详解MySQL中一条SQL执行过程
MySQL基本架构
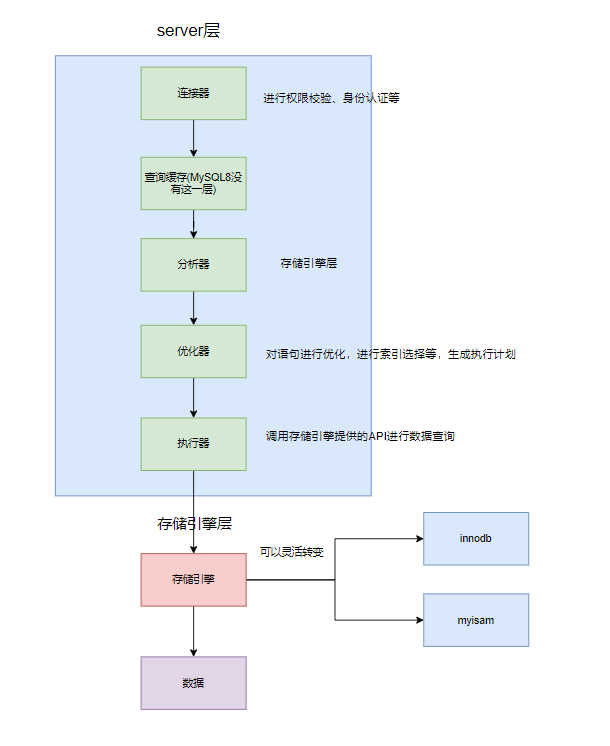
如下图所示,从宏观角度来说MySQL架构可以分为server层和存储引擎层,其中Server层包含如下:
- 连接器:进行身份认证和权限相关校验。
- 查询缓存:MySQL8.0已废弃,查询缓存主要是用于提高查询效率而加的一层缓存。
- 分析器:对SQL执行动作、语法、词法进行分析。
- 优化器:对要被执行的SQL进行优化。
- 执行器:执行SQL查询语句,然后从存储引擎返回结果。
接下来说说存储引擎,对于MySQL而言存储引擎是支持插拔的,常见的存储引擎有myisam、innodb、memory,而MySQL默认的使用的是innodb。
详解MySQL各层的工作分工
MySQL客户端和服务端的通信协议
对于MySQL而言,客户端和服务端之间采用的是一种半双工的通信协议,这样就意味着同一时刻要么客户端向服务端发送数据,要么服务端向客户端发送数据。这意味着客户端必须完整的收到服务端响应的数据才能断开连接。
这个交互流程也在告诉我们,进行大量数据查询的时候,若无必要尽可能使用limit进行分页查询,避免这种全双工的通信方式导致客户端接收导致资源长时间的占用。

连接器
主要判断用户登录的账户密码是否正确,如果账户密码都正确,则进行权限查询,注意在本次连接期间只要不断开,无论外界如何修改权限,这个会话的权限都是以连接器查询到的为主。
查询缓存
MySQL8已经废弃的功能,这个功能常用于结果的缓存复用以提高查询性能,例如我们进行select * from table where id=1的查询。第一次发现缓存中没有,就从数据库中查出来并放到缓存中下次可以在复用。
MySQL8之所以废弃是因为数据库中的数据经常更新导致缓存失效,就需要清空这个缓存,这期间和开销是非常没必要的,所以索性废掉这个功能。
分析器
分析器主要是负责sql解析和预处理,它会将客户端发来的查询一句进行解析生成一颗解析树,然后解析器根据自定义规则对sql语句进行词法和语法分析。
- 词法分析:分析关键字是否拼写有误,并通过关键字判断这条SQL做什么。
- 语法分析:对这条SQL语句的语法进行检查。
优化器
分析器分析无误之后,说明这条语句是可以正常执行的。MySQL优化器就会通过分析找出成本最小的一种方式生成执行计划,交由执行器执行。
对此,我们这里不妨补充一下MySQL能够自己处理的一些优化类型:
- 将外连接转为内连接:某些场景之下,我们可能会用到外连接,但是在where或者库表结构的调整之后,我们的左外连接后者右外连接可能不存在null的连接。
例如下面这段sql,我们对table2进行左外连接,但是我们条件关联之后,table1对应的id值在table2中都有,那么查询优化器可能就会对其进行优化,会将其转换为内连接,更加精确的去匹配索要查询的行避免没必要的扫描。
SELECT *
FROM table1
LEFT JOIN table2
ON table1.id = table2.id;
举个例子,上面的sql如果table1对应的id在table2中都有,那么sql语句就会变成这样
SELECT *
FROM table1
LEFT JOIN table2
ON table1.id = table2.id
WHERE table2.id IS NOT NULL;
然后优化器就会将其优化成这样
SELECT *
FROM table1
inner JOIN table2
ON table1.id = table2.id
WHERE table2.id IS NOT NULL;
-
使用代数等价变换规则,例如我们的查询条件是
5=5 and a>5,那么MySQL就会将其优化为:a>5,再比如说我们有这样一条SQL,条件语句为(a<b and b=c) and a=5,那么MySQL就会将其优化为:b > 5 and b=c -
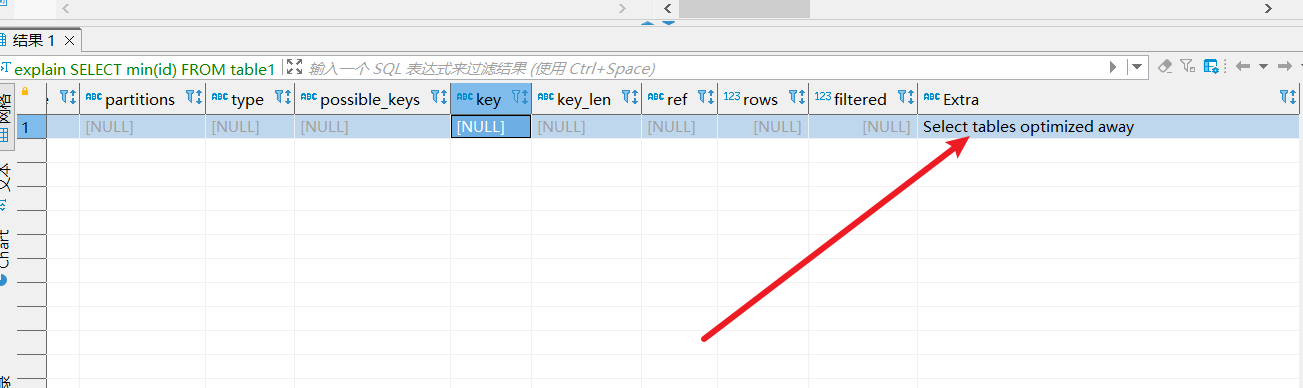
优化min、max,对于建立索引的数据表来说,使用索引所在列的进行最大值和最小值查询时,MySQL优化器会将这种sql判定为常数查询,例如笔者建立的下面这张表,我们将table1的id设置为索引。
然后查询下面这句sql:
SELECT min(id)
FROM table1;
使用explain查看其执行计划,可以看到执行计划显示Select tables optimized away,这就意味查询时它已经将表移除,而是用一个常数查询来代替。
- 预估并转为为常数表达式:最典型的例子就
select * from table1 where id=1+2,MySQL优化器就会将其转为select * fromt table1 where id=3。 - 索引扫描:这个无需多说,当要查询的列都包含在索引中时,无需进行回表查询,避免没必要的IO操作。
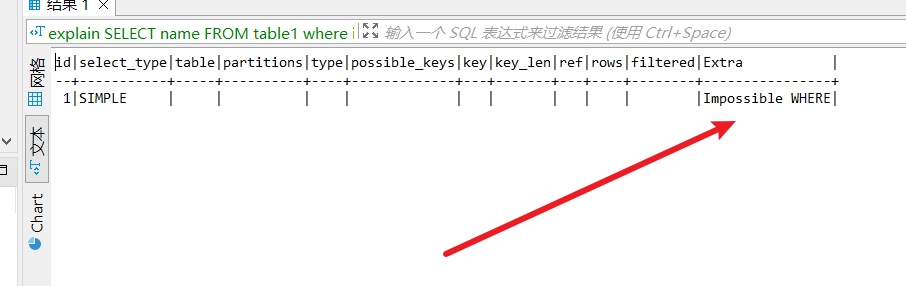
- 提前终止查询:对于limit查询而言,MySQL优化器会在查询到需要的数据时直接终止查询,还有一些比较特殊的,例如对于某些不可能的条件,MySQL优化器也会提前将其终止,例如我们将tbale1的id设置为主键,然后键入下面这句查询语句。
Select tables optimized away
那么执行计划就会显示Impossible WHERE从而提前终止查询:
执行器
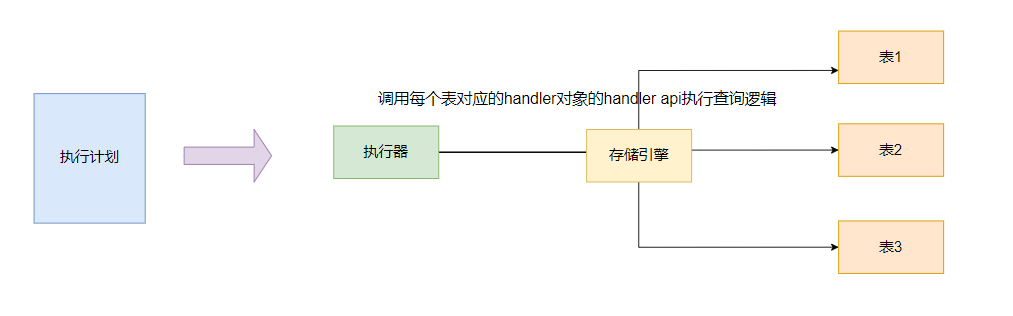
对用户进行权限校验,若权限校验不通过则报错,然后执行器就会根据优化器优化后的执行计划(这里的执行计划是一个数据结构),执行器根据这个数据结构顺序调用存储引擎提供的API进行数据查询,并将查询结果返回给客户端,从而完成一次完整的SQL查询。
用两条完整的sql走一遍上述的流程
了解SQL执行过程之后,我们不妨通过一个实际的例子带入一下了解全过程。
查询语句的执行流程
sql如下所示:
select * from table where b=1 and a=2;
按照我们上文所说的过程:
- 校验用户账户密码是否正确,查询权限
- 查询缓存(mysql8.0之前),若有数据则直接返回,反之下一步
- 分析器进行词法、语法分析。
- MySQL优化器进行优化,以本SQL为例,假如我们创建了一个
联合索引(a,b),那么优化器就会遵循最左匹配原则将a,b条件进行调换。
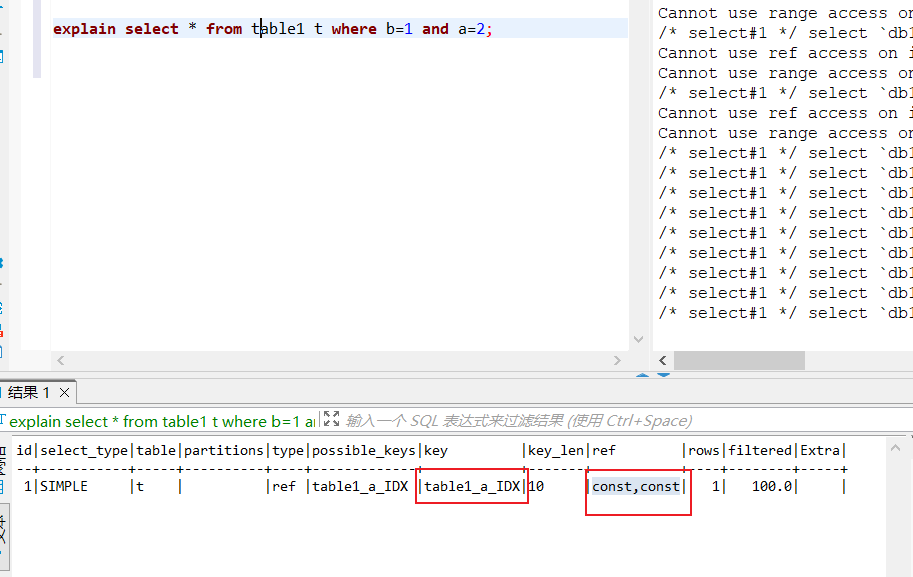
- 进行权限校验,若有权限执行器进行查询,将结果从引擎取出返回。
更新语句的执行流程
更新语句我们示例SQL如下:
update table set a=1 where b=1;
步骤还是一样:
- 连接器的工作,不多赘述
- 查询缓存,若有则直接操作这条数据
(mysql8不走这一步) - 分析器的工作,不多赘述
- 进行更新操作,首先调用引擎
API,将这个修改写入内存中,同时记录redo log,此时redo log是prepare状态,然后执行器执行操作,完成后提交事务成功,写入bin log,最后redo log更新为commit。 - 更新完成。
参考文献
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Chrome浏览器进程工作原理和机制
- Linux文本处理指令uniq-man帮助手册
- 深度学习中用来训练的train.py 探究学习2.0( 数据预处理)
- v-on、事件修饰符、v-model、一些常用指令
- 垂直赛道争夺头部大V,“快抖红微”错位竞争
- pgadmin4树节点增删查(三)
- 【测试岗】面经分享:大佬十二分钟拿到联通面试offer
- SARS-CoV-2 Spike IgG ELISA Kit (RUO)—Enzo Life Sciences
- 问题:github上不了,但是其他网页可以正常打开
- 智能助手的巅峰对决:ChatGPT对阵文心一言