R语言学习 case2:人口金字塔图
发布时间:2024年01月19日
step1:导入库
library(ggplot2)
library(ggpol)
library(dplyr)
step2:读取数据
data <- readxl::read_xlsx("data_new.xlsx", sheet = 1)
data
- readxl::read_xlsx() 是 readxl 包中的函数,用于读取Excel文件。
step3:数据转换
mydata <- data %>% select(1, 3, 4) %>%
reshape2::melt(id.vars = "Group", variable.name = "Sex", value.name = "Prop")
mydata <- data %>% select(1, 3, 4):select(1, 3, 4) 选择数据框 data 中的第1列、第3列和第4列。%>% reshape2::melt(id.vars = "Group", variable.name = "Sex", value.name = "Prop")reshape2::melt()函数用于将数据框从宽格式(wide format)转换为长格式(long format),这样更容易进行分析和可视化id.vars = "Group"指定 “Group” 列作为标识变量,即不进行融化的列。variable.name = "Sex"指定新生成的列的名称,该列包含了之前选择的列的列名(在这里是 “Sex”)。
step4:对称显示,取一半设置为负
mydata$Prop <- ifelse(mydata$Sex == "Male", mydata$Prop * -1, mydata$Prop)
-
ifelse(mydata$Sex == "Male", mydata$Prop * -1, mydata$Prop): -
mydata$Sex == "Male"是一个条件表达式,检查 “Sex” 列是否等于 “Male”。
如果条件为真,即 “Sex” 列的值是 “Male”,则执行 mydata$Prop * -1,将 “Prop” 列的值乘以 -1。如果条件为假,即 “Sex” 列的值不是 “Male”,则保持 “Prop” 列的值不变。
ifelse() 函数将根据条件逐元素地应用这个逻辑,生成一个新的列。
step5: 标签文本
mydata$label <- abs(mydata$Prop) %>% round(digits = 2)
head(mydata)
- 在数据框 mydata 中添加一个名为 “label” 的新列,该列包含 “Prop” 列的绝对值,并将结果取两位小数
step6: 绘图
plot <- ggplot(mydata, aes(Prop, Group, fill = Sex)) +
geom_col(width = 0.6, color = "black") +
geom_text(aes(label = label), size = 4) +
facet_share(~Sex, scales = "free_x", reverse_num = TRUE) +
#ggtitle("福建省2021年人口年龄构成") +
labs(x = "Prop(%)",
# 设置 x 轴标签为 "Prop(%)"
caption = "Source:福建省统计年鉴(2022)") +
scale_fill_brewer(palette = "Set1" ) +
theme_bw(base_size = 15) +
theme(axis.title.y = element_blank(),
plot.title = element_text(hjust = 0.5),
axis.text = element_text(colour = "black"))
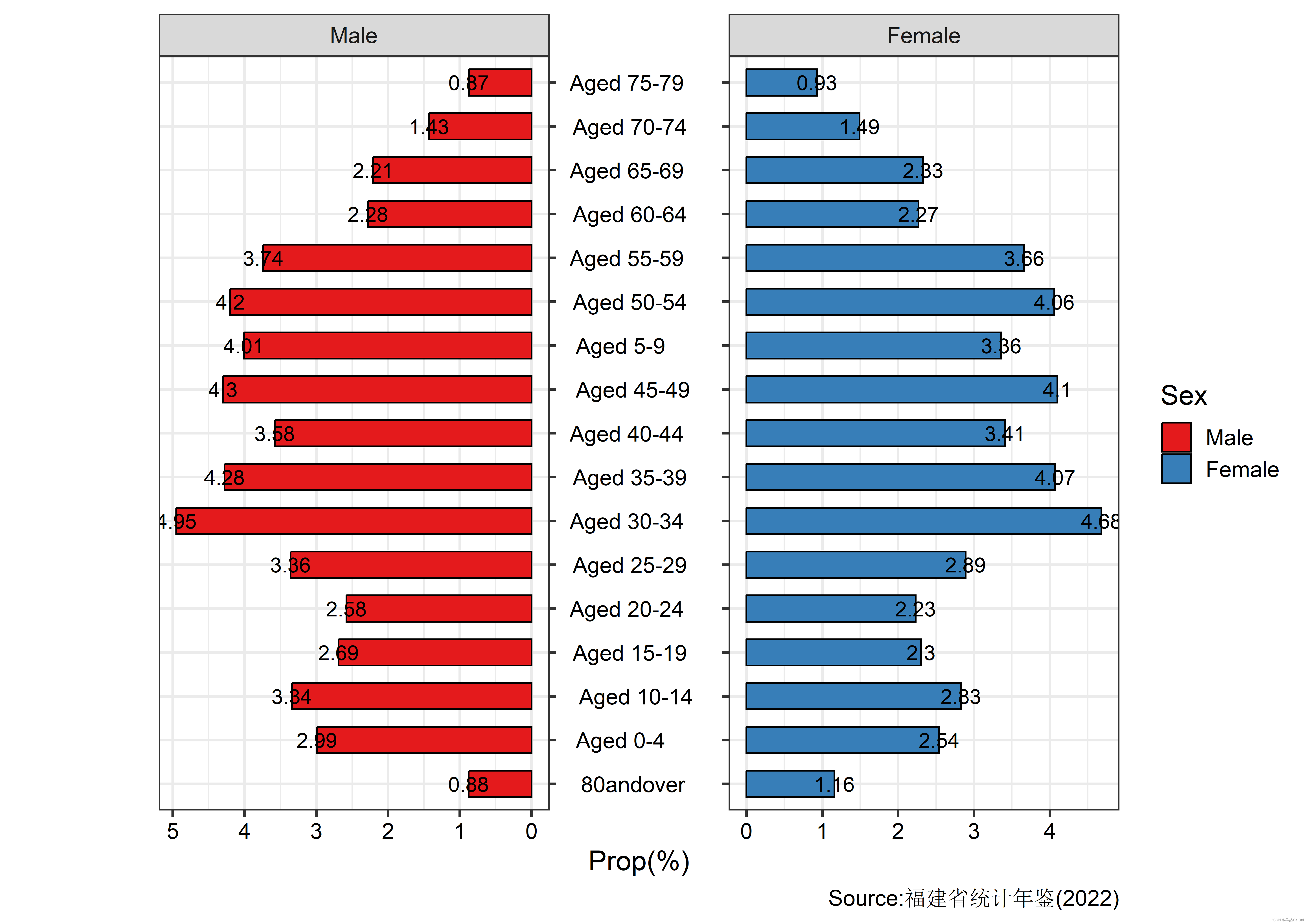
- facet_share() 进行分面
文章来源:https://blog.csdn.net/weixin_45492560/article/details/135706200
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 在CentOS中,对静态HTTP服务的性能监控
- python获取起始IP和结束IP的CIDR结果,python netaddr库介绍
- JSON的一些主要特点和使用方式
- cnPuTTY 0.80.0.1—PuTTY Release 0.80中文版本简单说明~~
- 【一】vue3的helloworld项目
- 新人入驻CSDN的第一天
- 光学雨量监测站比传统雨量站有哪些优势
- DataFunSummit:2023年知识图谱在线峰会-核心PPT资料下载
- Python——VScode安装
- HarmonyOS 编写副标题 解决 ubTitle 可能淘汰问题