【MYSQL】MYSQL 的学习教程(十)之 InnoDB 锁
数据库为什么需要加锁呢?
如果有多个并发请求存取数据,在数据就可能会产生多个事务同时操作同一行数据。如果并发操作不加控制,不加锁的话,就可能写入了不正确的数据,或者导致读取了不正确的数据,破坏了数据的一致性。因此需要考虑加锁。
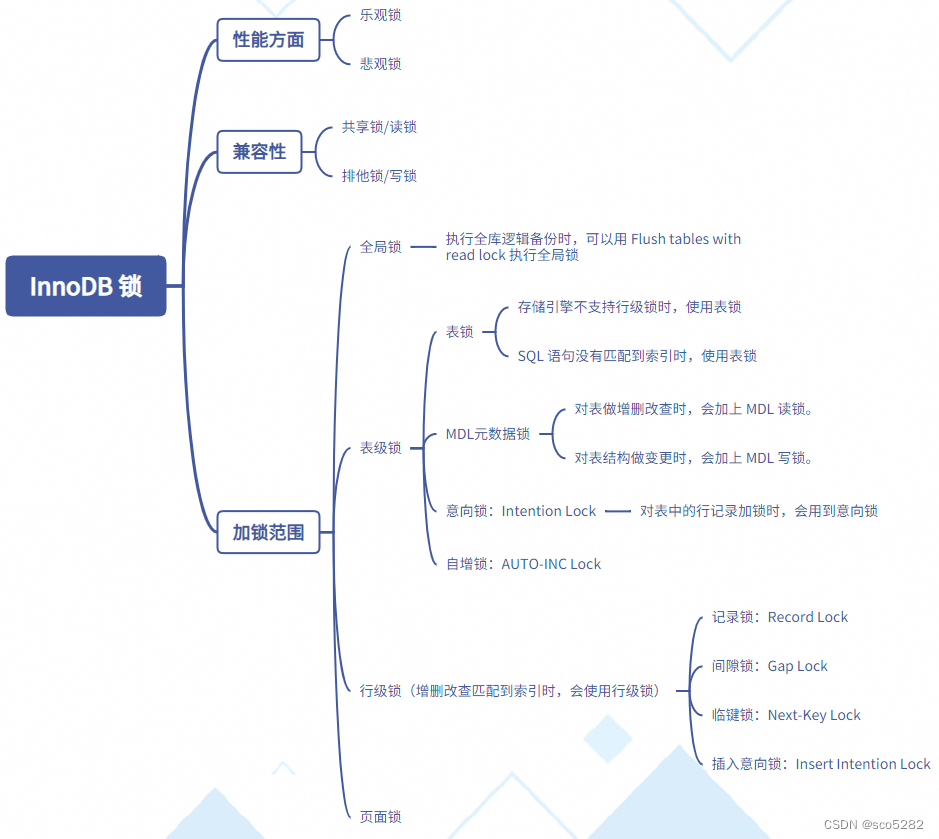
1. 乐观锁/悲观锁
在 MySQL 中,无论是悲观锁还是乐观锁,都是人们对概念的一种思想抽象,它们本身还是利用 MySQL 提供的锁机制来实现的。其实,除了在 MySQL 数据,像 Java 语言里面也有乐观锁和悲观锁的概念
- 悲观锁:悲观锁对于数据库中数据的读写持悲观态度,即在整个数据处理的过程中,它会将相应的数据锁定(加排他锁)。在数据库中,悲观锁的实现需要依赖数据库提供的锁机制,以保证对数据库加锁后,其他应用系统无法修改数据库中的数据
- 在悲观锁机制下,读取数据库中的数据时需要加锁,此时不能对这些数据进行修改操作。修改数据库中的数据时也需要加锁,此时不能对这些数据进行读取操作。
- 乐观锁:实现乐观锁的一种常用做法是为数据增加一个版本标识,如果是通过数据库实现,往往会在数据表中增加一个类似 version 的版本号字段
2. 共享/排他锁
InnoDB 实现了两种标准的行级锁:共享锁(简称 S 锁)、排他锁(简称 X 锁)
- 共享锁(Share lock):简称为 S 锁,也叫读锁,在事务要读取一条记录时,需要先获取该记录的 S 锁
- 加锁方式是:
select ... lock in share mode;或者select ... for share;
- 加锁方式是:
- 排他锁:简称 X 锁,也叫写锁或者独占锁,在事务需要改动一条记录时,需要先获取该记录的 X 锁
- 加锁方式是:
select ... for update;
- 加锁方式是:
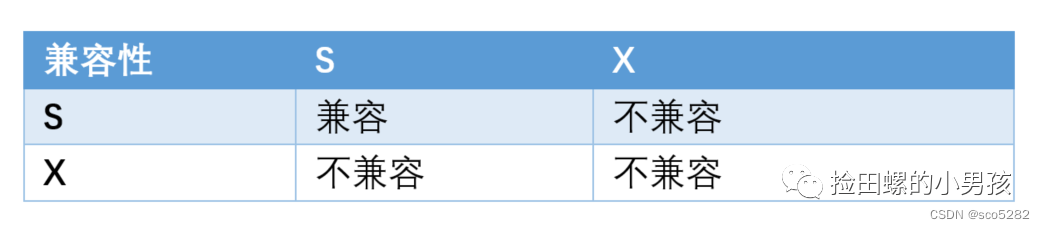
如果事务 T1 持有行 R 的 S 锁,那么另一个事务 T2 请求访问这条记录时,会做如下处理:
- T2 请求 S 锁立即被允许,结果 T1和T2都持有R行的S锁
- T2 请求 X 锁不能被立即允许,此操作会阻塞
如果 T1 持有行 R 的 X 锁,那么 T2 请求 R 的 X、S 锁都不能被立即允许,T2 必须等待 T1 释放 X 锁才可以,因为 X 锁与任何的锁都不兼容
S 锁和 X 锁的兼容关系如下图表格:
X 锁和 S 锁是对于行记录来说的话,可以称它们为行级锁或者行锁。我们认为行锁的粒度就比较细,其实一个事务也可以在表级别下加锁,对应的,我们称之为表锁。给表加的锁,也是可以分为 X 锁和 S 锁的
如果一个事务给表已经加了 S 锁,则:
- 别的事务可以继续获得该表的 S 锁,也可以获得该表中某些记录的 S 锁
- 别的事务不可以继续获得该表的 X 锁,也不可以获得该表中某些记录的 X 锁
如果一个事务给表加了 X 锁,那么:
- 别的事务不可以获得该表的 S 锁,也不可以获得该表某些记录的 S 锁。
- 别的事务不可以获得该表的 X 锁,也不可以继续获得该表某些记录的 X 锁。
3. 全局锁
全局锁:对整个数据库实例加锁。它是粒度最大的锁
①:加锁:在 MySQL 中,通过执行以下指令加全局锁:
flush tables with read lock
指令执行完,整个数据库就处于只读状态了,其他线程执行以下操作,都会被阻塞:
- 数据更新语句被阻塞,包括 insert, update, delete 语句;
- 数据定义语句被阻塞,包括建表 create table,alter table、drop table 语句;
- 更新操作事务 commit 语句被阻塞;
②:释放锁: MySQl 释放锁有 2 种方式:
- 执行
unlock tables命令 - 加锁的会话断开,全局锁也会被自动释放
③:使用场景
全局锁的典型使用场景是做全库逻辑备份,在备份过程中整个库完全处于只读状态
问题:
- 假如在主库上备份,备份期间,业务服务器不能对数据库执行更新操作,因此涉及到更新操作的业务就瘫痪了;
- 假如在从库上备份,备份期间,从库不能执行主库同步过来的 binlog,会导致主从延迟越来越大,如果做了读写分离,那么从库上获取数据就会出现延时,影响业务
使用全局锁进行数据备份,不管是在主库还是在从库上进行备份操作,对业务总是不太友好
不加锁会产生错误,加全局锁又会影响业务,那么有没有两全其美的方式呢?
有:MySQL 官方自带的逻辑备份工具 mysqldump,具体指令如下:
mysqldump –single-transaction
执行该指令,在备份数据之前会先启动一个事务,来确保拿到一致性视图, 加上 MVCC 的支持,保证备份过程中数据是可以正常更新。但是,single-transaction 方法只适用于库中所有表都使用了事务引擎,如果有表使用了不支持事务的引擎,备份就只能用 FTWRL 方法
4. 表级锁
MySQL 表级锁有四种:
- 表锁
- DML 元数据锁
- 意向锁:Intention Lock
- 自增锁:AUTO-INC 锁
4.1 表锁
表锁就是对整张表加锁,包含读锁和写锁,由 MySQL Server 实现。
大多数情况下,锁的管理(包括获取和释放)都是由 MySQL 系统自动处理的,用户不需要显式地进行操作。这主要是在执行查询或更新语句时发生的。然而,有时候可能需要显式地进行锁定操作。
表锁需要显示加锁或释放锁,具体指令如下:
# 给表加写锁
lock tables tablename write;
# 给表加读锁
lock tables tablename read;
# 释放锁
unlock tables;
# 查看数据表上增加的锁
show open tables;
-
读锁:代表当前表为只读状态,读锁是一种共享锁
- 加锁线程只能对当前表进行读操作,不能对当前表进行更新操作,不能对其它表进行所有操作
- 其它线程只能对当前表进行读操作,不能对当前表进行更新操作,可以对其它表进行所有操作
-
写锁:写锁是一种独占锁
- 加锁线程对当前表能进行所有操作,不能对其它表进行任何操作;
- 其它线程不能对当前表进行任何操作,可以对其它表进行任何操作;
特点:
- 开销比较小,加锁速度快,一般不会出现死锁,
- 锁定的粒度比较大,发生锁冲突的概率最高,并发度最低
那什么时候会使用表锁呢?
- 对应的存储引擎没有行级锁(例如:MyIASM)
- 对应的 SQL 语句没有匹配到索引,那么此时也是会全表扫描
4.2 MDL 元数据锁
元数据锁:metadata lock,简称 MDL,它是在 MySQL 5.5 版本引进的。元数据锁是在访问表时被自动加上,以保证读写的正确性。
加锁和释放锁规则如下:
- MDL 读锁之间不互斥,也就是说,允许多个线程同时对加了 MDL 读锁的表进行 CRUD(增删改查)操作;
- MDL 写锁,它和读锁、写锁都是互斥的,目的是用来保证变更表结构操作的安全性。也就是说,当对表结构进行变更时,会被默认加 MDL 写锁,因此,如果有两个线程要同时给一个表加字段,其中一个要等另一个执行完才能开始执行。
- MDL 读写锁是在事务 commit 之后才会被释放;
那什么时候会使用元数据锁这个表级锁呢?
当我们对一个表做增删改查操作的时候,会加上 MDL 读锁;当我们要对表结构做变更时,就会加 MDL 写锁
4.3 意向锁:Intention Lock
意向锁是一种不与行级锁冲突的表级锁(本质上就是空间换时间)。未来的某个时刻,事务可能要加共享或者排它锁时,先提前声明一个意向
为什么要加共享锁或排他锁时的时候,需要提前声明个意向锁呢呢?
因为 InnoDB 是支持表锁和行锁共存的。如果一个事务 A 获取到某一行的排他锁,并未提交,这时候事务 B 请求获取同一个表的表共享锁。由于共享锁和排他锁是互斥的,因此事务 B 想对这个表加共享锁时,需要保证没有其他事务持有这个表的表排他锁,同时还要保证没有其他事务持有表中任意一行的排他锁
然后问题来了:你要保证没有其他事务持有表中任意一行的排他锁的话,去遍历每一行?这样显然是一个效率很差的做法。为了解决这个问题,InnoDB 的设计者提出了意向锁
意向锁是如何解决这个问题的呢?来看下。
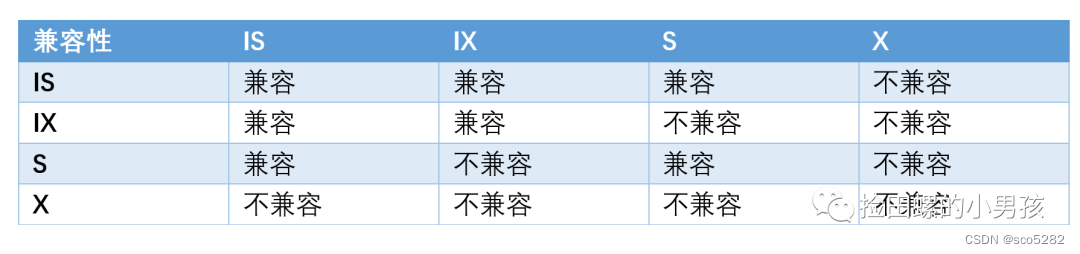
意向锁(InnoDB 自动加上的)分为两类:
- 意向共享锁:简称 IS 锁,当事务准备在某些记录上加 S 锁时,需要现在表级别加一个 IS 锁
- 意向排他锁:简称 IX 锁,当事务准备在某条记录上加上 X 锁时,需要现在表级别加一个 IX 锁
意向锁又是如何解决这个效率低的问题呢?
如果一个事务 A 获取到某一行的排他锁,并未提交,这时候表上就有意向排他锁和这一行的排他锁。这时候事务 B 想要获取这个表的共享锁,此时因为检测到事务 A 持有了表的意向排他锁,因此事务 A 必然持有某些行的排他锁,也就是说事务B对表的加锁请求需要阻塞等待,不再需要去检测表的每一行数据是否存在排他锁啦。这样效率就高很多啦(所以当我们需要判断这个表的记录有没有被加锁时,直接判断意向锁就可以了,减少了遍历的时间,提高了效率,是典型的用空间换时间的做法)。
意向锁仅仅表明意向的锁,意向锁之间并不会互斥,是可以并行的,整体兼容性如下图所示:
那么什么时候会用到意向锁呢?
对表中的行记录加锁的时候,就会用到意向锁
4.4 自增锁:AUTO-INC 锁
自增锁是一种特殊的表级别锁。 它是专门针对 AUTO_INCREMENT 类型的列,对于这种列,如果表中新增数据时就会去持有自增锁。简言之,如果一个事务正在往表中插入记录,所有其他事务的插入必须等待,以便第一个事务插入的行,是连续的主键值
AUTO-INC 锁可以使用 innodb_autoinc_lock_mode 变量来配置自增锁的算法,·innodb_autoinc_lock_mode· 变量可以选择三种值如下:
- 0:传统锁模式(并发最差),使用表级 AUTO_INC 锁。一个事务的
INSERT-LIKE语句在语句执行结束后释放 AUTO_INC 表级锁,而不是在事务结束后释放 - 1:连续锁模式(并发稍好),连续锁模式对于
Simple inserts不会使用表级锁,而是使用一个轻量级锁mutex来生成自增值,因为 InnoDB 可以提前直到插入多少行数据。自增值生成阶段使用轻量级互斥锁来生成所有的值,而不是一直加锁直到插入完成。对于bulk inserts类语句使用 AUTO_INC 表级锁直到语句完成 - 2:交错锁模式(并发最好),所有的
INSERT-LIKE语句都不使用表级锁,而是使用轻量级互斥
- INSERT-LIKE:指所有的插入语句,包括:INSERT、REPLACE、INSERT…SELECT、REPLACE…SELECT,LOAD DATA等
- Simple inserts:指在插入前就能确定插入行数的语句,包括:INSERT、REPLACE,不包含INSERT…ON DUPLICATE KEY UPDATE这类语句
- Bulk inserts: 指在插入钱不能确定行数的语句,包括:INSERT … SELECT/REPLACE … SELECT/LOAD DATA
5. 行锁
行锁是针对数据表中行记录的锁。MySQL 的行锁是在存储引擎层实现的,并不是所有的引擎都支持行锁,比如,InnoDB 引擎支持行锁而 MyISAM 引擎不支持
特点:
- 开销比较大,加锁速度慢,可能会出现死锁,
- 锁定的粒度最小,发生锁冲突的概率最小,并发度最高
InnoDB 引擎的行锁主要有四类:
- 记录锁(Record Lock):是在索引记录上加锁;
- 间隙锁(Gap Lock):锁定一个范围,但不包含记录;
- 临键锁(Next-key Lock):Gap Lock + Record Lock,锁定一个范围(Gap Lock 实现),并且锁定记录本身(Record Lock 实现);
- 插入意向锁(Insert Intention Lock)
那么什么时候会使用行级锁呢?
当增删改查匹配到索引时,Innodb 会使用行级锁;如果没有匹配不到索引,那么就会直接使用表级锁
注意:
- 行锁主要加在索引上,如果对非索引的字段设置条件更新,行锁可能会变成表锁
- InnnoDB 的行锁是针对索引加锁,不是针对记录加锁,并且加锁的索引不能失效,否则行锁可能变成表锁
- 锁定某一行时,可以使用
select ... lock in share mode命令来指定共享锁,使用select ... for update;来指定排他锁
5.1 记录锁(Record Lock)
记录锁:针对索引记录的锁,锁定的总是索引记录
如下 SQL:
SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE
如果 c1 字段是主键或者是唯一索引的话,这个 SQL 就会在 c1 字段上显示地加一个排他型的 记录锁(Record Lock)。 防止其它任何事务 update 或 delete id=1 的行,但是对 user 表的 insert、alter、drop 操作还是可以正常执行
当 SQL 语句无法使用索引时,会进行全表扫描,这个时候 MySQL 会给整张表的所有数据行加记录锁,再由 MySQL Server 层进行过滤。但是,在 MySQL Server 层进行过滤的时候,如果发现不满足 WHERE 条件,会释放对应记录的锁。这样做,保证了最后只会持有满足条件记录上的锁,但是每条记录的加锁操作还是不能省略的
所以,更新/删除操作必须要根据索引进行操作,没有索引时,不仅会消耗大量的锁资源,增加数据库的开销,还会极大的降低了数据库的并发性能
记录锁永远都是加在索引上的,即使一个表没有索引,InnoDB 也会隐式的创建一个索引,并使用这个索引实施记录锁。它会阻塞其他事务对这行记录的更新、删除
5.2 间隙锁(Gap Lock):可重复读RR 隔离级别下才会生效
背景:
在MySQL中使用范围查询时,如果请求共享锁或排他锁,InnoDB 会给符合条件的已有数据的索引项加锁。如果键值在条件范围内, 而这个范围内并不存在记录,则认为此时出现了“间隙(也就是 GAP)”。InnoDB存储引擎会对这个“间隙”加锁,而这种加锁机制就是间隙锁(GAP Lock)
间隙锁:一种加在两个索引之间的锁,或者加在第一个索引之前,或最后一个索引之后的间隙。这个间隙可以跨一个索引记录,多个索引记录,甚至是空的。它锁住的是一个区间
使用间隙锁可以防止其他事务在这个范围内插入或修改记录,保证两次读取这个范围内的记录不会变,从而不会出现幻读现象
表数据如下:
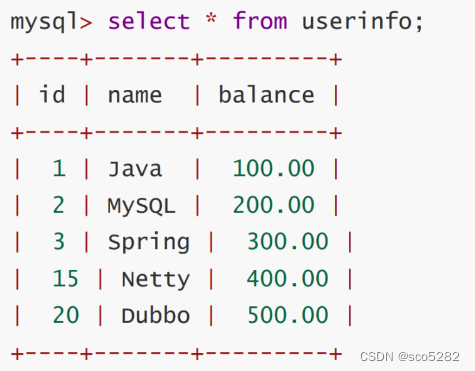
SQL 语句:
update userinfo set balance = balance + 100 where id > 5 and id <16
解析:
数据表中的间隙包括id为 (3,15)、(15,20)、 (20,正无穷) 的三个区间,执行 update userinfo set balance = balance + 100 where id > 5 and id <16; 则其他事务无法在 (3,20) 这个区间内插入或者修改任何数据
间隙锁和间隙锁之间是互不冲突的,间隙锁唯一的作用就是为了防止其他事务的插入,所以加间隙 S 锁和加间隙 X 锁没有任何区别
间隙锁只有在可重复读事务隔离级别下才 会生效
5.3 临键锁(Next-Key Lock):可重复读RR 隔离级别下才会生效
Next-key 锁是记录锁和间隙锁的组合,它指的是加在某条记录以及这条记录前面间隙上的锁。说得更具体一点就是:临键锁会封锁索引记录本身,以及索引记录之前的区间,即它的锁区间是前开后闭,比如 (5,10]
假设一个索引包含:15、18、20 ,30,49,50
可能的 Next-key 锁如下:

5.4 插入意向锁(Insert Intention Lock)
插入意向锁:插入一行记录操作之前设置的一种间隙锁。这个锁释放了一种插入方式的信号。它解决的问题是:多个事务,在同一个索引,同一个范围区间插入记录时,如果插入的位置不冲突,就不会阻塞彼此
插入意向锁和插入意向锁之间互不冲突
id = 30 和 id = 49 之间如果有两个事务要同时分别插入 id = 32 和 id = 33 是没问题的,虽然两个事务都会在 id = 30 和 id = 50 之间加上插入意向锁,但是不会冲突
插入意向锁只会和间隙锁或 Next-key 锁冲突
间隙锁唯一的作用就是防止其他事务插入记录造成幻读。由于在执行 INSERT 语句时需要加插入意向锁,插入意向锁和间隙锁冲突,从而阻止了插入操作的执行。
注意:
- 插入意向锁不影响其他事务加其他任何锁。也就是说,一个事务已经获取了插入意向锁,对其他事务是没有任何影响的
- 插入意向锁与间隙锁和 Next-key 锁冲突。也就是说,一个事务想要获取插入意向锁,如果有其他事务已经加了间隙锁或 Next-key 锁,则会阻塞
- 间隙锁不和其他锁(不包括插入意向锁)冲突;
- 记录锁和记录锁冲突,Next-key 锁和 Next-key 锁冲突,记录锁和 Next-key 锁冲突;
6. 页面锁
页级锁:页面级别对数据进行加锁和释放锁。对数据的加锁开销介于表锁和行锁之间,可能会出现死锁,锁定的粒度大小介于表锁和行锁之间,并发度一般

7. 总结
- 表锁:当存储引擎不支持行级锁时,使用表锁;SQL 语句没有匹配到索引时,使用表锁
- 元数据锁:对表做增删改查时,会加上 MDL 读锁。对表结构做变更时,会加上 MDL 写锁
- 意向锁:对表中的行记录加锁时,会用到意向锁
- 行级锁:增删改查匹配到索引时,会使用行级锁
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Go语言HTTP客户端编程实践
- 异步优势演员-评论家算法 A3C
- 日常工作中常用的抓包工具都有哪些呢?
- Devart Expands Connectivity
- final, finally, finalize 的区别?
- 揭秘 `nextTick`:解决异步回调的利器(下)
- 制造业管理软件:为何ERP替代不了MES?
- GRE系列 2:1宽压输入6KV隔离双回路直流高压输出电源模块
- ExtJS 的 各种提示框
- git checkout进行更改分支