如下:
-
数据来源区别:Tesseract对印刷体扫描文档效果更好,paddle更适用于手写体等场景,但二者都支持训练
-
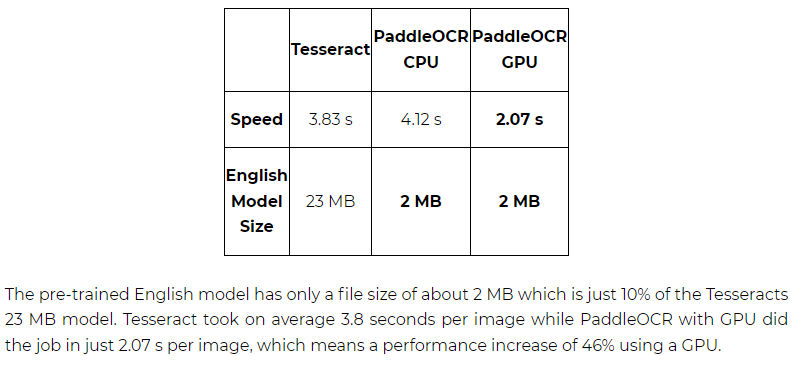
速度区别:CPU情况下T优于P,但paddle在GPU支持下比Tesseract速度快出一大截
-
预处理区别:如果不提供预处理(例如二值化),对RGB图像而言,paddle的效果优于Tesseract。在二值化情况下Tesseract的长文本效果通常优于paddle
-
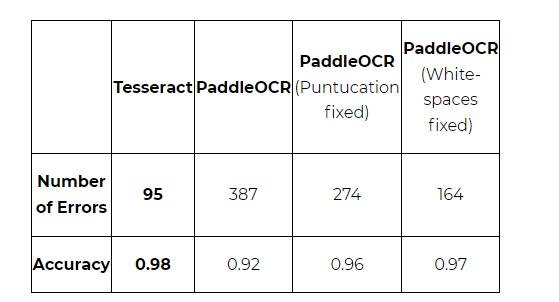
正确率&精度差别:T的表现略高于P,主要原因是paddle主要有单词和标点之间缺少空格的问题,但易于纠正,在后处理算法之后精度与Tesseract相当。且非90度旋转中表现良好。
-
模型大小:P的轻量级模型大小为2MB左右,T则为23MB左右
-
数据安全:……
某个国外帖子显示的数据:
技术难点
1.不同拍摄角度:指通过正拍、斜拍和图像反转等不同角度进行拍摄;
2.不同光线:指在亮光(可能会出现反光)、暗光和部分亮光部分暗光的情形下拍摄;
3.文字不清晰:指存在因污损、遮挡、折痕、印章、背景纹理等造成文字不清楚的样本;
4.边框不完整:主要指图片样本中物体(证件、票据、车牌等)边框没有完整出现在画面中;
5.其他特殊情况:主要指卡证类样本需考虑带有少数民族文字、生僻字,同时考虑到证件等用于高安全场景,对复印、扫描、屏幕翻拍、PS等样本进行告警;印刷体样本需考虑不同字号、不同排版方向,以及弯曲的文本。
评价指标
OCR评价指标包括字段粒度和字符粒度的识别效果评价指标。
- 以字段为单位的统计和分析,适用于卡证类、票据类等结构化程度较高的OCR应用评测。
- 以字符(文字和标点符号)为单位的统计和分析,适用于通用印刷体、手写体类非结构化数据的OCR应用评测。具体指标包括以下几个:


此外,从服务角度来说,识出率(准确率)、平均耗时(处理速度)、数据安全等也是衡量OCR系统好坏的指标之一。
参考文档
使用Tesseract OCR、Google Cloud Vision API的区别
Stack Overflow:与Tesseract相比,PaddleOCR的性能如何
Put to Test: PaddleOCR Engine Example and Benchmark
csdn:PaddleOCR训练属于自己的模型详细教程(从打标,制作数据集,训练到应用,以行驶证识别为例)
利用OCR解决增值税发票内容文本识别:涉及paddleOCR,区域分割,视平面变换
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- TMC2209不同测试地址
- 黑马程序员JavaWeb开发|原理篇
- 2023年金三银四网络安全考试试题
- Guava精讲(三)-Caches,同步DB数据到缓存
- hash应用
- 寒假学习打字:提前实现弯道超车
- Docker登录MySQL,密码正确却提示密码错误
- TypeError: unsupported operand type(s) for +: ‘NoneType‘ and ‘str‘
- 浅谈ASO优化行业未来的发展趋势
- SEO中的实体:它们是什么以及为什么它们很重要?