01 机器学习与深度学习
源自:《深度学习》(徐立芳/主编? 莫宏伟/副主编)
1.1
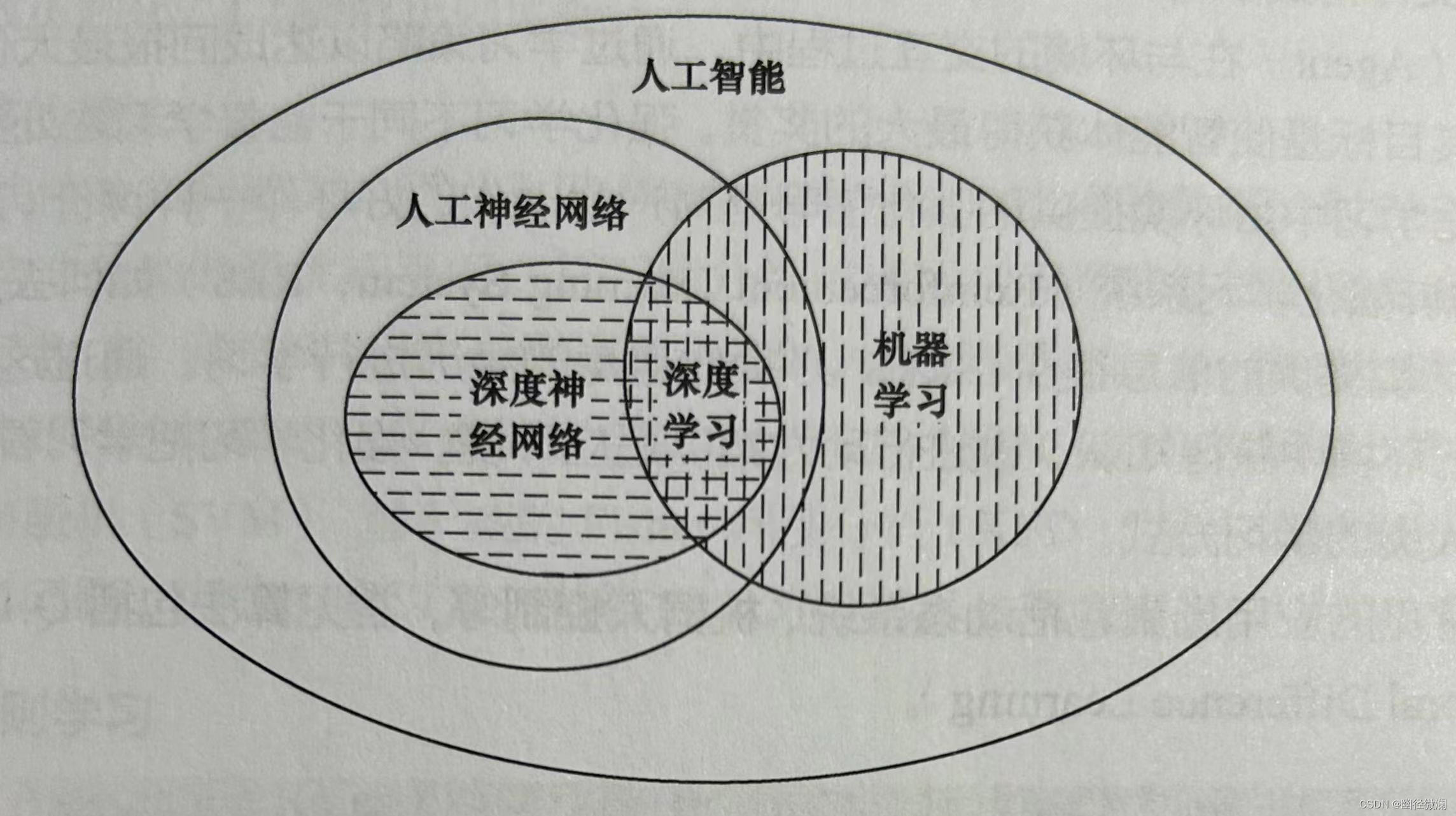
1.2 机器学习方法类型
1.监督式学习
- 每个训练数据集包含输入和正确输出。
- 在分类问题中,就是通过学习带有分类标签的样本,使用模型对未知的样本进行正确分类的过程。
- 常见算法有逻辑回归和反向传播神经网络。
2.无监督式学习
- 训练数据仅包含输入,没有正确输出。
- 通过研究数据的特征和进行数据的处理、分析,获得一个结果。
- 常见算法包括Apriori算法、k-Means算法
3.半监督式学习
- 输入数据部分有标签、部分没标签。
- 可以用来预测,但应先学习数据的内在结构,以便合理组织数据来进行预测。
- 应用场景包括分类和回归。
- 先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。
4.强化学习
- 又称再励学习、评价学习或增强学习,用于描述和解决智能体在与环境的交互过程中,通过学习策略以达成回报最大化或实现特定目标的问题
- 由环境提供的强化信号是对产生动作的好坏做一种评价(通常为标量信号)
- RLS(强化学习系统)必须靠自身的经历进行学习
- RLS在行动—评价的环境中获得知识,改进行动方案以适应环境
1.3 机器学习常见算法
1.贝叶斯算法
在已知某条件概率P(A|B)的情况下,用以下公式求得P(B|A)
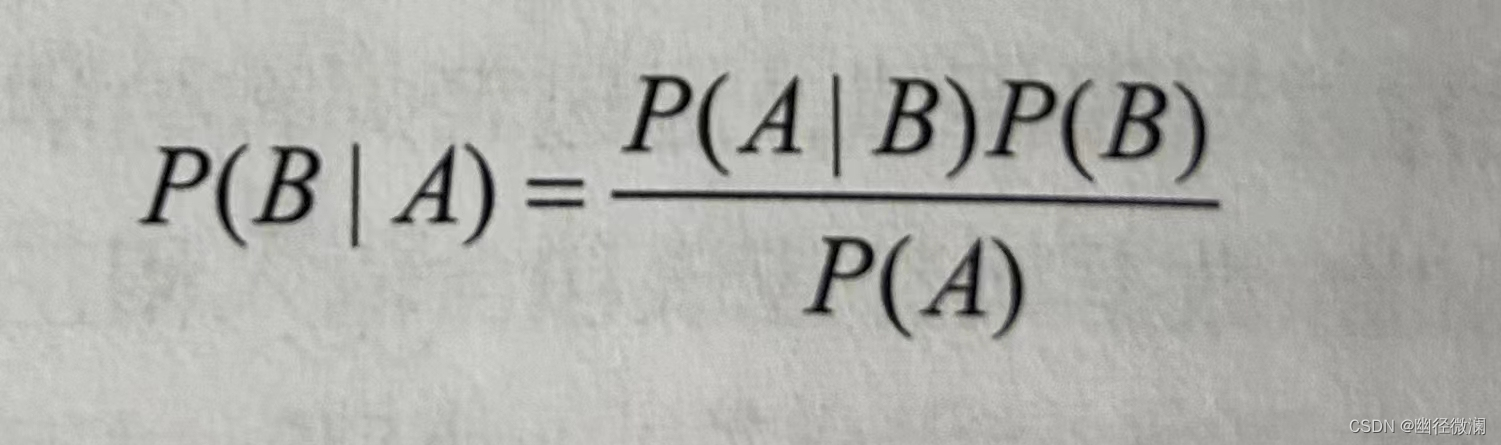
P(A|B)表示事件B发生的前提下,事件A发生的概率。
该算法主要用来解决分类和回归问题。
2.决策树
是一种非参数的监督式学习方法,从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则。
所有的数据最终都会落到叶子节点,既可以做分类也可以做回归。
常见算法:分类及回归树、随机森林、多元自适应回归样条
3.正则化方法
作用:减小测试误差的行为(有时会增加训练误差)。
复杂模型拟合数据容易出现过拟合(训练集表现很好,测试集表现较差),导致模型泛化能力下降,应使用正则化降低模型复杂度。
常见算法:L1参数正则化、L2参数正则化
4.基于核的算法
在处理非线性分类问题时,可以采用非线性映射把输入空间的数据映射到高维特征空间,在特征空间中构造分类的最优超平面,从而使分类或回归问题更容易解决。
存在核函数K,将m维高维空间的内积运算转化为n维低维输入空间的核函数进行计算,解决“维数灾难”问题。
常见算法:支持向量机(SVM)、基于核的Fisher判别分析(KFD)、核主成分分析(KPCA)等。
5.关联规则学习
反映一个事物与其他事物之间的相互依存性和关联性。
常见算法:先验算法、FP-Growth算法(分而治之,递归地划分)、图挖掘(将关联分析用于基于图的数据,在图的集合中有一组公共子结构:频繁子图挖掘)
6.回归算法
统计学中:确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。?
大数据分析中:预测性的建模技术,研究因变量(目标)和自变量(预测器)之间的关系。
7.聚类算法
无监督式学习方法。
将每个数据点划分为一个特定的组。通常按照中心点或分层的方式对输入数据进行归并。
常见算法:k-Means算法、期望最大化算法
8.集成算法
将多个相对较弱的学习模型集成在一起的技术,选择不同子集训练不同分类器,使用投票方式综合各分类器的输出。
包括:随机森林、Bagging方法、Boosting方法
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SECS通讯资料大全 配方处理 recipe上传下载 S7Fx和S7F3、S7F5
- 第一个程序:HelloWorld——IDEA 使用
- node.js常用命令
- 【数据结构】时间复杂度和空间复杂度
- openssl3.2 - 官方demo学习 - pkey - EVP_PKEY_DSA_keygen.c
- vue安装、打包、发布
- 基于 Hologres+Flink 的曹操出行实时数仓建设
- Vagrant Centos 7 环境配置
- 商城小程序(9.登录与支付)
- 计算机网络(超详解!) 第二节 数据链路层(上)