MySQL一行记录是怎么存储的?

MySQL的数据存放在哪个文件?
MySQL的存储是由存储引擎实现的,不同存储引擎实现方式不同,这里以常见的InnoDB存储引擎介绍。
当创建一个database(数据库)之后,就会在/var/lib/mysql目录下创建database命名的目录,该目录下主要有几种类型的文件:
-
db.opt文件:用来存储当前数据库的默认字符集和字符校验规则
-
table_name.frm文件:存储表结构,在MySQL中建立的每一张表都会对应有一个.frm文件,主要包含表结构定义
-
table_name.idb文件:存储表数据。表数据即可以在共享表空间文件(ibdata1文件)里,也可以存放在独占表空间文件(table_name.idb)里,由参数
innodb_file_per_table控制,为1表示会将表数据、索引等信息单独存放在.idb文件里,5.6.6之后的版本该参数都默认为1
表空间的文件结构是怎么样的?
表空间由段(Segment)、区(Extent)、页(Page)、行(Row)组成
-
行(Row):数据库表中的记录都是按行进行存放的,行格式不同,存储结构也不同
-
页(Page):
-
记录是按行存储的,但是读取并不以【行】读写,否则一次读取(也就是一次IO操作)只能处理一行,效率低
-
InnoDB的数据是以【页】为单位进行读写,是InnDB存储引擎磁盘管理的最小单元,默认每个页大小为16KB
-
页有多种类型,常见的比如数据页、溢出页、undo日志页。表中的数据存储在数据页
-
-
区(Extent):在表数据量大的时候,不以页为单位分配空间,而是以区为单位空间,这样一个区里的多个页在物理地址上连续,磁盘查询就能进行顺序IO,而不是随机IO。每个区大小为1M,对于16KB的页,连续的64个页就会被划为一个区
-
段(Segment):表空间由各个段组成,一个段包含多个区。段分为数据段、索引段、回滚段
-
索引段:存放B+树非叶子节点的区
-
数据段:存放B+树叶子节点的区
-
回滚段:存放回滚数据的区
-
补充

数据页的结构

数据页的结构包含以下部分:
-
文件头File Header:文件头中有两个指针,分别指向上一个数据页和下一个数据页,多个页形成一个双向链表
-
页头Page Header:记录页的状态信息
-
最大、最小记录:两个虚拟的伪记录,分别表示页中的最大、最小记录。这里最大最小指的是主键
-
用户记录User Records:存储行记录内容
-
空闲空间Free Space:页中还没有被使用的空间
-
页目录Page Directory:存储用户记录的相对位置,对记录起到索引作用
-
文件尾File Trailer:校验页是否完整
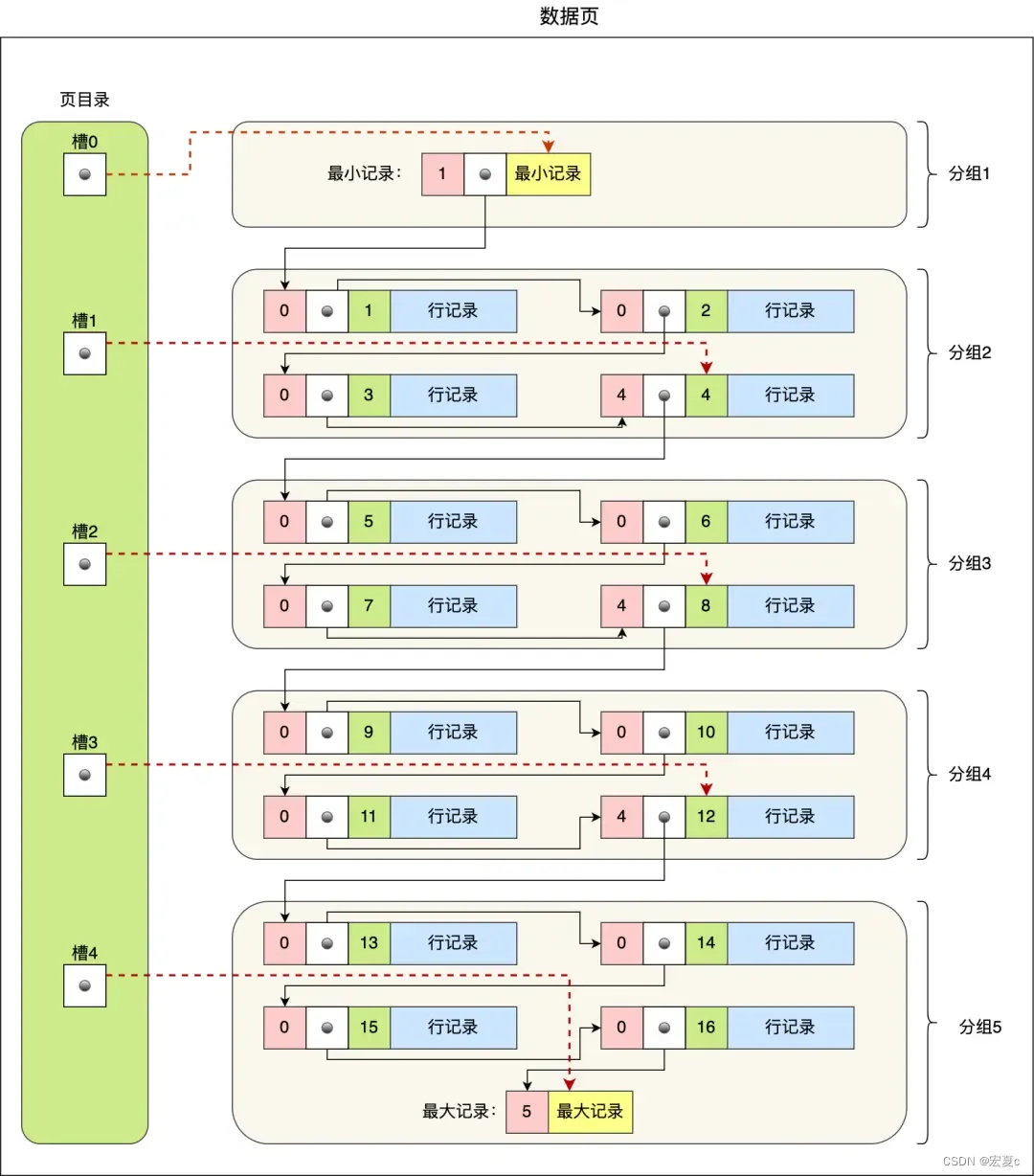
一个数据页中有多个记录,记录按照主键顺序组成一个单向链表,易于插入和删除,但检索效率就比较差。为了提高检索效率,数据页中结构中有一个页目录,来实现对记录的检索。
页目录的创建过程:
-
将所有记录分为多个组,不包括标记为“已删除”的记录
-
每个分组的最后一条记录就是该分组的最大记录,该记录会在头信息中记录该分组记录的数量,作为n_owned字段(图中粉色部分)
-
页目录会存储每个分组的最后一个记录的地址偏移量,称为槽(slot),按先后顺序存储起来
所以页目录中的槽,相当于是分组记录的索引。在查找记录的时候,通过二分法查找到记录所在的分组,然后遍历分组里的记录,就能找到需要的记录。
记录的查找过程:
以下图作为例子,一共有五个分组,也就对应着五个槽,编号分别为0、1、2、3、4,现在要查找主键为11的记录。
-
通过二分法,先算出槽的中间位:(0 + 4)/ 2 = 2,找到编号为2的槽,该槽所指向的是分组3的最后一条记录,该记录的主键为8,要查找的记录11比这个记录8要大,需要往后查找
-
继续二分搜索,算出2号槽和4号槽的中间位:(2 + 4) / 2 = 3,找到编号为3的槽,该槽所指向的是分组4的最后一条记录,该记录的主键为12,要查找的记录11比这个记录12要小,说明要查找的记录在这个分组4里
-
于是遍历分组4里的记录,找到所需要的记录11。这里有一个问题,就是如何遍历,也就是如何找到该分组的最小记录(也就是该分组的第一条记录),才能顺着单向链表开始遍历。要得到该分组的最小记录,可以通过上一个槽找到上一个分组的最大记录 ,然后加1得到该分组的最小记录
InnoDB存储引擎对于每一个分组的记录数量有所规定:
-
第一个分组只能有一条记录
-
最后一个分组只能由1~8条记录
-
其余分组只能有4~8条记录
所以不用担心通过单向链表遍历一个分组里的记录时间复杂度为O(n)
InnoDB的行格式有哪些
行格式就是存储一行记录的存储结构,InnoDB提供了4种行格式:Redundant、Compact、Dynamic和 Compressed 行格式。重点介绍Compact。
默认的行格式可以通过命令show variables like 'innodb_default_row_format'查看
Compact行格式
Compact行格式可以分为两个部分,分别为“记录的额外信息”和“记录的真实数据”

记录的额外信息包括以下部分:
-
变长字段长度列表:存储变长字段数据所占用的大小,比如varchar类型,才能根据这个值读取对应长度的变长字段的值
-
如何存储的变长字段长度(格式是怎么样的):比如
name varchar(20) default 'u',并且使用的字符集是ascii(1个字符占用1个字节),所以name的值u就占用1个字节,十六进制形式0x01,就以01存储 -
当有多个变长字段时,逆序存储,也就是从右到左
-
当表结构不存在变长字段时,【变长字段长度列表】的结构就不存在,因为不需要
-
-
NULL值列表:表中的某些列可能存在NULL值,如果直接存储NULL值的话会比较浪费空间,所以Compact格式是采用标志为来标志一个记录的某个列为NULL
-
这个标志位就是【NULL值列表】,如果存在允许值为NULL的列,则每个列对应一个二进制位,为1表示该列值为NULL,为0表示该列值不为NULL,也是逆序存储(从右到左)
-
NULL值列表也不是必须的,当表中所有字段都定义NOT NULL时,就不需要了
-
NULL值列表的默认大小为1个字节,也就是8个位,当表中字段超过8时,NULL值列表就会增加1个字节,以此类推;若不足8位,高位补0

-
-
记录头信息:包括以下内容
-
delete_mask:标志此记录是否被删除,为1表示此记录被删除
-
next_record:指向下一条记录,具体位置是下一条记录的【记录头信息】和【真实数据】之间的位置,向左读就是记录头信息,向右读就是真实数据,比较方便。所以变长字段长度列表和NULL值列表逆序存储也是这个原因。
-
record_type:表示记录的类型,0为普通记录,1为B+树非叶子节点记录,2表示最小记录,3表示最大记录
-
记录的真实数据包括以下部分:
-
row_id:如果该表既没有主键,又没有唯一索引,那么就需要row_id,不是必须的,占6个字节
-
trx_id:事务id,表示这个记录是由哪个事务生成的,必须的,占6个字节
-
roll_pointer:这条记录上一个版本的指针,必须的占7个字节
总结
MySQL的NULL值是怎么存放的?
MySQL的Compact行格式中有一个NULL值列表,使用二进制的形式来标志某一列是否为NULL,1表示NULL,0表示不是NULL,而不是直接存储NULL。
NULL值列表会占用一个字节,当表中的所有字段都定义为非NULL时,就不需要这个NULL值列表了
MySQL是怎么知道varchar(n)实际占用的大小?
MySQL的Compact行格式中有一个变长字段长度列表,用来存储可变长字段所占用的大小
varchar(n)中的n最大取值为多少?
n指的是字符的长度,具体取决于mysql的版本、存储引擎、以及使用的行格式。像我使用的5.7的版本,存储引擎用innodb,使用的行格式是dynamic,一行记录最大能存储65535字节的数据,65535包括【变长字段长度列表】和【NULL值列表】,所以计算varchar(n)时,要减去这两个所占用的字节
参考资料
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【实施】共享目录&防火墙
- @Transactional使用方法代码讲解
- 鸿蒙Harmony4.0开发-ArkUI(一)条件渲染控制
- OpcUaHelper实现西门子OPC Server数据交互
- Java版 招投标系统简介 招投标系统源码 java招投标系统 招投标系统功能设计
- uniapp条件编译
- Numpy教程(二)—— 数据存储及各种常用方法
- 牛客30道题解析精修版
- 跟我学java|Stream流式编程——并行流
- 阿尔泰科技融合信息产业国产化成果,率先完成的全国产化测控系统软硬件构架。