python定义代码块的符号,python中代码块所属关系
大家好,小编来为大家解答以下问题,python中代码块所属关系的语法,python定义代码块的符号,今天让我们一起来看看吧!

本文章主要用于平时Python3学习和使用中积累的比较常用的代码块。代码都是经过验证可行的python简单代码案例。
一、基本数据类型
字符串
字符串常识:
- 可以利用反斜杠(\)对双引号转义:",或者用单引号引起这个字符串。例如:‘I l"o"ve fishc.com’
- 字符串支持分片,如:Str1[:6] 返回字符串前6个字符 ,0-5 index
字符串的方法(都要用dot),返回一个新的字符串,原来不变。例如字符串s, s.capitalize()返回一个新的字符串。
# 字符串相加
>>> print("nihao"+"a")
nihaoa
# 字符串乘整数,连续输出8次,相当8次字符串相加
>>> print("nihao\n"*3)
nihao
nihao
nihao
# 在前面的字符串后面打印后面的字符串,再循环中使用很方便,例如用new line mark or space
>>> print("不分手的", end="恋爱")
不分手的恋爱
# 获得字符串长度
>>> len("chilema")
7
# 在一个字符串的每个字符之间插入一个字符串
>>> str1 = "sh"
>>> str1.join("12345")
'1sh2sh3sh4sh5'
进制转换
#十进制转换二进制
>>> bin(10)
'0b1010'
随机数
Python自带random库支持模拟多种分布,包括Beta、Exponential、Gamma、Gaussian、Log normal distribution、Pareto distribution、Weibull distribution等,具体见 random — Generate pseudo-random numbers
Basic samples
>>> from random import *
>>> random() # Random float: 0.0 <= x < 1.0
0.37444887175646646
>>> uniform(2.5, 10.0) # Random float: 2.5 <= x < 10.0
3.1800146073117523
>>> expovariate(1 / 5) # Interval between arrivals averaging 5 seconds
5.148957571865031
>>> randrange(10) # Integer from 0 to 9 inclusive
7
>>> randrange(0, 101, 2) # Even integer from 0 to 100 inclusive
26
>>> choice(['win', 'lose', 'draw']) # Single random element from a sequence
'draw'
>>> deck = 'ace two three four'.split()
>>> shuffle(deck) # Shuffle a list
>>> deck
['four', 'two', 'ace', 'three']
>>> sample([10, 20, 30, 40, 50], k=4) # Four samples without replacement
[40, 10, 50, 30]
Simulations
>>> # Six roulette wheel spins (weighted sampling with replacement)
>>> choices(['red', 'black', 'green'], [18, 18, 2], k=6)
['red', 'green', 'black', 'black', 'red', 'black']
>>> # Deal 20 cards without replacement from a deck of 52 playing cards
>>> # and determine the proportion of cards with a ten-value
>>> # (a ten, jack, queen, or king).
>>> deck = collections.Counter(tens=16, low_cards=36)
>>> seen = sample(list(deck.elements()), k=20)
>>> seen.count('tens') / 20
0.15
>>> # Estimate the probability of getting 5 or more heads from 7 spins
>>> # of a biased coin that settles on heads 60% of the time.
>>> def trial():
... return choices('HT', cum_weights=(0.60, 1.00), k=7).count('H') >= 5
...
>>> sum(trial() for i in range(10_000)) / 10_000
0.4169
>>> # Probability of the median of 5 samples being in middle two quartiles
>>> def trial():
... return 2_500 <= sorted(choices(range(10_000), k=5))[2] < 7_500
...
>>> sum(trial() for i in range(10_000)) / 10_000
0.7958
Simulation of arrival times and service deliveries for a multiserver queue
from heapq import heappush, heappop
from random import expovariate, gauss
from statistics import mean, median, stdev
average_arrival_interval = 5.6
average_service_time = 15.0
stdev_service_time = 3.5
num_servers = 3
waits = []
arrival_time = 0.0
servers = [0.0] * num_servers # time when each server becomes available
for i in range(100_000):
arrival_time += expovariate(1.0 / average_arrival_interval)
next_server_available = heappop(servers)
wait = max(0.0, next_server_available - arrival_time)
waits.append(wait)
service_duration = gauss(average_service_time, stdev_service_time)
service_completed = arrival_time + wait + service_duration
heappush(servers, service_completed)
print(f'Mean wait: {mean(waits):.1f}. Stdev wait: {stdev(waits):.1f}.')
print(f'Median wait: {median(waits):.1f}. Max wait: {max(waits):.1f}.')
MD5 hash
import hashlib # 导入hashlib模块
md = hashlib.md5() # 获取一个md5加密算法对象
md.update('how to use md5 in hashlib?'.encode('utf-8')) # 制定需要加密的字符串
print(md.hexdigest()) # 获取加密后的16进制字符串
判断变量的类型
>>> tmp = [1,2,3]
>>> isinstance(tmp, list)
# Out: True
二、循环
跳出多层循环
for … else … break
else中的语句是在for循环所有正常执行完毕后执行。所以如果for中有break执行的话,else的语句就不执行了
for i in range(5):
for j in range(5):
for k in range(5):
if i == j == k == 3:
break
else:
print(i, '----', j, '----', k)
else: continue
break
else: continue
break
上面程序执行到i=j=k=3的时候就跳出所有循环了,不再执行
利用flag变量
a = [[1, 2, 3], [5, 5, 6], [7, 8, 9]]
for i in range(3):
for j in range(3):
if a[i][j] == 5:
flag = False
break
if not flag:
break
自定义异常
class StopLoopError(Exception): pass
try:
for i in range(5):
for j in range(5):
for k in range(5):
if i == j == k == 3:
raise StopLoopError()
else:
print(i, '----', j, '----', k)
except StopLoopError:
pass
三、函数
- set the default value of arguments
def my_func(a, b=5, c=10): - keywords arguments(named arguments): my_func(a=1, c=2)
*argsis used to scoop up variable amount of remaining positional arguments(it is a tuple). You cannot add more positional arguments after *args, the parameter name can be anything besides args。unless you use keyword(named) arguments. i.e.def func1(a, b, *args, d):func1(1,2,3,4,d=30)**kwargsis used to scoop up a variable amount of remaining keyword arguments(it is a dictionary). Unlike keyword-only arguments, it can be specified even if the positional arguments have not been exhausted. No parameters can come after **kwargs
def func1(a, b, *args):
print(a, b, args)
func1(1,2) #如果不给*args值,就返回一个空的元组
# out: 1 2 ()
l = [1,2,3,4,5]
func1(*l) # unpack a list as arguments
# out: 1 2 (3, 4, 5)
# 求平均数
# a and b,如果两个都为真,返回第二个,如果一个真一个假或者两个都假返回False或者第一个值。
# a or b,如果两个都为真,返回第一个值,如果一个真一个假,则返回真的值,如果两个都假则返回第二个
def avg(*args):
count = len(args)
total = sum(args)
return count and total/count # 通过and判断函数是否有参数输入
# to force no positional arguments,you can only give keyword argument when you call the function
def func(*, d):
#code
# * shows the end of positional parameters
def func(a, b, *, d): # you can only pass two positional arguments, and here d is keyword parameter
#code
def func(*, d, **kwargs):
print(d, kwargs)
func(d=1, a=2, b=3, c=4)
#out: 1 {'a': 2, 'b': 3, 'c': 4}
# use *args and **kwargs together
def func(*args, **kwargs):
print(args, kwargs)
func(1, 2, b=3, c=4, d=5)
#out: (1, 2) {'b': 3, 'c': 4, 'd': 5}
# cached version of factorial, no more calculation for calculated number
def factorial(n, cache={}):
if n < 1:
return 1
elif n in cache:
return cache[n]
else:
print("caculation {0}".format(n))
result = n * factorial(n-1)
cache[n] = result
return result
Lambda Expression (Anonymous Function)
# lambda with one input
>>> g = lambda x: 3*x + 1
>>> g(3)
10
#lambda with multiple input(two or more), e.g. combining first name and last name
#strip() is to remove the leading and trailing whitespace.
#title() is to ensure the first letter of each string is capitalized
>>> full_name = lambda fn, ln: fn.strip().title() + " " + ln.strip().title()
>>> full_name(" ZHAng ", "sAN")
'Zhang San'
#sort list by key using lambda
>>> list_example = ["9 jiu", "1 yi", "5 wu", "3 san"]
>>> list_example.sort(key = lambda word: word.split(" ")[0])
>>> list_example
['1 yi', '3 san', '5 wu', '9 jiu']
#function returns function, e.g. Quadratic Functions f(x) = ax^2 +bx + c
>>> def build_quadratic_function(a, b, c):
... return lambda x: a*x**2 + b*x + c
...
>>> f = build_quadratic_function(1, 3, 2)
>>> f(0)
2
>>> f(1)
6
Reducing function arguments (partial function)
This is just to reduce the number of arguments you need to pass when you call the original function. Sometimes, this is useful because some higher-ordered function can only accept one-parameter function as his arguments, you can see it in the following example.
# calculate the distance from some points to the origin in a x-y coordinate.
origin = (0, 0)
l = [(1,1), (-3, -2), (-2, 1), (0, 0)]
dist = lambda a, b: (a[0] - b[0]) ** 2 + (a[1] - b[1]) ** 2
# the above function needs two arguments, but you want to pass this function to sorted function which can only accept a one-parameter function. So you need to reduce it.
from functools import partial
f = partial(dist, origin)
print(sorted(l, key=f))
# you can also use lambda function
print(sorted(l, key=lambda x: dist(x, origin)))
四、容器及其操作
集合Set
#modify sets
>>> example1 = set()
>>> example1.add("yi") # 添加元素
>>> example1.add("er")
>>> example1.update([1,4],[5,6]) # update可以同时添加多个元素
>>> example2 = set([28, True, 3.14, "nihao", "yi", "er"])
>>> len(example)
# 移除元素
>>> example2.remove(x) # 将元素 x 从集合 example2 中移除,如果元素不存在,则会发生KeyError错误
>>> example2.discard("Facebook") # 不存在不会发生错误
>>> example2.clear() # 清空集合
>>> x = example2.pop() # 随机删除集合中的一个元素赋值给x
# evaluate union and intersection of two sets
>>> example1.union(example2)
>>> example1.intersection(example2)
>>> "nihao" in example2 # 查看元素是否在集合内
True
>>> "nihao" not in example2
False
# 两个集合间的运算
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # 集合a中包含而集合b中不包含的元素
{'r', 'd', 'b'}
>>> a | b # 集合a或b中包含的所有元素
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # 集合a和b中都包含了的元素
{'a', 'c'}
>>> a ^ b # 不同时包含于a和b的元素
{'r', 'd', 'b', 'm', 'z', 'l'}
>>> example1.isdisjoint(example2) # 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False
>>> issubset() # 判断指定集合是否为该方法参数集合的子集
元组Tuple
- 一旦定义,不能改变,不能再赋值,不能用del删除某个元素,只能删除整个元组
- 元组的切片方法和列表一样
- 创建空元组:temp=()
- 创建一个数的元组:temp=(1,) 必须加逗号,括号可以不加
- 改变一个元组的办法,例如 temp=(1,2,3,4),令
temp = temp[:2] + (6,) + temp[2:]输出temp 为 (1,2,6,3,4),这是元组的拼接,同样适用于字符串。
>>> temp = 1,2,3
>>>temp
(1, 2, 3)
>>> 8*(8,)
(8, 8, 8, 8, 8, 8, 8, 8)
Unzip a list of tuples
zipped_list = [(1, 'a'), (2, 'b'), (3, 'c')]
list_a, list_b = zip(*zipped_list)
print(list_a)
# out: (1,2,3)
print(list_b)
# out: ('a', 'b', 'c')
Iterators returns only elements at a time. len function cannot be used with iterators. We can loop over the zip object or the iterator to get the actual list.
list_a = [1, 2, 3]
list_b = [4, 5, 6]
zipped = zip(a, b) # out: zip object
len(zipped) = # out: TypeError: object of type 'zip' has no len()
zipped[0] # out: zip object is not subable
list_c = list(zipped) # out: [(1,4), (2,5), (3,6)]
list_d = list(zipped) # out: [] is empty list because of the above statement
Named tuples
Named tuples subclass tuple, and add a layer to assign property names to the potential elements. It is located in the collections standard library module. Named tuples are also regular tuples, we can still handle them just like any other tuple(by index, slice, iterate). Named tuples are immutable.
from collections import namedtuple
'''it is a function(class factory) which generates(return) a new class that
inherits from tuple. The new class provides named properties to access
elements of the tuple and an instance of that class is still a tuple'''
'''namedtuple needs a few things to generate this class:
1.the class name we want to use
2.a sequence(list, tuple) of field names(strings) we want to assign, in the order of the elements in that tuple
'''
Point2D = namedtuple('Point2D', ['x', 'y']) # the variable initial is capitalized, because it receives a class returned from the fucntion
#the following three ones have the same effect
#Point2D = namedtuple('Point2D', ('x', 'y'))
#Point2D = namedtuple('Point2D', 'x, y')
#Point2D = namedtuple('Point2D', 'x y')
'''in fact, the __new__ method of the generated class uses the field names we provided as param names'''
# we can easily find out the field names in a named tuple generated class
>>> Point2D._fields
('x', 'y')
>>> print(Point2D._source)
... # print out what the class is
>>> pt = Point2D(10, 20)
>>> isinstance(pt, tuple)
True
# extract named tuple values to a dictionary, by using a instance method.
# the keys of the ordered dictionary is in order
>>> pt._asdict()
OrderedDict([('x', 10), ('y', 20)])
# to make it a normal dictionary
>>> dict(pt._asdict())
{'x': 10, 'y': 20}
# we can handle it as we deal with the normal tuple
x, y = pt
x = pt[0]
for e in pt: print(e)
# in addition, we can also access the data using the field name
>>> pt.x # note: you can assign value to it, since it is immutable
10
>>> pt.y
20
# modify named tuples (create a new one)
>>> Stock = namedtuple('Stock', 'symbol year month day open high low close')
>>> djia = Stock('DJIA', 2018, 1, 25, 26_313, 26_458, 26_260, 26_393)
>>> djia
Stock(symbol='DJIA', year=2018, month=1, day=25, open=26313, high=26458, low=26260, close=26393)
>>> djia = djia._replace(year = 2017, open = 10000)
>>> djia
Stock(symbol='DJIA', year=2017, month=1, day=25, open=10000, high=26458, low=26260, close=26393)
>>> Stock._make(djia[:7] + (1000, )) # _make can take a tuple as parameter
Stock(symbol='DJIA', year=2017, month=1, day=25, open=10000, high=26458, low=26260, close=1000)
# extend named tuples
Stock = namedtuple('Stock', Stock._fields + ('newOne', ))
# set default values by using __defaults__
>>> Stock = namedtuple('Stock', 'symbol year month day open high low close')
>>> Stock.__new__.__defaults__ = (0, 0, 0) # the last three parameter, read from backwards
>>> djia = Stock(1, 2, 3, 4, 5)
>>> djia
Stock(symbol=1, year=2, month=3, day=4, open=5, high=0, low=0, close=0)
# update defaults
Stock.__new__.__defaults__ = (-10, -10, -10)
>>> djia = Stock(1, 2, 3, 4, 5)
>>> djia
Stock(symbol=1, year=2, month=3, day=4, open=5, high=-10, low=-10, close=-10)
# return multiple values using named tuple
# here is to return a random color
from random import randint, random
from collections import namedtuple
Color = namedtuple('Color', 'red green blue alpha')
def random_color():
red = randint(0, 255)
green = randint(0, 255)
blue = randint(0, 255)
alpha = round(random(), 2) # 精确到两位小数
return Color(red, green, blue, alpha)
# transform a dictionary to a nametuple
def tuplify_dicts(dicts):
keys = {key for dict_ in dicts for key in dict_.keys()}
Struct = namedtuple('Struct', sorted(keys), rename=True)
Struct.__new__.__defaults__ = (None, ) * len(Struct._fields)
return [Struct(**dict_) for dict_ in dicts]
data_list = [
{'key2': 2, 'key1': 1},
{'key1': 3,'key2': 4},
{'key1': 5, 'key2': 6, 'key3': 7},
{'key2': 100}
]
tuple_list = tuplify_dicts(data_list)
>>> tuple_list
[Struct(key1=1, key2=2, key3=None),
Struct(key1=3, key2=4, key3=None),
Struct(key1=5, key2=6, key3=7),
Struct(key1=None, key2=100, key3=None)]
'''If you just read a lot of key-value pairs, you can use namedtuple rather than dictionary due to efficiency.
And if your class only has a lot of values and doesn't need mutability, namedtuple is preferred, due to saving space'''
列表
判断列表的连续数字范围并分块
列表中的数字是连续数字(从小到大)
from itertools import groupby
lst = [1,2,3,5,6,7,8,11,12,13,19]
func = lambda x: x[1] - x[0]
for k, g in groupy(enumerate(lst), func):
l1 = [j for i, j in g]
if len(l1) > 1:
scop = str(min(l1)) + '_' + str(max(l1))
else:
scop = l1[0]
print("连续数字范围: {}".format(scop))
里面中的数字是非连续数字即没有排序,先排序
lst = [4, 2, 1, 5, 6, 7, 8, 11, 12, 13, 19]
for i in range(len(lst)):
j = i + 1
for j in range(len(lst)):
if lst[i] < lst[j]:
temp = lst[i]
lst[i] = lst[j]
lst[j] = temp
print("排序后列表:{}".format(lst))
列表元素的排列组合
排列
from itertools import product
l = [1, 2, 3]
print(list(product(l, l)))
# out: [(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)]
print(list(product(l, repeat=3)))
# out: [(1, 1, 1), (1, 1, 2), (1, 1, 3), (1, 2, 1), (1, 2, 2), (1, 2, 3), (1, 3, 1), (1, 3, 2), (1, 3, 3), (2, 1, 1), (2, 1, 2), (2, 1, 3), (2, 2, 1), (2, 2, 2), (2, 2, 3), (2, 3, 1), (2, 3, 2), (2, 3, 3), (3, 1, 1), (3, 1, 2), (3, 1, 3), (3, 2, 1), (3, 2, 2), (3, 2, 3), (3, 3, 1), (3, 3, 2), (3, 3, 3)]
组合
from itertools import combinations
print(list(combinations([1,2,3,4,5], 3)))
# out: [(1, 2, 3), (1, 2, 4), (1, 2, 5), (1, 3, 4), (1, 3, 5), (1, 4, 5), (2, 3, 4), (2, 3, 5), (2, 4, 5), (3, 4, 5)]
Map, Filter, Reduce
Map
>>> import math
>>> def area(r):
"""Area of a circle with radius 'r'."""
return math.pi * (r**2)
>>> radii = [2, 5, 7.1, 0.3, 10]
>>> map(area, radii)
<map object at 0x112f870f0>
>>> list(map(area, radii))
[12.566370614359172, 78.53981633974483, 158.36768566746147, 0.2827433388230814, 314.1592653589793]
#convert Celsius to Fahrenheit
>>> temps = [("Berlin", 29), ("Beijing", 36), ("New York", 28)]
>>> c_to_f = lambda data: (data[0], (9/5)*data[1] + 32)
>>> list(map(c_to_f, temps))
[('Berlin', 84.2), ('Beijing', 96.8), ('New York', 82.4)]
Filter
In Python, {}, [], (), "", 0, 0.0, 0j, False, None are treated as False.
#filter the values above the average
>>> import statistics
>>> data = [1.3, 2.7, 0.8, 4.1, 4.3]
>>> avg = statistics.mean(data)
>>> avg
2.64
>>> filter(lambda x: x > avg, data)
<filter object at 0x112f87780>
>>> list(filter(lambda x: x > avg, data))
[2.7, 4.1, 4.3]
#remove missing values
>>> countries = ["", "China", "Brazil", "", "Germany"]
>>> list(filter(None, countries))
['China', 'Brazil', 'Germany']
Reduce
“Use functools.reduce() if you really need it; however, 99% of the time an explicit for loop is more readable.” - Guido van Rossum(Python creator)
>>> from functools import reduce
>>> data = [2, 3, 5, 7, 11]
>>> multiplier = lambda x, y: x*y
>>> reduce(multiplier, data) # use the product of first two elements to multiply the third, then use the result to multiply the fourth, and so on.
2310
字典
几点注意:
for each in 字典名:each为字典中每个项的关键字- .keys() 返回所有key
- .values() 返回所有value
- .Items() 返回字典所有项,以元组的形式
- .get(key) 获得该键对应的值,如果该key不存在的话,相当于反会了空值,False
- key in 字典名,存在则返回true,不存在false
- .clear() 清空字典,被字典赋值的另外的字典也被清空
- .copy() 拷贝字典 拷贝之后不会被原来的字典影响,区别与直接赋值的方法,dict2=dict1,这个方法在改编dict2时会改变dict1
- .pop(key) 弹出该键的值,并在原字典中删除
- .popitem()随机弹出一个,并在原字典中删除
- .setdefault(key, value) 向字典中随机位置加入一个项
- 字典1.update(字典2) ,把字典1中与字典2中有相同的key的项的值变成和字典2中一样
- .fromkeys((key1, key2, key3), ‘we are the same’)。生成一个新的字典,字典的每个value都是一样的,等于第二个参数
- del(字典名[key])可以删除字典中的该项
# 函数dict()只有一个参数,所以在输入许多元组或列表时要在加一个括号都括起来。下面的元组可以换成列表
>>> dict((('F',70), ('i',105), ('s',115)))
{'s': 115, 'i': 105, 'F': 70}
# 下面的key不要加引号。如果已有这个键则重新赋值,没有则创建一个
>>> dict(key1 = 1, key2 =2, key3=3)
{'key2': 2, 'key3': 3, 'key1': 1}
# 给字典赋值的另一种方法
>>> MyDict = {}
>>> (MyDict['id'],MyDict['name'],MyDict['sex']) = ['212','lala','man']
>>> MyDict
{'id': '212', 'sex': 'man', 'name': 'lala'}
# 把字典的key和value合并成元组
>>> n = {1: 'a', 2: 'b', 3: 'c'}
>>> for x, y in n.items():
print((x, y))
(1, 'a')
(2, 'b')
(3, 'c')
# 字典推导式
>>> b = {i: i % 2 == 0 for i in range(10)}
>>> b
{0: True, 1: False, 2: True, 3: False, 4: True, 5: False, 6: True, 7: False, 8: True, 9: False}
Sort by multiple keys in dictionary
First, the dictionaries in the list is sorted by the key of “fname”, then based on the result, it is sorted by the key of “lname” partially again.
from operator import itemgetter
users = [
{'fname': 'Bucky', 'lname': 'Roberts'},
{'fname': 'Tom', 'lname': 'Roberts'},
{'fname': 'Bernie', 'lname': 'Zunks'},
{'fname': 'Jenna', 'lname': 'Hayes'},
{'fname': 'Sally', 'lname': 'Jones'},
{'fname': 'Amanda', 'lname': 'Roberts'},
{'fname': 'Tom', 'lname': 'Williams'},
{'fname': 'Dean', 'lname': 'Hayes'},
{'fname': 'Bernie', 'lname': 'Barbie'},
{'fname': 'Tom', 'lname': 'Jones'},
]
for x in sorted(users, key=itemgetter('fname', 'lname')):
print(x)
# OUTPUT:
{'fname': 'Amanda', 'lname': 'Roberts'}
{'fname': 'Bernie', 'lname': 'Barbie'}
{'fname': 'Bernie', 'lname': 'Zunks'}
{'fname': 'Bucky', 'lname': 'Roberts'}
{'fname': 'Dean', 'lname': 'Hayes'}
{'fname': 'Jenna', 'lname': 'Hayes'}
{'fname': 'Sally', 'lname': 'Jones'}
{'fname': 'Tom', 'lname': 'Jones'}
{'fname': 'Tom', 'lname': 'Roberts'}
{'fname': 'Tom', 'lname': 'Williams'}
Getting key with maximum value in dictionary
key_with_max_value = max(stats, key=stats.get)
Update
用字典b update来更新字典 a,会有两种情况:
- 有相同的键时:会使用最新的字典 b 中 该 key 对应的 value 值。
- 有新的键时:会直接把字典 b 中的 key、value 加入到 a 中。
>>> a = {1: 2, 2: 2}
>>> b = {1: 1, 3: 3}
>>> a.update(b)
>>> print(a)
{1: 1, 2: 2, 3: 3}
也可以使用元组更新字典
d = {'x': 2}
d.update(y = 3, z = 0)
print(d)
# out
# {'x': 2, 'y': 3, 'z': 0}
五、类
inheritance, Magic, Property Decorator
class People():
def __init__(self, name, age):
self.name = name
self.age = age
def __repr__(self):
return "People('{}', {})".format(self.name, self.age)
def __str__(self):
return "I'm {}, and I am {} years old".format(self.name, self.age)
people = People("Zhang San", 24)
print(people)
print(people.__repr__()) # use Magic Method
# single inheritance
class Male(People):
def __init__(self, name, age, hobby):
super().__init__(name, age)
self.hobby = hobby
class Play():
def __init__(self, game):
self.game = game
# multiple inheritance
class Boy(Male, Play):
def __init__(self, name, age, hobby, game, favor_toy):
Male.__init__(self, name, age, hobby)
Play.__init__(self, game)
self.favor_toy = favor_toy
# use Property Decorator, which makes a method become a property of the instance
@property
def my_favor_toy(self):
return "My favourite toy is " + self.favor_toy
boy = Boy('Tim', 24, 'Play video game', 'Street Fighter', 'Lego')
print(boy.name)
print(boy.hobby)
print(boy.game)
print(boy.favor_toy)
print(boy.my_favor_toy)
魔法方法总是被双下划线包围,体现在魔法方法总是在适当的时候被自动调用。
构造器__new__,如果继承一个不可改变的类如,str,这时必须在初始化之前改变它,__new__就是在__init__实例化之前执行的方法。其中cls可以是任何名字,但是用cls是convention。通过对算数魔法方法的重写可以自定义任何对象间的算数运算。
装饰器Decorators
If you wrap some function inside another function which adds some functionality to it and executes the wrapped function, you decorated the wrapped function with the outside function. The outside function is a decorator function. A decorator function takes a function as an argument and it returns a closure.
Decorator can be stacked, if you have two decorator functions, you can just use:
@decorator1
@decorator2
def func(...):
#code
The order of the decorators does matter and can matter. The above code is equivalent to decorator1(decorator2(func)) which is executed from outside to inside.
Use a decorator to build a function to calculate Fibonacci Number Series.
from functools import lru_cache
'''lru_cache is a decorator which can cache the result of a
function, the parameter maxsize can set the maximum number of
items you can cache, the default value is 128, and it's better
to be the exponential of 2'''
@lru_cache(maxsize=32)
def fib(n):
print("calculating...{{{0}}}".format(n)) # use double curly brackets {{}} to print out {}
return 1 if n <= 2 else fib(n-1) + fib(n-2)
# we can also build a caching decorator by ourselves
def memoize_fib(fn):
cache = dict()
def inner(n):
if n not in cache:
cache[n] = fn(n)
return cache[n]
return inner
@memoize_fib
def fib(n):
print("calculating...{{{0}}}".format(n))
return 1 if n <= 2 else fib(n-1) + fib(n-2)
If you want to pass a parameter to the decorator function like @memoize_fib(reps), you can wrap the original decorator function with a new outer function, which has a parameter ‘reps’, then return the original decorator when called.
Any arguments passed to outer can be referenced (as free variables) inside our decorator. We call this outer function a decorator factory(it is a function that creates a new decorator each time it is called).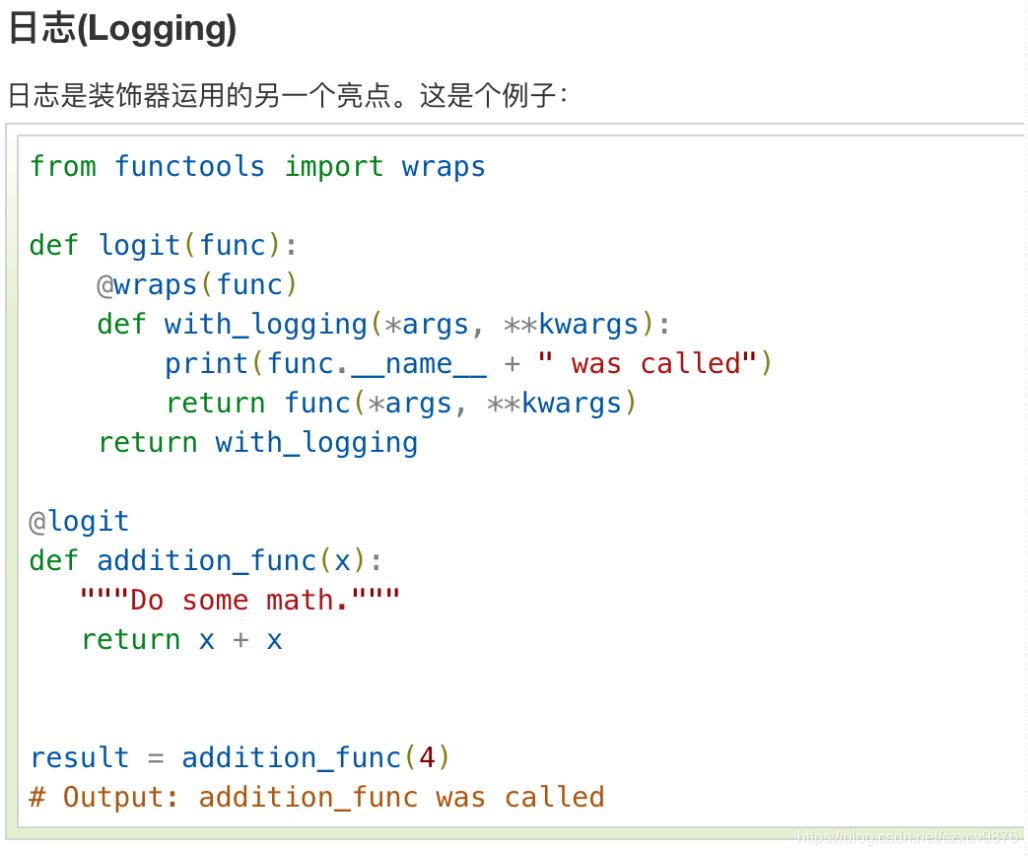
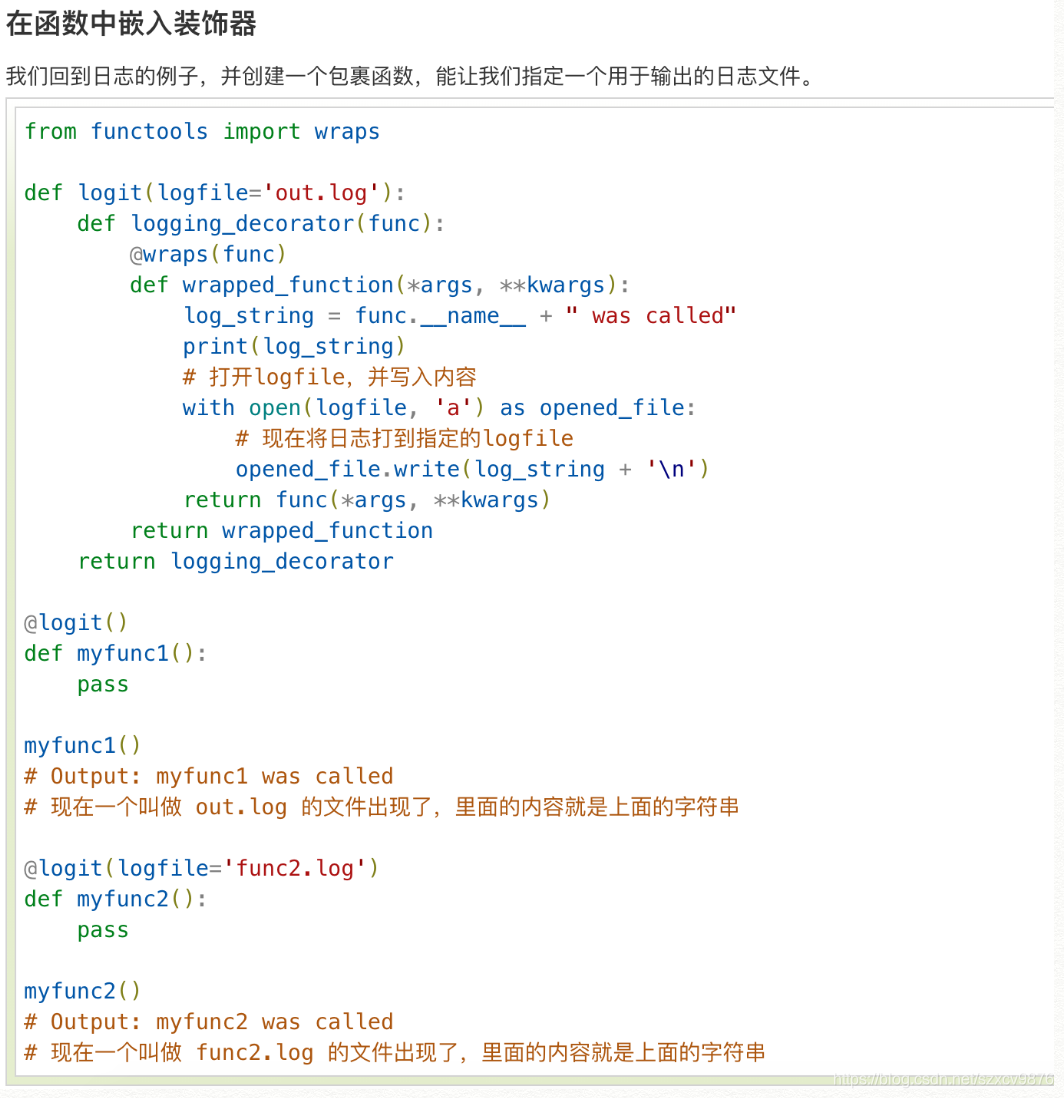
Decorator class
Build a decorator using a class. You can add some parameters in __init__ function, which can act as parameters in decorator factory.
class Memoize_fib:
def __init__(self):
self.cache = dict()
def __call__(self, fn):
def inner(n):
if n not in self.cache:
self.cache[n] = fn(n)
return self.cache[n]
return inner
@Memoize_fib()
def fib(n):
print("calculating...{{{0}}}".format(n))
return 1 if n <= 2 else fib(n-1) + fib(n-2)
Decorating classes
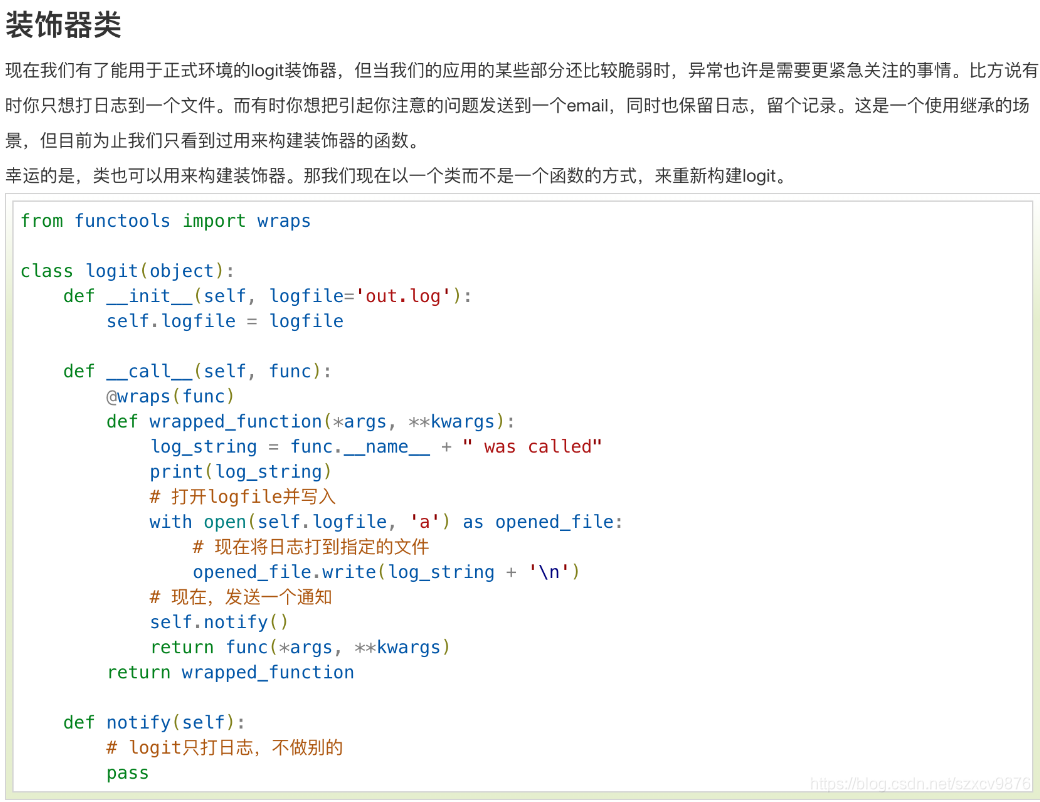
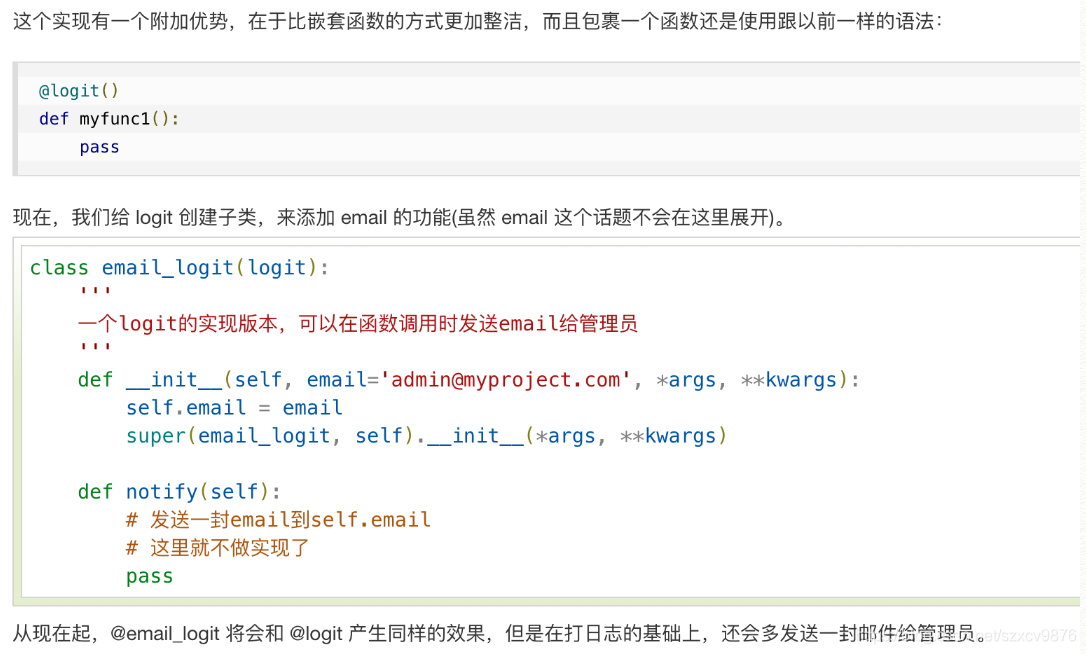
Build a simple debugger for a class by decorator.
from datetime import datetime, timezone
def info(self):
results = []
results.append("time: {0}".format(datetime.now(timezone.utc)))
results.append("Class: {0}".format(self.__class__.__name__))
results.append("id: {0}".format(hex(id(self))))
for k, v in vars(self).items():
results.append("{0}: {1}".format(k, v))
return results
def debug_info(cls):
cls.debug = info
return cls
@debug_info
class People():
def __init__(self, name, age): # __init__ is a method which is called when one instance is created, self is the object it self, it represents the instance created
self.name = name
self.age = age # but here it is calling the setter, the initializing step is finished in the setter
# in python, use property instead of getter and setter to encapasulate variables. the name of the two following function can be the same as attributes name
@property
def age(self):
print("getting")
return self._age
@age.setter
def age(self, new_age):
if new_age <= 0:
raise ValueError("Width must be positive.")
else:
print("setting")
self._age = new_age
>>> p = People("John",5)
>>> p.debug()
['time: 2018-03-31 08:22:51.794910+00:00',
'Class: People',
'id: 0x104e1f780',
'name: John',
'_age: 5']
If you have overridden the operators of “==” and “<”, you can realize other operators like “<=”, “>=”, “!=” by decorating a class. The decorator function is in python standard library. As along you have one comparison in the class, the decorator will complete the others.
from functools import total_ordering
from math import sqrt
@total_ordering
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def __abs__(self):
return sqrt(self.x**2 + self.y**2)
def __eq__(self, other):
if isinstance(other, Point):
return self.x == other.x and self.y == other.y
else:
return False
def __lt__(self, other):
if isinstance(other, Point):
return abs(self) < abs(other)
else:
return NotImplemented
>>> p1, p2, p3 = Point(2,3), Point(3,4), Point(3,4)
>>> p1 >= p2
False
>>> p3 == p2
True
For the usage of single dispatch generic functions from functools import singledispatch, check the python documentation
闭包Closures
# use closure to realize the averager which has the same function of the averager made by using class
# use class
class Averager:
def __init__(self):
self.total = 0
self.count = 0
def add(self, number):
self.total += number
self.count += 1
return self.total / self.count
# use closure
def averager():
total = 0
count = 0
def add(number):
nonlocal total # 这样使得add函数里的total和外部函数中的相同,不再是local变量
nonlocal count
total += number
count += 1
return total / count
return add
# make a timer, class
from time import perf_counter
class Timer:
def __init__(self):
self.start = perf_counter()
def __call__(self): # call the instance of the class will call the __call__ method directly
return perf_counter() - self.start
# closure
def timer():
start = perf_counter()
def poll():
return perf_counter() - start
return poll
# build a counter which counts the called times of the passed function
def counter(fn, counters):
cnt = 0
def call(*args, **kwargs):
nonlocal cnt
cnt += 1
counters[fn.__name__] = cnt
return fn(*args, **kwargs)
return call
def add(a, b):
return a + b
c = dict()
add = counter(add, c)
>>> add(2,3)
5
>>> add(3,3)
6
>>> c
{'add': 2}
六、程序性能
程序运行时间
time
这两种方法包含了所有程序的时间,即从运行start到运行end的时间(没有程序运行也会计算时间)。
start = time.time()
run_func()
end = time.time()
print(end-start)
start = time.clock()
run_fun()
end = time.clock()
print(end-start)
datetime
该方法只计算start和end之间CPU运行的程序的时间,和前面对比。
import datetime
starttime = datetime.datetime.now()
endtime = datetime.datetime.now()
print((endtime - starttime).seconds) # 统计比较长的时间把seconds换成date
七、I/O读写与文件
open方法
参数值:
- ‘r+’ 等价于 rw 可读可写
- ‘w+’ 等价于 wr 可读可写
- ‘a+’ 等价于 ar 可追加可写
对应的二进制文件:'rb', 'wb', 'ab', 'rb+', 'wb+', 'ab+'
r+ Open for reading and writing. The stream is positioned at the beginning of the file.
a+ Open for reading and appending (writing at end of file). The file is created if it does not exist. The output is appended to the end of the file.
file = r'./test.txt'
with open(file, 'a+') as f:
f.write("some text" + "\n")
Remove newline ‘\n’ remark of each line
temp = file_.read().splitlines()
# or
temp = [line[:-1] for line in file_]
# or
temp = line.strip()
递归遍历目录
os.walk(top[, topdown=True[, οnerrοr=None[, followlinks=False]]])
根目录下的每一个文件夹(包含它自己), 产生3-元组 (dirpath, dirnames, filenames)【文件夹路径, 文件夹名字, 文件名】
- topdown 可选,为True或者没有指定, 一个目录的的3-元组将比它的任何子文件夹的3-元组先产生
(目录自上而下)。如果topdown为 False, 一个目录的3-元组将比它的任何子文件夹的3-元组后产生 (目录自下而上) - onerror 可选,是一个函数; 它调用时有一个参数, 一个OSError实例。报告这错误后,继续walk,或者抛出exception终止walk。
- followlinks 设置为true,则通过软链接访问目录。
import os
# 打印所有文件路径, cur_dir表示file_list里的当前文件所在的路径
g = os.walk("/path/to/dir")
for cur_dir, dir_list, file_list in g:
for file_name in file_list:
print(os.path.join(cur_dir, file_name) )
# 打印所有文件夹路径
for cur_dir, dir_list, file_list in g:
for dir_name in dir_list:
print(os.path.join(cur_dir, dir_name))
Concatenate files
filenames = [file1.txt, file2.txt, ...]
with open('path/to/output/file', 'w') as outfile:
for fname in filenames:
with open(fname) as infile:
for line in infile:
outfile.write(line)
import shutil
with open('output_file.txt', 'wb') as wfd:
for f in ['seg1.txt', 'seg2.txt', 'seg3.txt']:
with open(f, 'rb') as fd:
shutil.copyfileobj(fd, wfd)
CSV文件
把二维列表写进csv文件
import csv
list_of_lists = [[1,2,3],[4,5,6],[7,8,9]]
with open("out.csv","w") as f:
writer = csv.writer(f, delimiter=" ") # 设置分隔符,如逗号、空格等
writer.writerows(list_of_lists) # 最后输出格式为二维表格,each sublist is a row.
批量拼接(concatenate)CSV文件
此处代码为收集一个大文件夹的各个子文件夹内的CSV文件,并且拼接成一个大的CSV文件,并且加入了过滤空文件,其他类型文件的功能
import pandas as pd
import glob
import os
files_folder=[]
week = 1
sub_folders = glob.glob('/PATH/*')
for folder in sub_folders:
all_files = []
files = os.listdir(folder)
for file in files:
if file[-3:] == 'csv':
all_files.append(folder +'/' + file)
files_folder.append(all_files)
for folder in files_folder:
tables = []
for file in folder:
if os.path.getsize(file) > 0:
table = pd.read_csv(file)
tables.append(table)
result = pd.concat(tables, ignore_index=True)
for row in range(result.shape[0]):
if str(result.loc[row, 'items']).find(',') == -1:
result = result.drop([row])
result.to_csv('/PATH/merge_week{}.csv'.format(week), index=False)
week += 1
JSON文件
Json data is almost identical to a python dictionary and it is shorter than XML.
>>>import json
>>>json_file = open("/path/to/jsonfile", "r", encoding="utf-8")
>>>loadedJson = json.load(json_file) # json_file can be a string
>>>json_file.close()
#you can access the content by key like
>>>loadedJson["keyName"]
#convert a dictionary to a json string
>>>dic = {"name": "yi", "gender": "male"}
>>>json.dumps(dic)
#write it to a file
>>>file = open("/path/to/store/jsonfile", "w", encoding="utf-8")
>>>json.dump(dic, file)
file.close()
Pickle
The pickle module implements binary protocols for serializing and de-serializing a Python object structure. “Pickling” is the process whereby a Python object hierarchy is converted into a byte stream, and “unpickling” is the inverse operation, whereby a byte stream (from a binary file or bytes-like object) is converted back into an object hierarchy.
The following types can be pickled:
- None, True, and False
- integers, floating point numbers, complex numbers
- strings, bytes, bytearrays
- tuples, lists, sets, and dictionaries containing only picklable objects
- functions defined at the top level of a module (using def, not lambda)
- built-in functions defined at the top level of a module
- classes that are defined at the top level of a module
- instances of such classes whose
__dict__or the result of calling__getstate__()is picklable
import pickle
# To store a list
with open('outfile', 'wb') as fp:
pickle.dump(itemlist, fp)
# To read it back:
with open ('outfile', 'rb') as fp:
itemlist = pickle.load(fp)
# To store a dictionary
import pickle
# An arbitrary collection of objects supported by pickle.
data = {
'a': [1, 2.0, 3, 4+6j],
'b': ("character string", b"byte string"),
'c': {None, True, False}
}
with open('data.pickle', 'wb') as f:
# Pickle the 'data' dictionary using the highest protocol available.
pickle.dump(data, f, pickle.HIGHEST_PROTOCOL)
# To read it back:
with open('data.pickle', 'rb') as f:
# The protocol version used is detected automatically, so we do not
# have to specify it.
data = pickle.load(f)
八、系统操作
文件
设定连续且不重复的文件夹名,易于日志管理
最简单的办法就是用创建时间区分,即timestamp
import datetime
now = datetime.utcnow().strftime("%Y%m%d%H%M%S")
root_logdir = "/PATH/logs"
logdir = "{}/run-{}".format(root_logdir, now) # 之后就用logdir在loop中命名文件夹就行了
recursively find absolute path of certain file
from pathlib import Path
for filename in Path('src').rglob('*.c'):
print(filename)
创建目录/文件夹
# old method
import os
if not os.path.exists(directory):
os.makedirs(directory)
# new method
# recursively creates the directory and does not raise an
# exception if the directory already exists. If you don't need
# or want the parents to be created, skip the parents argument.
from pathlib import Path
Path("/my/directory").mkdir(parents=True, exist_ok=True)
其他Path类的功能
from pathlib import Path
p = Path(file)
p.cwd() # 获取当前路径,Python程序所在路径,而不是指定文件的当前路径
p.stat() # 获取当前文件的信息
p.exists() # 判断当前路径是否是文件或者文件夹
p.is_dir() # 判断该路径是否是文件夹
p.is_file() # 判断该路径是否是文件
p.iterdir() #当path为文件夹时,通过yield产生path文件夹下的所有文件、文件夹路径的迭代器
p.rename(target) # 当target是string时,重命名文件或文件夹;当target是Path时,重命名并移动文件或文件夹
p.replace(target) # 重命名当前文件或文件夹,如果target所指示的文件或文件夹已存在,则覆盖原文件
p.parent(),p.parents() # parent获取path的上级路径,parents获取path的所有上级路径
p.is_absolute() # 判断path是否是绝对路径
p.rmdir() # 当path为空文件夹的时候,删除该文件夹
p.suffix # 获取path文件后缀
p.match(pattern) # 判断path是否满足pattern
文件运行路径
os.getcwd() 输出起始执行目录,就是在哪个目录运行python命令行,就输出哪个目录的绝对路径
sys.path[0] 输出被初始执行的脚本的所在目录,比如python ./test/test.py,就输出test.py所在的目录的绝对路径
sys.argv[0] 输出第一个参数,就是运行文件本身 ./test/test.py
os.path.split(os.path.realpath(__file__))[0] 输出运行该命令的的python文件的所在的目录的绝对路径,该命令所在的文件的目录不同,输出的绝对路径就不同
工作路径
import inspect
import os
aa = inspect.getfile(inspect.currentframe())
print(aa)
print(os.path.abspath(aa))
print(os.path.dirname(os.path.abspath(aa)))
print(os.path.dirname(os.path.dirname(os.path.abspath(aa))))
输出
c:\users\.spyder-py3\temp.py
c:\users\.spyder-py3\temp.py
c:\users\.spyder-py3
c:\users
九、异常
Assert断言
当assert这个关键字后面的条件为假的时候,程序自动崩溃并抛出AssertionError的异常。
>>> assert 3>4
Traceback (most recent call last):
File "<pyshell#100>", line 1, in <module>
assert 3>4
AssertionError
# assert <condition>,<error message>
>>> assert 2 + 2 == 5, "Houston we've got a problem"
Traceback (most recent call last):
File "<pyshell#105>", line 1, in <module>
assert 2 + 2 == 5, "Houston we've got a problem"
AssertionError: Houston we've got a problem
一般来说我们可以用assert在程序中插入检查点,当需要确保程序中的某个条件一定为真才能让程序正常工作的话,assert就非常有用。(Assert statements are a convenient way to insert debugging assertions into a program)
def avg(marks):
assert len(marks) != 0,"List is empty."
return sum(marks)/len(marks)
mark2 = [55,88,78,90,79]
print("Average of mark2:",avg(mark2))
mark1 = []
print("Average of mark1:",avg(mark1))
# output:
# Average of mark2: 78.0
# AssertionError: List is empty.
十、模块Module
模块是包含所有定义函数和变量的文件,后缀为.py。使用之前要用import引入。os模块,会帮助你在不同的操作系统环境下与文件,目录交互。
Package包
Packages are special modules. Packages can contain modules and packages called sub-packages. If a module is a package, it must have a value set for __path__.
The reason to use packages is that they have the ability to break code up into smaller chunks, make our code:
- easier to write
- easier to test and debug
- easier to read/understand
- easier to document
After you have imported a module, you can easily see if that module is a package by inspecting the __path__ attribute (empty -> module, non-empty -> package). Packages represent a hierarchy of modules/packages, just like books are broken down into chapters, sections, paragraphs, etc. E.g.
- pack1.mod1
- pack1.pack1_1.mod1_1
On a file system we therefore have to use directories for packages. The directory name becomes the package name.
To define a package in our file system, we must:
- create a directory whose name will be the package name
- create a file called
__init__.pyinside that directory
That __init__.py file is what tells Python that the directory is a package as opposed to a standard directory
Pip
pip install -r requirements.txt 安装目录下的requirements.txt中的python包
第三方库
scipy
读取.mat文件
import scipy.io as scio
m = scio.loadmat("/path/to/your/.mat")
# m是字典格式,通过下面查看有哪些key
m.keys()
# 保存python字典到mat文件
scio.savemat(dataNew, {'A':data['A']})
numpy
读取存储
Numpy也可以存储Python的字典
embedding_dict = {1:222,2:333}
np.save("embedding_dict.npy", embedding_dict)
embedding_dict=np.load("embedding_dict.npy")
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- docker compose 部署 grafana + loki + vector 监控kafka消息
- 划重点!解锁2024年数字身份安全6大“关键词”
- 华为网络设备常用命令大全
- 接口 VS 枚举,如何管理常量?
- 【实用干货】通过PMP认证考试的心得分享
- 站在大佬的身旁之Ueditor百度富文本word图片转存问题解决
- MySQL数据库导入100万数据不同方式的性能差异
- unity SqLite读取行和列
- 降低方差的统计方差(其二):重要抽样法
- burpsuite的安装与介绍